Más sobre ciencia de datos en: cienciadedatos.net
- Regresión lineal con Python
- Regresión lineal múltiple con Python
- Regresión logística con Python
- Regularización Ridge, Lasso y Elastic Net con Python
- Machine learning con Python y Scikitlearn
- Árboles de decisión con Python: regresión y clasificación
- Random Forest con Python y Scikit-learn
- Gradient Boosting con Python y Scikit-learn
- Gradient Boosting probabilístico con Python (NGBoost)
- Gradient Boosting probabilístico con Python (GBMLSS)
- Máquinas de Vector Soporte (SVM)
- Redes neuronales con Python
- Análisis de componentes principales PCA
- Clustering
- Detección de anomalías con PCA
- Detección de anomalías con autoencoders
- Detección de anomalías con Gaussian Mixture Models
- Detección de anomalías con Isolation Forest
- Análisis de texto (text mining) con Python
- Reglas de asociación

Introducción ¶
La mayoría de los modelos de machine learning supervisado aplicados a problemas de regresión generan una estimación puntual de la variable objetivo $y$ dado un conjunto de predictores $\mathbf{X}$. Esta estimación corresponde típicamente a la media condicional $\mathbb{E}[y \mid \mathbf{X}]$. Si bien es perfectamente adecuada para muchas tareas, las predicciones puntuales tienen una limitación fundamental: no dicen nada sobre la incertidumbre que rodea al valor predicho.
Imaginemos una empresa que gestiona la distribución de electricidad. La red debe dimensionarse para manejar el pico de demanda, no la demanda media. Saber que el consumo esperado a las 10 de la mañana es de 15 MWh es útil, pero saber que hay un 5% de probabilidad de que supere los 22,5 MWh es mucho más valioso para la planificación de capacidad. Un modelo de regresión estándar no puede responder a la segunda pregunta.
Más formalmente, los modelos de estimación puntual no proporcionan:
- Intervalos de predicción: un rango $[L, U]$ que cubre el valor verdadero con una probabilidad dada, p. ej., $P(L \leq y \leq U \mid \mathbf{X}) = 0.90$.
- Predicciones de probabilidad: $P(y > c \mid \mathbf{X})$ para un umbral arbitrario $c$.
- Distribución condicional completa $p(y \mid \mathbf{X})$, que contiene toda la información sobre la variable respuesta.
La regresión distribucional aborda estas limitaciones modelando la distribución condicional completa de $y$ en lugar de solo su media. La salida del modelo ya no es un único número, sino los parámetros de una distribución de probabilidad paramétrica; por ejemplo, la media $\mu$ y la desviación típica $\sigma$ de una distribución Normal, ambas como funciones de $\mathbf{X}$.
Gradient Boosting Machines para Posición, Escala y Forma (GBM-LSS) extiende el marco de gradient boosting a la regresión distribucional. En lugar de ajustar un único modelo de boosting a la media condicional, GBM-LSS ajusta un modelo de gradient boosting por parámetro distribucional, guiando a cada uno hacia la estimación de máxima verosimilitud de la distribución completa. El resultado es un modelo flexible y no paramétrico para toda la distribución condicional $p(y \mid \mathbf{X})$.
Este enfoque hereda todas las fortalezas del gradient boosting moderno —manejo de relaciones no lineales, robustez frente a valores atípicos (con distribuciones adecuadas), compatibilidad con datos tabulares heterogéneos, selección de variables incorporada mediante regularización— al tiempo que extiende sus predicciones de un único número a una distribución de probabilidad completa.
Este artículo cubre los fundamentos conceptuales, una comparación con enfoques probabilísticos alternativos, la API práctica de Python y dos ejemplos trabajados: uno con datos simulados de verdad conocida, y otro con un conjunto de datos pediátrico de crecimiento real.
💡 Tip
Este docuemento forma parte de una serie sobre machine learning probabilístico.
Gradient boosting distribucional: GBM-LSS¶
El gradient boosting estándar para regresión entrena un único conjunto de árboles que mapea las características $\mathbf{X}$ a una predicción de la media condicional $\mathbb{E}[y \mid \mathbf{X}]$. Se trata fundamentalmente de una predicción puntual: un número por observación.
GBM-LSS extiende esta idea de modo que la salida del modelo no sea un número sino una distribución de probabilidad completa. Para ello, se apoya en el concepto de regresión distribucional: en lugar de modelar únicamente el valor esperado de $y$, modela todos los parámetros de una distribución paramétrica elegida como funciones de los predictores. Para una distribución Normal, eso significa modelar tanto la media $\mu(\mathbf{X})$ como la desviación típica $\sigma(\mathbf{X})$. Para una distribución Gamma, significa modelar los parámetros de forma y tasa. Cada uno de esos parámetros obtiene su propio conjunto de gradient boosting, entrenados conjuntamente para maximizar la verosimilitud de los datos observados.
El nombre Posición, Escala y Forma proviene de la convención de nomenclatura genérica utilizada en el marco GAMLSS (Rigby & Stasinopoulos, 2005), que este enfoque extiende directamente al gradient boosting con árboles. Posición se refiere a dónde está centrada la distribución ($\mu$), escala a cuán dispersa está ($\sigma$), y forma a la asimetría y el comportamiento en las colas ($\nu$, $\tau$). No todas las distribuciones requieren los cuatro parámetros —una distribución Normal solo necesita posición y escala—, pero el marco admite hasta cuatro parámetros modelados de forma independiente. La consecuencia práctica es que el modelo puede capturar heterocedasticidad (varianza que cambia con los predictores), asimetría variable y peso variable en las colas, ninguno de los cuales puede representar el GBM estándar.
Las dos implementaciones en Python que se cubren en este artículo son XGBoostLSS y LightGBMLSS, ambas escritas y mantenidas por Alexander März. Envuelven XGBoost y LightGBM respectivamente, extendiéndolos con regresión distribucional mientras mantienen la misma API de entrenamiento familiar.
Cómo funciona GBM-LSS¶
Parámetros de Posición, Escala y Forma
Cualquier distribución paramétrica continua puede caracterizarse por sus parámetros. El marco GBM-LSS utiliza la notación genérica $(\mu, \sigma, \nu, \tau)$ para hasta cuatro parámetros, que se corresponden aproximadamente con:
| Parámetro | Rol | Ejemplo |
|---|---|---|
| $\mu$ (Posición) | Dónde está centrada la distribución | Media de la Normal, mediana de la Laplace |
| $\sigma$ (Escala) | Cuán dispersa está la distribución | Desv. típica de la Normal, escala de la Gamma |
| $\nu$ (Forma 1) | Asimetría / sesgo | Grados de libertad de la t de Student |
| $\tau$ (Forma 2) | Peso en las colas / curtosis | Segundo parámetro de forma en distribuciones de cuatro parámetros |
No todas las distribuciones requieren los cuatro parámetros. Una distribución Normal solo necesita $(\mu, \sigma)$; una t de Student necesita $(\mu, \sigma, \nu)$; las distribuciones de cuatro parámetros rara vez son necesarias en la práctica. En la regresión estándar, solo $\mu$ se modela como función de $\mathbf{X}$, y el resto de parámetros se estiman como constantes globales. GBM-LSS modela todos los parámetros distribucionales como funciones de $\mathbf{X}$:
$$\hat{\theta}_k(\mathbf{X}) = h_k^{-1}(F_k(\mathbf{X}))$$donde $h_k$ es una función de enlace que mapea la salida sin restricciones del modelo de boosting al rango válido del parámetro $k$, y $F_k$ es un conjunto de gradient boosting.
El objetivo de entrenamiento: log-verosimilitud negativa
En el gradient boosting estándar para regresión, el modelo minimiza el error cuadrático esperado o la pérdida MAE. En GBM-LSS, la pérdida es la log-verosimilitud negativa de la distribución asumida:
$$\mathcal{L}(\mathbf{F}) = -\sum_{i=1}^{n} \log p\!\left(y_i \mid \boldsymbol{\theta}(\mathbf{X}_i)\right)$$donde $\mathbf{F} = (F_1, \ldots, F_K)$ es el vector de modelos GBM, uno por parámetro distribucional, y $K$ es el número de parámetros en la distribución elegida. Minimizar esta pérdida es equivalente a la estimación de máxima verosimilitud de todos los parámetros distribucionales simultáneamente.
El gradient boosting se aplica a este objetivo: en cada iteración $t$, se añade un nuevo árbol al modelo para cada parámetro $k$ ajustando el gradiente negativo (y la Hessiana) de $\mathcal{L}$ con respecto a la predicción actual:
$$r_{i,k}^{(t)} = -\left[\frac{\partial \log p(y_i \mid \boldsymbol{\theta})}{\partial F_k(\mathbf{X}_i)}\right]_{F_k = F_k^{(t-1)}}$$Para calcular estas derivadas de forma eficiente, marcos como lightgbmlss aprovechan las capacidades de diferenciación automática de PyTorch. Esto significa que los gradientes y las Hessianas se estiman simultáneamente para todos los parámetros de forma automática, permitiendo a los usuarios implementar fácilmente distribuciones personalizadas sin necesidad de derivar analíticamente derivadas complejas.
El resultado son $K$ conjuntos de gradient boosting entrenados conjuntamente, cada uno responsable de predecir un parámetro distribucional como función no lineal de los predictores.
Una función de pérdida alternativa soportada por la librería es el Continuous Ranked Probability Score (CRPS) (loss_fn="crps"). El CRPS es una regla de puntuación propia que generaliza el MAE a predicciones probabilísticas y tiene las mismas unidades que $y$. A diferencia de la NLL, el CRPS no requiere especificar una familia distribucional: evalúa la calidad de la predicción comparando la CDF predicha $F$ con el resultado observado $y$:
En la práctica, loss_fn="nll" (el valor por defecto) es la opción más habitual; loss_fn="crps" puede ser útil cuando la robustez frente a la mala especificación distribucional es prioritaria.
Algoritmo de entrenamiento
El algoritmo de entrenamiento de GBM-LSS es el siguiente:
Inicializar cada modelo de parámetro $F_k^{(0)}$ con la estimación MLE de $\theta_k$ en el conjunto de entrenamiento (una constante por parámetro que maximiza la verosimilitud incondicional).
Para cada iteración de boosting $t = 1, \ldots, T$:
- Calcular el gradiente negativo (pseudo-residuos) para cada parámetro $k$.
- Ajustar un nuevo árbol de regresión $h_k^{(t)}$ a los pseudo-residuos del parámetro $k$.
- Actualizar $F_k^{(t)} = F_k^{(t-1)} + \eta \cdot h_k^{(t)}$, donde $\eta$ es la tasa de aprendizaje.
- Aplicar la función de enlace para mapear la predicción bruta al espacio válido del parámetro.
Devolver el conjunto final $\mathbf{F} = (F_1, \ldots, F_K)$.
Tras el entrenamiento, la predicción para una nueva observación $\mathbf{X}^*$ es la distribución personalizada:
$$\hat{\boldsymbol{\theta}}(\mathbf{X}^*) = \left(h_1^{-1}(F_1(\mathbf{X}^*)),\ \ldots,\ h_K^{-1}(F_K(\mathbf{X}^*))\right)$$Cada observación recibe su propia distribución $p(y \mid \hat{\boldsymbol{\theta}}(\mathbf{X}^*))$ en lugar de una estimación puntual.
Funciones de enlace
Las funciones de enlace garantizan que la salida bruta sin restricciones del GBM se mapee a un valor en el dominio válido de cada parámetro distribucional:
| Dominio del parámetro | Función de enlace | Enlace inverso | Uso típico |
|---|---|---|---|
| $\mathbb{R}$ (sin restricciones) | Identidad: $g(\theta) = \theta$ | $\theta = F$ | Media de la Normal o Laplace |
| $(0, \infty)$ (estrictamente positivo) | Log: $g(\theta) = \log(\theta)$ | $\theta = e^F$ | Parámetros de escala, forma Gamma |
| $(0, 1)$ (probabilidad) | Logit: $g(\theta) = \log\frac{\theta}{1-\theta}$ | $\theta = \sigma(F)$ | Probabilidad de inflado de ceros |
Por ejemplo, al ajustar una distribución Normal, la media $\mu$ usa el enlace identidad (cualquier número real es válido), y la desviación típica $\sigma$ usa el enlace logarítmico (debe ser estrictamente positiva). La librería gestiona la aplicación de las funciones de enlace automáticamente; el usuario solo necesita elegir la familia distribucional.
Distribuciones disponibles¶
Una de las decisiones de modelado más relevantes es la elección de la familia distribucional. GBM-LSS admite una amplia gama de distribuciones paramétricas. A continuación se presenta una guía práctica organizada por el tipo de variable respuesta.
Distribuciones continuas simétricas
| Distribución | Parámetros | Caso de uso |
|---|---|---|
| Normal | $\mu \in \mathbb{R}$, $\sigma > 0$ | Datos continuos, errores aproximadamente simétricos; elección base |
| t de Student | $\mu \in \mathbb{R}$, $\sigma > 0$, $\nu > 0$ | Datos con colas pesadas, robusta frente a valores atípicos; generaliza la Normal |
| Laplace | $\mu \in \mathbb{R}$, $\sigma > 0$ | Colas más pesadas que la Normal (decaimiento exponencial), pico agudo en la moda; análoga a la pérdida L1 |
| Logística | $\mu \in \mathbb{R}$, $\sigma > 0$ | Colas ligeramente más pesadas que la Normal |
La distribución t de Student es especialmente valiosa en la práctica. Cuando el parámetro de grados de libertad $\nu$ es grande, se aproxima a una distribución Normal; a medida que $\nu$ disminuye, las colas se vuelven más pesadas. Esto proporciona robustez frente a valores atípicos sin necesidad de que el analista especifique umbrales de atípicos con antelación.
Distribuciones continuas asimétricas (dominio positivo)
| Distribución | Parámetros | Caso de uso |
|---|---|---|
| LogNormal | $\mu \in \mathbb{R}$, $\sigma > 0$ | Datos positivos con sesgo derecho; ingresos, precios |
| Gamma | $\mu > 0$, $\sigma > 0$ | Datos positivos; reclamaciones de seguros, tiempos de espera |
| Beta | $\mu \in (0,1)$, $\sigma > 0$ | Proporciones y tasas acotadas en $(0, 1)$ |
| Weibull | $\mu > 0$, $\sigma > 0$ | Tiempos de fallo y supervivencia |
| Gumbel | $\mu \in \mathbb{R}$, $\sigma > 0$ | Valores extremos, niveles de retorno |
Datos discretos y de recuento
| Distribución | Parámetros | Caso de uso |
|---|---|---|
| Poisson | $\mu > 0$ | Datos de recuento; asume media = varianza |
| Binomial Negativa | $\mu > 0$, $\sigma > 0$ | Datos de recuento sobredispersos (varianza > media) |
| Poisson Inflada en Cero (ZIP) | $\mu > 0$, $\pi \in (0,1)$ | Recuentos con exceso de ceros |
| Binomial Negativa Inflada en Cero (ZINB) | $\mu > 0$, $\sigma > 0$, $\pi$ | Recuentos sobredispersos con exceso de ceros |
Modelado distribucional avanzado (Multivariante, Mezclas y Flujos)
Más allá de las distribuciones univariantes estándar, el marco GBM-LSS es lo suficientemente genérico para manejar escenarios de modelado muy complejos:
- Objetivos multivariantes: predicción de respuestas de dimensión $D$ simultáneamente (p. ej., Gaussiana o t de Student multivariante) modelando no solo las medias y varianzas, sino también las matrices de covarianza (usando, por ejemplo, descomposición de Cholesky o aproximaciones de bajo rango) como función de los predictores.
- Distribuciones de mezcla: aproximación de datos multimodales combinando múltiples distribuciones componente (p. ej., una Mezcla Gaussiana donde los pesos, medias y varianzas de cada componente dependen de las covariables).
- Normalizing Flows: para distribuciones extremadamente complejas y no paramétricas, el marco admite Normalizing Flows (como Neural Spline Flows) que aplican transformaciones biyectivas para convertir una distribución base simple en una distribución objetivo realista.
Cómo elegir la distribución adecuada
Conocimiento del dominio: comience con las restricciones que debe satisfacer la variable respuesta:
- ¿Es $y$ estrictamente positiva? → Gamma, LogNormal, Weibull
- ¿Está $y$ acotada en $[0, 1]$? → Beta
- ¿Es $y$ un número entero (recuento)? → Poisson, Binomial Negativa
- ¿Tiene $y$ masa puntual en cero pero es de otro modo continua? → distribuciones Ajustadas en Cero (ZAGamma, ZALN, ZABeta)
Análisis exploratorio de datos: visualice la distribución marginal de $y$:
- Simétrica, con forma de campana → Normal, t de Student
- Sesgada a la derecha, estrictamente positiva → LogNormal, Gamma
- Colas pesadas en ambos lados → t de Student
- Pico agudo → Laplace
Selección automática (lightgbmlss): la librería lightgbmlss proporciona una función auxiliar dist_select (a través de DistributionClass) que ajusta cada distribución candidata a la variable objetivo por máxima verosimilitud y las devuelve ordenadas por log-verosimilitud negativa (NLL). La distribución con la NLL más baja es la que mejor explica los datos observados. La función también representa la densidad de la variable objetivo junto con las densidades ajustadas de todos los candidatos.
Diagnósticos de residuos: tras ajustar un modelo candidato, inspeccione el histograma PIT (Transformada Integral de Probabilidad), la distribución de $F(y_i \mid \hat{\boldsymbol{\theta}}_i)$ en el conjunto de test. Un modelo bien calibrado produce un histograma plano; las desviaciones indican mala especificación:
- Forma de U → colas demasiado ligeras (el modelo es demasiado confiado)
- Forma de montículo → colas demasiado pesadas (el modelo es demasiado conservador)
- Sesgado → la asimetría de la distribución está mal especificada
GBM-LSS frente a otros enfoques probabilísticos¶
Existen varios enfoques para la regresión distribucional o probabilística disponibles en Python. Comprender sus ventajas e inconvenientes de antemano ayuda a motivar la elección de GBM-LSS.
GBM-LSS vs Regresión por Cuantiles
| Aspecto | Regresión por Cuantiles | GBM-LSS |
|---|---|---|
| Salida | Cuantiles específicos | Distribución paramétrica completa |
| Supuesto distribucional | Ninguno (no paramétrico) | Paramétrico (se debe elegir la distribución) |
| $P(y > c \mid \mathbf{X})$ para $c$ arbitrario | Requiere interpolación | Exacto, desde la CDF |
| Cruce de cuantiles | Posible | Imposible (coherencia paramétrica) |
| Número de modelos entrenados | Uno por cuantil | Uno por parámetro distribucional |
| Captura heterocedasticidad | Sí | Sí |
| Captura asimetría variable | Parcialmente | Sí |
Elija Regresión por Cuantiles cuando ninguna distribución paramétrica sea una suposición razonable (p. ej., respuestas multimodales o con forma de mezcla), o cuando solo se necesite un conjunto fijo de niveles de cuantil.
Elija GBM-LSS cuando una familia paramétrica sea plausible y desee una descripción distribucional completamente coherente que permita calcular cualquier cuantil, cualquier probabilidad de cola y cualquier momento sin entrenar modelos separados.
GBM-LSS vs NGBoost
| Aspecto | NGBoost | GBM-LSS |
|---|---|---|
| Optimización | Gradiente natural (escalado por información de Fisher) | Gradiente estándar (pérdida NLL) |
| Backend GBDT | Personalizado (librería ngboost) | XGBoost / LightGBM (optimizado) |
| Velocidad | Más lento | Más rápido (especialmente en conjuntos de datos grandes) |
| Familias distribucionales | Limitadas (~5) | Extensas (30+) |
| Importancia de variables | Importancia estándar por árbol | SHAP por parámetro distribucional |
| Desarrollo activo | Más lento (a partir de 2026) | Activo |
En la práctica, GBM-LSS supera a NGBoost en conjuntos de datos tabulares grandes en velocidad y precisión distribucional, gracias a los backends altamente optimizados de XGBoost y LightGBM. La actualización por gradiente natural de NGBoost puede ser ventajosa cuando la superficie de verosimilitud está mal condicionada, pero esto rara vez resulta decisivo en la práctica.
Resumen de recomendaciones
| Situación | Enfoque recomendado |
|---|---|
| Línea base rápida, solo unos pocos niveles de cuantil | Regresión por cuantiles (GBM con pérdida pinball) |
| Conjunto de datos pequeño, inferencia estadística con coeficientes | GAMLSS (R) o NGBoost |
| Conjunto de datos tabular grande, familia paramétrica conocida | GBM-LSS (XGBoostLSS / LightGBMLSS) |
| Forma distribucional desconocida o compleja | Regresión por cuantiles o normalizing flows |
| Se requiere inferencia bayesiana completa | PyMC o Stan |
Ejemplo 1: Datos simulados heteroscedásticos¶
El primer ejemplo utiliza datos simulados donde la varianza de la variable respuesta cambia en función del predictor. Este es un caso canónico donde la regresión estándar falla y el modelado distribucional muestra su valor.
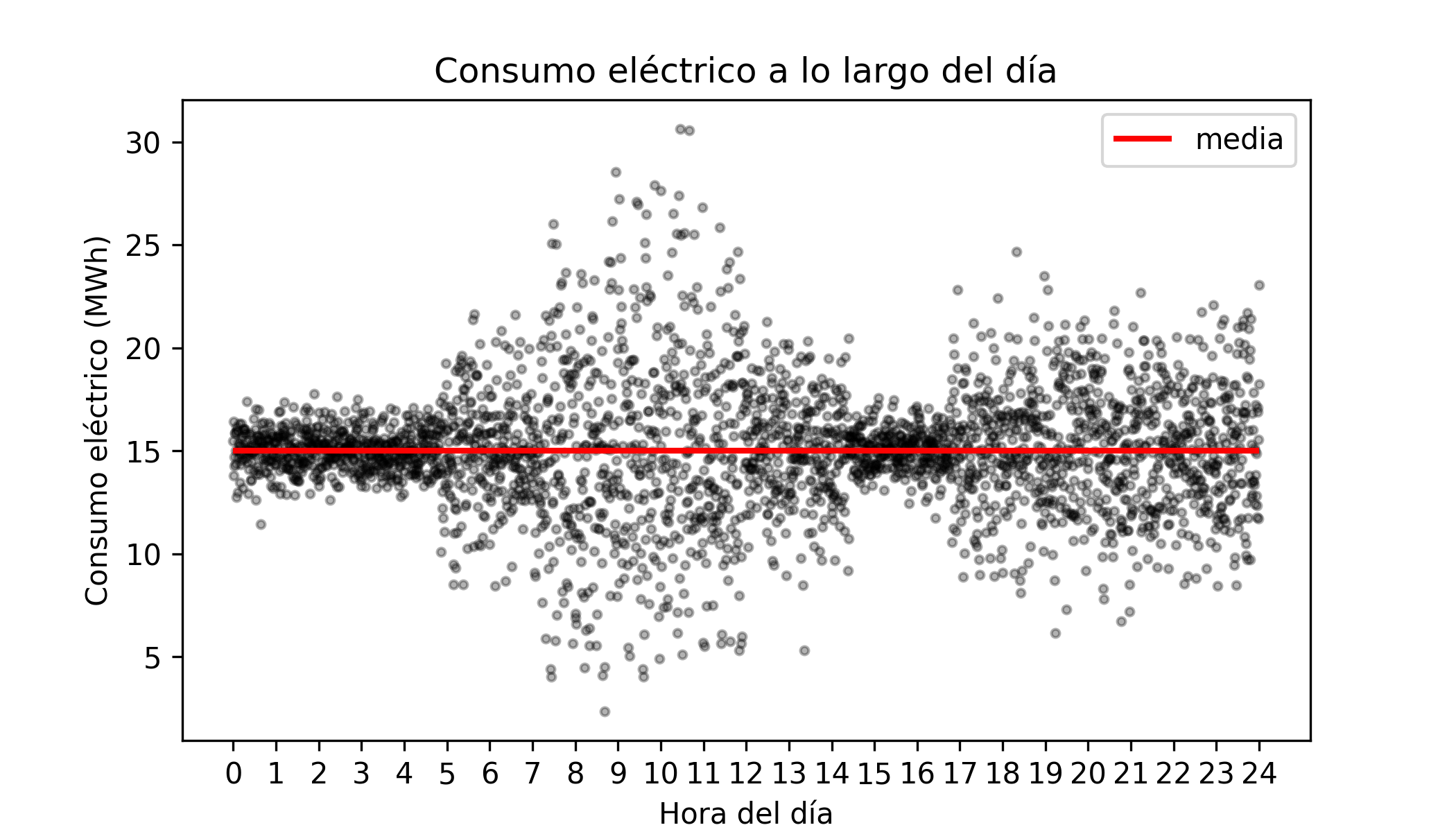
Descripción del problema: Una empresa de servicios públicos monitorea el consumo horario de electricidad en miles de hogares. El consumo medio es aproximadamente constante a lo largo del día (~15 MWh), pero la variabilidad no lo es: el consumo está muy concentrado durante la noche y muy disperso durante las horas pico de la mañana y la tarde. La empresa desea:
- Predecir la distribución completa del consumo para cada hora.
- Calcular intervalos de predicción con cobertura del 90%.
- Estimar la probabilidad de que el consumo supere un umbral en cada hora.
Librerías y datos¶
# Librerías
# ==============================================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import lightgbm as lgb
from lightgbmlss.model import LightGBMLSS
from lightgbmlss.distributions.Gaussian import Gaussian
import lightgbmlss.distributions.Gaussian as Gaussian_mod
import lightgbmlss.distributions.StudentT as StudentT_mod
import lightgbmlss.distributions.Gamma as Gamma_mod
import lightgbmlss.distributions.LogNormal as LogNormal_mod
from sklearn.model_selection import train_test_split
from scipy import stats
import warnings
warnings.filterwarnings('once')
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
✏️ Nota
Los usuarios pueden cambiar del modelo basado en LightGBM al modelo basado en XGBoost simplemente sustituyendo lightgbmlss por xgboostlss.
# Datos simulados
# ==============================================================================
# Simulación ligeramente modificada del ejemplo publicado en
# XGBoostLSS - An extension of XGBoost to probabilistic forecasting Alexander März
np.random.seed(1234)
n = 3000
X = np.linspace(0, 24, n)
y = np.random.normal(
loc=15,
scale=(
1
+ 1.5 * ((4.8 < X) & (X < 7.2))
+ 4.0 * ((7.2 < X) & (X < 12.0))
+ 1.5 * ((12.0 < X) & (X < 14.4))
+ 2.0 * (X > 16.8)
)
)
Los datos se generan a partir de $\mathcal{N}(15, \sigma^2(t))$ donde $\sigma(t)$ varía con la hora del día. El GBM estándar captura bien la media constante, pero no puede representar la varianza cambiante.
# Calcular los cuantiles 0.1 y 0.9 para cada valor simulado de X
# ==============================================================================
cuantil_10 = stats.norm.ppf(
q = 0.1,
loc = 15,
scale = (
1 + 1.5 * ((4.8 < X) & (X < 7.2)) + 4 * ((7.2 < X) & (X < 12))
+ 1.5 * ((12 < X) & (X < 14.4)) + 2 * (X > 16.8)
)
)
cuantil_90 = stats.norm.ppf(
q = 0.9,
loc = 15,
scale = (
1 + 1.5 * ((4.8 < X) & (X < 7.2)) + 4 * ((7.2 < X) & (X < 12))
+ 1.5 * ((12 < X) & (X < 14.4)) + 2 * (X > 16.8)
)
)
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(figsize=(7, 3.5))
ax.scatter(X, y, alpha = 0.3, c = "black", s = 8)
ax.hlines(y=15, xmin=0, xmax=24, colors='tomato', lw=2, label='Media real (15 MWh)')
ax.plot(X, cuantil_10, c = "black")
ax.plot(X, cuantil_90, c = "black")
ax.fill_between(
X, cuantil_10, cuantil_90, alpha=0.3, color='red',
label='Intervalo de cuantiles teórico 0.1-0.9'
)
ax.set_xlabel('Hora del día')
ax.set_ylabel('Consumo (MWh)')
ax.set_title('Consumo eléctrico por hora')
ax.set_xticks(range(0, 25, 2))
ax.legend()
plt.tight_layout()

Entrenamiento del modelo¶
# División entrenamiento-test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
X.reshape(-1, 1), y, test_size=0.2, random_state=42, shuffle=True
)
# Con XGBoostLSS los datos deben transformarse a xgb.DMatrix
# dX_train = xgb.DMatrix(X_train, label=y_train)
# dX_test = xgb.DMatrix(X_test, label=y_test)
# Con LightGBMLSS los datos deben transformarse a lgb.Dataset
dX_train = lgb.Dataset(X_train, label=y_train)
dX_test = lgb.Dataset(X_test, label=y_test)
print(f"Conjunto de entrenamiento: {X_train.shape[0]} muestras")
print(f"Conjunto de test: {X_test.shape[0]} muestras")
Conjunto de entrenamiento: 2400 muestras Conjunto de test: 600 muestras
Al ajustar el modelo GBM-LSS es necesario especificar una familia distribucional. Cada clase de distribución acepta tres argumentos clave:
- stabilization : "None" | "MAD" | "L2" — método de estabilización del gradiente/Hessiana
- response_fn : "exp" | "softplus" — enlace inverso para parámetros positivos (p. ej., escala)
- loss_fn : "nll" | "crps" — función de pérdida de entrenamiento (log-verosimilitud negativa o CRPS)
En este caso se elige la distribución Normal, que tiene dos parámetros: $\mu$ (media) y $\sigma$ (desviación típica). La media se modela con el enlace identidad y la desviación típica con el enlace logarítmico para garantizar la positividad. El objetivo de entrenamiento es la log-verosimilitud negativa de la distribución Normal.
# Especificación del modelo
# ==============================================================================
modelo = LightGBMLSS(
Gaussian(stabilization="None", response_fn="exp", loss_fn="nll")
)
Para encontrar los hiperparámetros óptimos se realiza una búsqueda bayesiana mediante la integración con Optuna proporcionada por la librería. La búsqueda optimiza la log-verosimilitud negativa de validación sobre un espacio de hiperparámetros predefinido, usando parada temprana para evitar el sobreajuste. Luego se reajusta el mejor modelo en el conjunto de entrenamiento completo con los hiperparámetros óptimos.
# Optimización de hiperparámetros
# ==============================================================================
# !pip install optuna-integration[lightgbm]\n
espacio_hiperparametros = {
"learning_rate": ["float", {"low": 1e-5, "high": 1, "log": True}],
"max_depth": ["int", {"low": 1, "high": 10, "log": False}],
"min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": False}],
"min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
"subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
"feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
"boosting": ["categorical", ["gbdt"]],
}
mejores_hiperparametros = modelo.hyper_opt(
hp_dict = espacio_hiperparametros,
train_set = dX_train,
num_boost_round=100, # Número de iteraciones de boosting.
nfold=5, # Número de folds para validación cruzada.
early_stopping_rounds=20, # Número de rondas de parada temprana.
max_minutes=10, # Presupuesto de tiempo en minutos.
n_trials=30, # Número de ensayos de búsqueda.
silence=True, # Controla la verbosidad de los ensayos.
seed=123, # Semilla para generar los folds de cv.
hp_seed=6715 # Semilla para el generador de números aleatorios en la búsqueda bayesiana.
)
0%| | 0/30 [00:00<?, ?it/s]
Hyper-Parameter Optimization successfully finished.
Number of finished trials: 30
Best trial:
Value: 2.265606331242457
Params:
learning_rate: 0.9273640481563128
max_depth: 1
min_gain_to_split: 0.035986405436204016
min_sum_hessian_in_leaf: 0.025909830444300425
subsample: 0.7788823527111574
feature_fraction: 0.6019028154022705
boosting: gbdt
opt_rounds: 31
El modelo se entrena con los mejores hiperparámetros encontrados en la búsqueda.
# Entrenar el modelo con los hiperparámetros óptimos
# ==============================================================================
n_rondas = mejores_hiperparametros.pop("opt_rounds")
modelo.train(
params = mejores_hiperparametros,
train_set = dX_train,
num_boost_round = n_rondas
)
Predicciones¶
lightgbmlss ofrece tres opciones distintas para realizar predicciones:
samples: extrae $n$ muestras de la distribución predicha.quantiles: calcula cuantiles de la distribución predicha.parameters: devuelve los parámetros distribucionales predichos.
Cuando se usa el tipo de predicción samples, la salida es un DataFrame con una fila por observación del conjunto de test y n_samples columnas, cada una conteniendo una extracción de la distribución predicha para esa observación. Estas representan posibles resultados futuros consistentes con la incertidumbre del modelo.
# Muestreo desde la distribución predicha
# ==============================================================================
predicciones_muestras = modelo.predict(data=X_test, pred_type="samples", n_samples=50)
predicciones_muestras
| y_sample0 | y_sample1 | y_sample2 | y_sample3 | y_sample4 | y_sample5 | y_sample6 | y_sample7 | y_sample8 | y_sample9 | ... | y_sample40 | y_sample41 | y_sample42 | y_sample43 | y_sample44 | y_sample45 | y_sample46 | y_sample47 | y_sample48 | y_sample49 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 15.697314 | 16.262325 | 16.202932 | 15.307989 | 17.619083 | 13.853810 | 15.308901 | 12.309548 | 15.882831 | 19.780371 | ... | 17.041090 | 16.348074 | 14.840222 | 11.370354 | 12.450369 | 13.575173 | 13.577733 | 16.836323 | 13.708682 | 18.007421 |
| 1 | 14.166789 | 18.025551 | 23.503204 | 19.067127 | 11.026548 | 14.392353 | 7.978942 | 4.036101 | 25.193146 | 14.973810 | ... | 11.270795 | 14.132236 | 15.480999 | 10.183868 | 19.415047 | 27.263340 | 12.544895 | 14.446023 | 19.760115 | 10.920843 |
| 2 | 14.586010 | 13.869585 | 15.001597 | 16.088562 | 14.989753 | 15.055332 | 13.881459 | 14.251566 | 15.061149 | 15.794733 | ... | 15.848513 | 15.297975 | 16.091333 | 14.388843 | 15.170838 | 14.735168 | 14.798789 | 13.742496 | 13.630329 | 13.089798 |
| 3 | 14.592566 | 14.624412 | 14.269474 | 15.491898 | 15.569511 | 16.288342 | 15.164846 | 14.566668 | 13.327274 | 14.233431 | ... | 13.844853 | 15.285441 | 14.233530 | 14.675815 | 15.908656 | 15.858871 | 15.202689 | 15.007872 | 14.247766 | 14.850210 |
| 4 | 16.392326 | 14.859611 | 19.943062 | 13.869667 | 17.015881 | 15.606420 | 22.863440 | 16.727417 | 20.740311 | 12.586379 | ... | 16.827066 | 13.654144 | 14.565105 | 19.044834 | 13.281296 | 10.824958 | 10.942783 | 11.074723 | 12.510992 | 13.662723 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 595 | 14.199569 | 12.481850 | 15.573352 | 15.122883 | 15.642666 | 13.908475 | 16.400906 | 15.557431 | 17.194227 | 17.689520 | ... | 15.000471 | 17.024361 | 14.361902 | 15.227952 | 14.057050 | 16.765730 | 15.868464 | 15.708106 | 14.718128 | 13.703343 |
| 596 | 16.862871 | 15.523841 | 14.538917 | 13.587122 | 15.685340 | 16.660721 | 15.864644 | 14.723064 | 15.661668 | 17.678423 | ... | 14.425453 | 14.341781 | 15.765164 | 14.548565 | 13.399756 | 17.723585 | 16.486721 | 17.126137 | 14.486805 | 17.241503 |
| 597 | 16.452101 | 14.660017 | 14.022560 | 14.965786 | 15.117435 | 14.897168 | 15.493895 | 15.492521 | 15.704017 | 15.135339 | ... | 14.843552 | 14.960234 | 15.990202 | 14.974794 | 15.501653 | 16.243484 | 15.444390 | 14.754246 | 14.522926 | 15.973195 |
| 598 | 14.150993 | 16.409111 | 15.669437 | 15.129354 | 20.987328 | 15.376616 | 15.166396 | 15.373619 | 15.436773 | 14.702501 | ... | 14.456417 | 17.717783 | 14.643255 | 11.609344 | 17.478497 | 14.445816 | 14.792369 | 15.499956 | 14.302234 | 15.070537 |
| 599 | 18.794319 | 22.029449 | 16.802168 | 12.680256 | 8.722343 | 13.182603 | 15.911584 | 6.012594 | 20.524622 | 18.866379 | ... | 15.987385 | 6.264203 | 9.161081 | 5.458413 | 18.129385 | 17.038593 | 17.099699 | 26.817642 | 18.101303 | 17.728611 |
600 rows × 50 columns
# Predicción de cuantiles
# ==============================================================================
predicciones_cuantiles = modelo.predict(data=X_test, pred_type="quantiles", quantiles=[0.1, 0.9])
predicciones_cuantiles
| quant_0.1 | quant_0.9 | |
|---|---|---|
| 0 | 12.138686 | 17.828659 |
| 1 | 8.832257 | 21.029195 |
| 2 | 13.532447 | 16.402666 |
| 3 | 13.928053 | 16.376365 |
| 4 | 11.775336 | 19.083310 |
| ... | ... | ... |
| 595 | 13.756510 | 16.352524 |
| 596 | 13.673839 | 16.496371 |
| 597 | 13.872277 | 16.089009 |
| 598 | 12.043160 | 18.024937 |
| 599 | 9.239491 | 21.524747 |
600 rows × 2 columns
# Predicción de los parámetros distribucionales
# ==============================================================================
predicciones_parametros = modelo.predict(data=X_test, pred_type="parameters")
predicciones_parametros
| loc | scale | |
|---|---|---|
| 0 | 14.931164 | 2.270949 |
| 1 | 15.008944 | 4.737135 |
| 2 | 14.931164 | 1.137141 |
| 3 | 15.172076 | 0.985543 |
| 4 | 15.406059 | 2.829181 |
| ... | ... | ... |
| 595 | 15.053152 | 0.985543 |
| 596 | 15.050743 | 1.137141 |
| 597 | 15.008944 | 0.855896 |
| 598 | 14.931164 | 2.270949 |
| 599 | 15.332772 | 4.737135 |
600 rows × 2 columns
# Gráfico del intervalo de cuantiles 10%-90%
# ==============================================================================
idx_orden = np.argsort(X_test.ravel())
X_test_ordenado = X_test.ravel()[idx_orden]
predicciones_cuantiles_ordn = predicciones_cuantiles.iloc[idx_orden]
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(7, 3.5))
ax.scatter(X, y, alpha = 0.3, c = "black", s = 8)
ax.plot(X, cuantil_10, c = "black")
ax.plot(X, cuantil_90, c = "black")
ax.fill_between(X, cuantil_10, cuantil_90, alpha=0.3, color='red',
label='Intervalo de cuantiles teórico 0.1-0.9')
ax.plot(X_test_ordenado, predicciones_cuantiles_ordn.iloc[:, 0], c = "blue", label='Intervalo de cuantiles predicho')
ax.plot(X_test_ordenado, predicciones_cuantiles_ordn.iloc[:, 1], c = "blue")
ax.set_xticks(range(0, 25))
ax.set_title('Consumo eléctrico a lo largo del día')
ax.set_xlabel('Hora del día')
ax.set_ylabel('Consumo eléctrico (MWh)')
plt.legend();

Cobertura¶
Una de las métricas utilizadas para evaluar los intervalos es la cobertura. Su valor corresponde al porcentaje de observaciones que caen dentro del intervalo estimado. Idealmente, la cobertura empírica debería ser igual al nivel de cobertura nominal del intervalo. Un modelo bien calibrado debería lograr una cobertura empírica cercana al nivel nominal.
En este ejemplo se han calculado los cuantiles 0.1 y 0.9, por lo que el intervalo tiene un nivel de cobertura nominal del 80%. Si el intervalo predicho es correcto, aproximadamente el 80% de las observaciones deberían caer dentro de él.
# Cobertura del intervalo predicho
# ==============================================================================
limite_inferior = predicciones_cuantiles.iloc[:, 0].to_numpy()
limite_superior = predicciones_cuantiles.iloc[:, 1].to_numpy()
cobertura = ((y_test >= limite_inferior) & (y_test <= limite_superior)).mean()
ancho_medio = (limite_superior - limite_inferior).mean()
print(f'Cobertura empírica del IP 80% : {cobertura:.3f}')
print(f'Ancho medio del intervalo : {ancho_medio:.3f} (MWh)')
Cobertura empírica del IP 80% : 0.747 Ancho medio del intervalo : 6.470 (MWh)
Predicción probabilística¶
Por ejemplo, para determinar la probabilidad de que a las 8 de la mañana el consumo supere los 22,5 MWh, primero se predicen los parámetros de la distribución para $hora=8$ y luego, usando esos parámetros, se calcula la probabilidad $consumo \geq 22.5$ con la función de distribución acumulada.
# Predecir los parámetros de la distribución cuando hora=8
# ==============================================================================
x_nueva = np.array([[8.0]])
params_hora_8 = modelo.predict(data=x_nueva, pred_type="parameters")
print("Parámetros distribucionales predichos cuando hora=8:")
print(params_hora_8)
Parámetros distribucionales predichos cuando hora=8:
loc scale
0 15.008944 4.737135
# Probabilidad de que el consumo supere 22.5 cuando hora=8
# ==============================================================================
# Los nombres de columna dependen de la distribución elegida (p. ej., 'loc'/'scale' para Gaussiana)
mu_8 = params_hora_8['loc'].to_numpy()[0]
sigma_8 = params_hora_8['scale'].to_numpy()[0]
prob_exceder = 1 - stats.norm.cdf(22.5, loc=mu_8, scale=sigma_8)
print(f'P(consumo >= 22.5 MWh | hora=8) = {prob_exceder:.4f}')
P(consumo >= 22.5 MWh | hora=8) = 0.0569
Según la distribución predicha por el modelo, existe un 5,69% de probabilidad de que el consumo a las 8 de la mañana sea igual o superior a 22,5 MWh.
Si este mismo cálculo se realiza para todo el rango horario, se puede determinar la probabilidad de que el consumo supere un valor dado a lo largo del día.
# Predicción de probabilidad en el rango horario completo de consumo superior a 22.5 MWh
# ==============================================================================
horas = np.linspace(0, 24, 500)
d_horas = horas.reshape(-1, 1)
params_horas = modelo.predict(data=d_horas, pred_type="parameters")
prob_horas = 1 - stats.norm.cdf(
22.5,
loc=params_horas['loc'].to_numpy(),
scale=params_horas['scale'].to_numpy()
)
fig, ax = plt.subplots(figsize=(7, 3.5))
ax.plot(horas, prob_horas)
ax.set_xlabel('Hora del día')
ax.set_ylabel('P(consumo ≥ 22.5 MWh)')
ax.set_title('Probabilidad de superar 22.5 MWh a lo largo del día')
ax.set_xticks(range(0, 25, 2))
plt.tight_layout()

Ejemplo 2¶
El conjunto de datos dbbmi (Cuarto Estudio de Crecimiento Neerlandés, Fredriks et al. (2000a, 2000b)), disponible en el paquete R gamlss.data, contiene información sobre la edad y el índice de masa corporal (imc) de 7.294 jóvenes neerlandeses de entre 0 y 20 años. El objetivo es entrenar un modelo capaz de predecir cuantiles del índice de masa corporal en función de la edad, ya que este es uno de los estándares utilizados para detectar casos anómalos que puedan requerir atención médica.
Librerías y datos¶
# Librerías
# ==============================================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import lightgbm as lgb
from lightgbmlss.model import LightGBMLSS
from lightgbmlss.distributions.Gaussian import Gaussian
from lightgbmlss.distributions.Gamma import Gamma
from lightgbmlss.distributions.LogNormal import LogNormal
from lightgbmlss.distributions.StudentT import StudentT
from lightgbmlss.distributions.distribution_utils import DistributionClass
import lightgbmlss.distributions.Gaussian as Gaussian_mod
import lightgbmlss.distributions.StudentT as StudentT_mod
import lightgbmlss.distributions.Gamma as Gamma_mod
import lightgbmlss.distributions.LogNormal as LogNormal_mod
import warnings
warnings.filterwarnings('once')
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
# Cargar datos
# ==============================================================================
url = (
'https://raw.githubusercontent.com/JoaquinAmatRodrigo/'
'Estadistica-machine-learning-python/master/data/dbbmi.csv'
)
datos = pd.read_csv(url)
datos.head(3)
| age | bmi | |
|---|---|---|
| 0 | 0.03 | 13.235289 |
| 1 | 0.04 | 12.438775 |
| 2 | 0.04 | 14.541775 |
# Gráfico de la distribución de valores de imc
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
ax.hist(datos.bmi, bins=30, density=True, color='#3182bd', alpha=0.8)
ax.set_title('Distribución de los valores del índice de masa corporal')
ax.set_xlabel('imc')
ax.set_ylabel('densidad');

# Gráfico de la distribución del índice de masa corporal en función de la edad
# ==============================================================================
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(8, 4), sharey=True)
datos[datos.age <= 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[0]
)
axs[0].set_ylim([10, 30])
axs[0].set_title('Edad <= 2.5 años')
datos[datos.age > 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[1]
)
axs[1].set_title('Edad > 2.5 años')
fig.tight_layout()
plt.subplots_adjust(top = 0.85)
fig.suptitle('Distribución del índice de masa corporal en función de la edad', fontsize = 12);

Esta distribución presenta tres características importantes que deben tenerse en cuenta al modelarla:
La relación entre la edad y el índice de masa corporal no es ni lineal ni constante. Existe una relación positiva notable hasta aproximadamente los 0,25 años de edad, luego se estabiliza hasta los 10 años y vuelve a aumentar marcadamente de los 10 a los 20 años.
La varianza es heterogénea (heterocedasticidad), siendo menor en edades más jóvenes y mayor en edades más avanzadas.
La distribución de la variable respuesta no es normal; presenta asimetría y una cola positiva pronunciada.
Dadas estas características, se necesita un modelo que:
Sea capaz de aprender relaciones no lineales.
Pueda modelar explícitamente la varianza en función de los predictores, ya que no es constante.
Sea capaz de aprender distribuciones asimétricas con una cola positiva pronunciada.
Selección de distribución¶
lightgbmlss proporciona un procedimiento automatizado de selección de distribución mediante DistributionClass.dist_select(). La función ajusta cada distribución candidata a la variable objetivo por máxima verosimilitud y las ordena por log-verosimilitud negativa (NLL). Una NLL más baja indica un mejor ajuste a la distribución marginal (incondicional) de la respuesta (ignorando las características $\mathbf{X}$).
# Selección de distribución
# ==============================================================================
clase_dist = DistributionClass()
distribuciones_candidatas = [Gaussian_mod, StudentT_mod, Gamma_mod, LogNormal_mod]
nll_distribuciones = clase_dist.dist_select(
target=datos['bmi'].to_numpy(),
candidate_distributions=distribuciones_candidatas,
max_iter=50,
plot=True,
figure_size=(6, 3)
)
nll_distribuciones

| nll | distribution | |
|---|---|---|
| rank | ||
| 1 | 17688.355825 | LogNormal |
| 2 | 17807.554688 | Gamma |
| 3 | 18133.892757 | Gaussian |
| 4 | 18175.127931 | StudentT |
En base al ranking de NLL, se selecciona la distribución con el valor más bajo y se procede al entrenamiento del modelo. Para este conjunto de datos, LogNormal ocupa el primer lugar, lo que tiene sentido dado el sesgo positivo y la cola pesada observados en la distribución del índice de masa corporal.
Entrenamiento del modelo y ajuste de hiperparámetros¶
# División entrenamiento-test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos['age'].to_numpy().reshape(-1, 1),
datos['bmi'].to_numpy(),
test_size=0.2,
random_state=42
)
# Entrenamiento del modelo con la distribución seleccionada y optimización de hiperparámetros
# ==============================================================================
# Con XGBoostLSS los datos deben transformarse a xgb.DMatrix
# d_datos = xgb.DMatrix(X_train, label=y_train)
# Con LightGBMLSS los datos deben transformarse a lgb.Dataset
d_datos = lgb.Dataset(X_train, label=y_train)
modelo = LightGBMLSS(
LogNormal(stabilization='None', response_fn='exp', loss_fn='nll')
)
espacio_hiperparametros = {
"learning_rate": ["float", {"low": 1e-5, "high": 1, "log": True}],
"max_depth": ["int", {"low": 1, "high": 10, "log": False}],
"min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": False}],
"min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
"subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
"feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
"boosting": ["categorical", ["gbdt"]],
}
mejores_hiperparametros = modelo.hyper_opt(
hp_dict=espacio_hiperparametros,
train_set=d_datos,
num_boost_round=100,
nfold=5,
early_stopping_rounds=10,
max_minutes=10,
n_trials=30,
silence=True,
seed=123,
hp_seed=123
)
0%| | 0/30 [00:00<?, ?it/s]
Hyper-Parameter Optimization successfully finished.
Number of finished trials: 30
Best trial:
Value: 2.0346465443268174
Params:
learning_rate: 0.7526113148050829
max_depth: 1
min_gain_to_split: 0.12693190605161014
min_sum_hessian_in_leaf: 1.17102461864558e-08
subsample: 0.9928628563764392
feature_fraction: 0.20415744257468788
boosting: gbdt
opt_rounds: 100
# Entrenar el modelo con los hiperparámetros óptimos
# ==============================================================================
n_rondas = mejores_hiperparametros.pop('opt_rounds')
modelo.train(mejores_hiperparametros, d_datos, num_boost_round=n_rondas)
Predicciones e intervalos de predicción¶
Una vez entrenado el modelo, el objetivo es predecir cuantiles del IMC en función de la edad: no un único valor esperado, sino la forma de la distribución condicional completa $p(\text{imc} \mid \text{edad})$ en cada punto.
Concretamente, se predicen tres curvas de cuantiles sobre una rejilla fina de valores de edad:
- q0.05 y q0.95: los límites inferior y superior de un intervalo de predicción del 90%. Para cualquier edad dada, se espera que el 90% de los niños tengan un IMC dentro de este rango.
- q0.50: la mediana predicha, una medida robusta de tendencia central para la distribución asimétrica del IMC.
Se utiliza una rejilla regular de 500 valores de edad uniformemente espaciados (en lugar de las edades observadas) para que las curvas resultantes sean suaves, haciendo visualmente clara la heterocedasticidad y la no linealidad en todo el rango de edades.
# Predicción de la mediana (cuantil 50%) y el intervalo de predicción del 90%
# ==============================================================================
rejilla_edad = np.linspace(datos['age'].min(), datos['age'].max(), 500)
cuantiles_objetivo = [0.05, 0.5, 0.95]
cuantiles_rejilla = modelo.predict(
data=rejilla_edad.reshape(-1, 1), pred_type='quantiles', quantiles=cuantiles_objetivo
)
cuantiles_rejilla.head(3)
| quant_0.05 | quant_0.5 | quant_0.95 | |
|---|---|---|---|
| 0 | 12.119442 | 13.910258 | 15.860954 |
| 1 | 12.080288 | 13.831336 | 15.894178 |
| 2 | 13.200316 | 14.995238 | 16.919324 |
# Gráfico
# ==============================================================================
arr_cuantiles = cuantiles_rejilla.to_numpy() # forma (500, 3): q0.05, q0.50, q0.95
mascara_jovenes = rejilla_edad <= 2.5
mascara_mayores = rejilla_edad > 2.5
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(9, 4.5), sharey=True)
for ax, m_rejilla, m_datos, titulo in zip(
axs,
[mascara_jovenes, mascara_mayores],
[datos['age'] <= 2.5, datos['age'] > 2.5],
['Edad ≤ 2.5 años', 'Edad > 2.5 años']
):
ax.scatter(datos.loc[m_datos, 'age'], datos.loc[m_datos, 'bmi'], c='black', alpha=0.1, s=6)
ax.fill_between(
rejilla_edad[m_rejilla], arr_cuantiles[m_rejilla, 0], arr_cuantiles[m_rejilla, 2],
alpha=0.3, color='tomato', label='Intervalo de predicción 90%'
)
ax.plot(rejilla_edad[m_rejilla], arr_cuantiles[m_rejilla, 1], color='tomato', lw=2, label='Mediana (q0.50)')
ax.plot(rejilla_edad[m_rejilla], arr_cuantiles[m_rejilla, 0], color='tomato', lw=1, ls='--', label='q0.05 / q0.95')
ax.plot(rejilla_edad[m_rejilla], arr_cuantiles[m_rejilla, 2], color='tomato', lw=1, ls='--')
ax.set_title(titulo)
ax.set_xlabel('Edad (años)')
ax.set_ylabel('IMC')
axs[0].legend(fontsize=7)
fig.suptitle('Cuantiles de IMC predichos por edad (LogNormal GBM-LSS)', fontsize=11)
plt.tight_layout()

Por último, se calcula la cobertura empírica del intervalo de predicción del 90% en el conjunto de test retenido, donde un modelo bien calibrado debería lograr una cobertura cercana a 0,90.
# Predicción de cuantiles
# ==============================================================================
predicciones_cuantiles = modelo.predict(
data=X_test,
pred_type="quantiles",
quantiles=[0.05, 0.95]
)
predicciones_cuantiles
| quant_0.05 | quant_0.95 | |
|---|---|---|
| 0 | 13.938657 | 21.610874 |
| 1 | 17.045627 | 25.072260 |
| 2 | 14.604642 | 18.645010 |
| 3 | 13.751138 | 19.467578 |
| 4 | 14.599775 | 21.713120 |
| ... | ... | ... |
| 1454 | 14.551365 | 18.590945 |
| 1455 | 16.931873 | 25.026875 |
| 1456 | 14.720979 | 19.045074 |
| 1457 | 16.014579 | 23.116499 |
| 1458 | 14.618010 | 18.566463 |
1459 rows × 2 columns
# Cobertura del intervalo predicho
# ==============================================================================
limite_inferior = predicciones_cuantiles.iloc[:, 0].to_numpy()
limite_superior = predicciones_cuantiles.iloc[:, 1].to_numpy()
cobertura = ((y_test >= limite_inferior) & (y_test <= limite_superior)).mean()
ancho_medio = (limite_superior - limite_inferior).mean()
print(f'Cobertura empírica del IP 90% : {cobertura:.3f}')
print(f'Ancho medio del intervalo : {ancho_medio:.3f}')
Cobertura empírica del IP 90% : 0.906 Ancho medio del intervalo : 6.159
Instrucciones para citar¶
Cómo citar este documento
Si utilizas este documento o cualquier parte del mismo, por favor reconoce la fuente. ¡Gracias!
Gradient Boosting Probabilístico con Python: GBM-LSS, por Joaquín Amat Rodrigo, disponible bajo licencia Atribución-NoComercial-CompartirIgual 4.0 Internacional (CC BY-NC-SA 4.0 DEED) en https://cienciadedatos.net/documentos/py26b-gradient-boosting-probabilistico-python-gbmlss.html
¿Te ha gustado el artículo? Tu apoyo es importante
Tu contribución me ayudará a seguir generando contenido educativo gratuito. ¡Muchas gracias! 😊




Este trabajo de Joaquín Amat Rodrigo, Javier Escobar Ortiz está bajo una licencia Atribución-NoComercial-CompartirIgual 4.0 Internacional.
Permitido:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y construir a partir del material.
Bajo los siguientes términos:
-
Atribución: debes dar el crédito apropiado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda a ti o a tu uso.
-
NoComercial: no puedes utilizar el material para fines comerciales.
-
CompartirIgual: si remezclas, transformas o construyes a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.