Más sobre ciencia de datos en: cienciadedatos.net
- Regresión lineal con Python
- Regresión lineal múltiple con Python
- Regresión logística con Python
- Regularización Ridge, Lasso y Elastic Net con Python
- Machine learning con Python y Scikitlearn
- Árboles de decisión con Python: regresión y clasificación
- Random Forest con Python y Scikit-learn
- Gradient Boosting con Python y Scikit-learn
- Gradient Boosting probabilístico con Python (NGBoost)
- Gradient Boosting probabilístico con Python (GBMLSS)
- Máquinas de Vector Soporte (SVM)
- Redes neuronales con Python
- Análisis de componentes principales PCA
- Clustering
- Detección de anomalías con PCA
- Detección de anomalías con autoencoders
- Detección de anomalías con Gaussian Mixture Models
- Detección de anomalías con Isolation Forest
- Análisis de texto (text mining) con Python
- Reglas de asociación
Introducción¶
La mayoría de métodos de machine learning aplicados a problemas de regresión modelan el comportamiento de una variable respuesta $y$ en función de uno o varios predictores $X$, y generan predicciones de tipo "estimación puntual". Estas predicciones se corresponden con el valor esperado de $y$ dado un determinado valor de los predictores ($\mathbb{E}[y|X]$).
La principal limitación de este tipo de modelos es que no ofrecen ninguna información sobre la incertidumbre asociada al valor predicho. Tampoco permiten responder a preguntas como:
¿Cuál es la probabilidad de que, dado un valor de $X$, la variable respuesta $y$ sea menor o mayor que un determinado valor?
¿Cuál es la probabilidad de que, dado un valor de $X$, la variable respuesta $y$ esté comprendida dentro de un intervalo?
Para responder a estas preguntas, se necesitan métodos de regresión probabilística capaces de modelar la distribución de probabilidad condicional de la variable respuesta en función de los predictores ($P(y|X)$).
Véase el siguiente ejemplo simulado (y muy simplificado) sobre la evolución del consumo eléctrico de todas las casas de una ciudad en función de la hora del día.
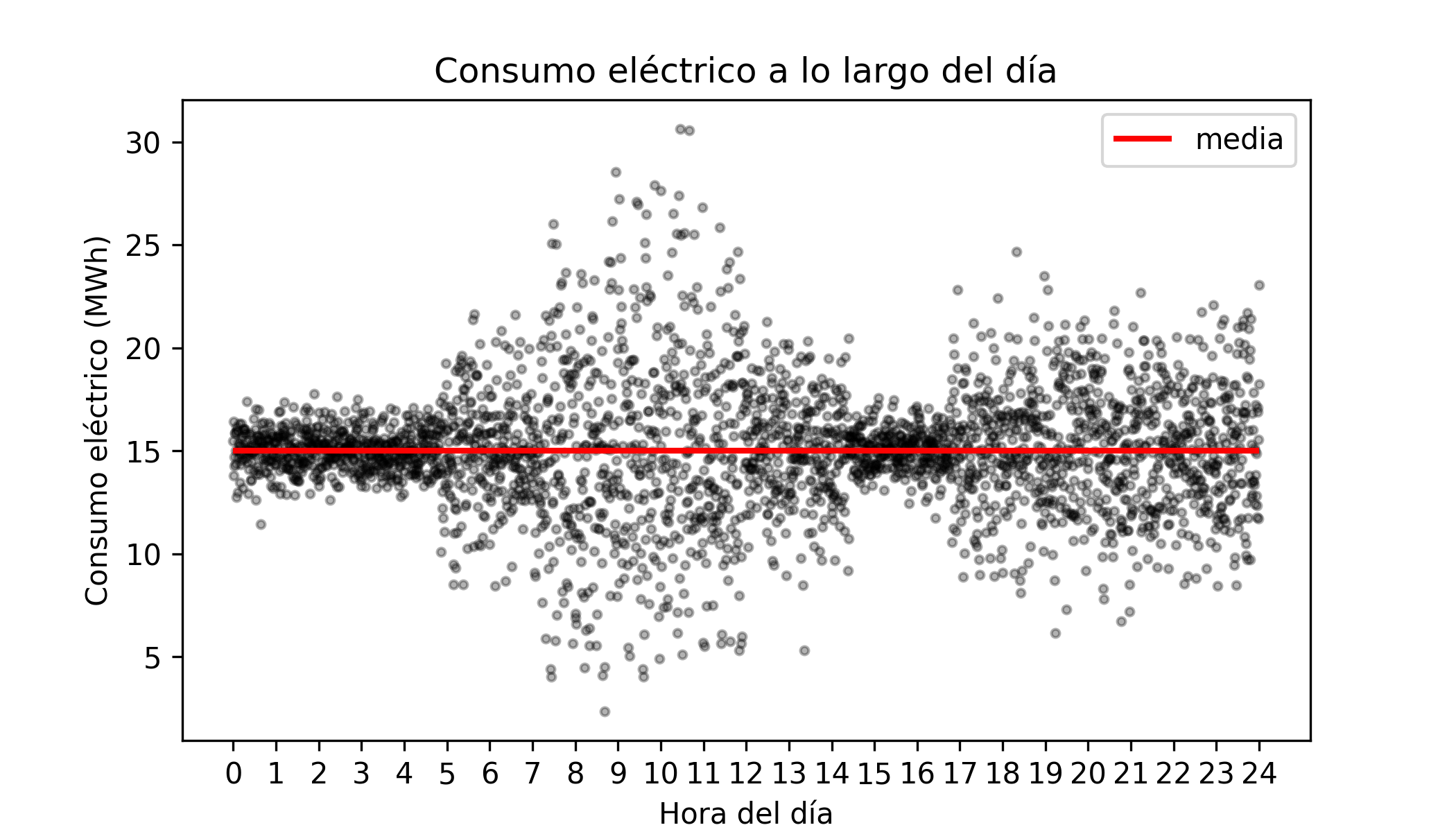
La media del consumo eléctrico es la misma durante todo el día, $\overline{consumo}$ = 15 Mwh, sin embargo, su dispersión no es constante (heterocedasticidad).
Ahora, imagínese que la compañía encargada de suministrar la electricidad debe de ser capaz de provisionar, en un momento dado, con hasta un 50% de electricidad extra respecto al promedio. Esto significa un máximo de 22.5 Mwh. Estar preparado para suministrar este extra de energía implica gastos de personal y maquinaría, por lo que la compañía se pregunta si es necesario estar preparado para producir tal cantidad durante todo el día, o si, por el contrario, podría evitarse durante algunas horas, ahorrando así gastos.
Un modelo que predice únicamente el promedio no permite responder a esta pregunta ya que, tanto para las 2h de la mañana como para las 8h, el consumo promedio predicho es en torno a 15 Mwh. Sin embargo, la probabilidad de que se alcancen consumos de 22.5 Mwh a las 2h es prácticamente nula mientras que esto ocurra a las 10h sí es razonable.
Una forma de poder predecir la probabilidad de que el consumo eléctrico exceda un determinado valor, a una hora determinada, es modelar su distribución de probabilidad en función de la hora del día.
💡 Tip
Este docuemento forma parte de una serie sobre machine learning probabilístico.
Natural Gradient Boosting (NGBoost)¶
Natural Gradient Boosting (NGBoost) es una generalización de gradient boosting que es capaz de estimar los parámetros $\theta$ de una distribución de probabilidad condicional, permitiendo así generar predicciones probabilísticas. Sin entrar en detalles matemáticos, las dos principales diferencias respecto a gradient boosting son:
Utiliza el descenso de gradiente natural en lugar del descenso de gradiente para el ajuste del modelo. A diferencia del gradiente estándar, el gradiente natural corrige la curvatura del espacio de parámetros de la distribución (utilizando la matriz de información de Fisher), lo que hace los pasos de optimización invariantes a la reparametrización y mejora la convergencia.
Estima los parámetros de una distribución de probabilidad paramétrica $P_{\theta}(y|X)$ en lugar de una estimación puntual $\mathbb{E}[y|X]$.
Por ejemplo, si la distribución elegida es una normal, NGBoost modela los valores de la media $\mu$ y desviación típica $\sigma$ en función de los predictores $X$. De esta forma, no es necesario asumir la condición de homocedasticidad (misma varianza para todo el rango de $X$).
Natural Gradient Boosting con Python
La librería ngboost desarrollada por el equipo Stanford Machine Learning Group implementa este tipo de modelos en python, con una API similar y compatible con la de scikit learn.
En términos generales, para entrenar un modelo ngboost es necesario definir 3 elementos:
Un tipo de base learner, por defecto se emplea árboles de decisión de scikit-learn.
Una distribución paramétrica de probabilidad.
Una regla de scoring que permita dirigir el ajuste.
El resto de pasos son iguales a los seguidos en un modelo gradient boosting de scikitlearn, incluida la posibilidad de optimizar los hiperparámetros mediante GridSearchCV y early_stopping_rounds.
La librería ngboost es reciente y seguro que irá evolucionando e incluyendo más funcionalidades. Puede encontrarse información detallada en NGBoost user guide. Por el momento, las distribuciones disponibles y reglas de scoring son:
Distribuciones para regresión
| Distribution | Parameters | Implemented Scores | Reference |
|---|---|---|---|
Normal |
loc, scale |
LogScore, CRPScore |
scipy.stats normal |
LogNormal |
s, scale |
LogScore, CRPScore |
scipy.stats lognormal |
Exponential |
scale |
LogScore, CRPScore |
scipy.stats exponential |
Distribuciones para clasificación
| Distribution | Parameters | Implemented Scores | Reference |
|---|---|---|---|
k_categorical(K) |
p0, p1... p{K-1} |
LogScore |
Categorical distribution on Wikipedia |
Bernoulli |
p |
LogScore |
Bernoulli distribution on Wikipedia |
Comparación con otros modelos probabilísticos¶
Dada la necesidad crítica de incorporar la incertidumbre en la toma de decisiones, la comunidad ha desarrollado múltiples enfoques para ir más allá de las predicciones puntuales. Esta sección compara cuatro de las metodologías más utilizadas para la estimación probabilística y la regresión condicional.
NGBoost (Natural Gradient Boosting)
Desarrollado por el laboratorio de ML de Stanford, NGBoost es una extensión del Gradient Boosting tradicional orientada a la estimación de incertidumbre.
¿Cómo funciona?: NGBoost asume que la variable objetivo sigue una distribución paramétrica $P(y|\theta)$, donde $\theta$ es un vector de parámetros (por ejemplo, $\theta = (\mu, \sigma)$ para una distribución Normal). El modelo no predice $y$ directamente, sino que modela los parámetros $\theta$ como funciones aditivas de las variables $X$.
Gradiente Natural: A diferencia del gradiente estándar (utilizado en modelos de gradient boosting estandar) que mide distancias entre números, el gradiente natural mide la distancia entre distribuciones de probabilidad (usando la Divergencia de Kullback-Leibler). Esto hace que el aprendizaje sea más estable y matemáticamente elegante.
Ventaja: Proporciona estimaciones de incertidumbre muy precisas y estables.
Desventaja: Es más lento que los modelos de boosting tradicionales porque el cálculo del gradiente natural es computacionalmente costoso.
BART (Bayesian Additive Regression Trees)
BART es un modelo bayesiano que no depende de la optimización del gradiente, sino se basa en el muestreo estadístico bayesiano.
¿Cómo funciona?: BART construye un "ensamble" de árboles muy simples (débiles). A diferencia del boosting, donde cada árbol corrige al anterior, en BART los árboles se van modificando mediante un proceso llamado MCMC (Markov Chain Monte Carlo). En cada iteración, se propone una modificación a un árbol (crecer, podar, cambiar regla o permutar) y se acepta/rechaza según el ratio de Metropolis-Hastings.
Regularización (Priors): BART impone priors fuertemente regularizadores que penalizan la profundidad de los árboles y los pesos de los nodos hoja. Esto obliga a que cada árbol contribuya de manera marginal (efecto shrinkage natural), evitando el sobreajuste.
Mecanismo de Inferencia: Durante el entrenamiento, el modelo genera miles de versiones posibles del "bosque" de árboles. La predicción final no es un solo número, sino el promedio de todas estas versiones. La incertidumbre se obtiene viendo cuánto varían las predicciones entre todos los bosques generados.
Ventaja: No necesitas elegir una distribución (es no paramétrico). Es extraordinariamente robusto a la configuración de hiperparámetros.
Desventaja: El proceso secuencial de MCMC es difícilmente paralelizable y computacionalmente restrictivo ($O(n)$ por iteración), lo que limita su escalabilidad.
GBM-LSS (Gradient Boosting for Location, Scale, and Shape)
GBM-LSS lleva el concepto de "Location, Scale and Shape" (Ubicación, Escala y Forma) al mundo del Gradient Boosting de alto rendimiento (como XGBoost o LightGBM).
¿Cómo funciona?: Modela la distribución condicional estimando múltiples parámetros $\theta = (\theta_1, \theta_2, \theta_3, \theta_4)$, que típicamente corresponden a métricas de ubicación ($\mu$), escala ($\sigma$), asimetría ($\nu$, skewness) y curtosis ($\tau$). Permite ajustar cualquier distribución diferenciable (e.g., Zero-Inflated, Tweedie, Student-t). En este sentido es similar a los modelos de NGBoost.
Multi-parámetro cíclico. El modelo entrena árboles de forma secuencial para cada parámetro, es decir, asume independencia iterativa entre parámetros.
Ventaja: Es el más rápido de los tres y el más flexible. Al aprovechar infraestructuras como XGBoost/LightGBM, hereda soporte nativo para paralelización de GPU, early stopping eficiente y manejo de missing values, permitiendo escalar a millones de registros.
Desventaja: Puede ser difícil de configurar y a veces inestable si los parámetros no están bien balanceados.
Regresión Cuantílica (Quantile Regression)
Implementada comúnmente mediante variaciones de algoritmos como Quantile Regression Forests (QRF) o mediante modelos de Gradient Boosting clásicos (LightGBM, CatBoost) cambiando la función de pérdida.
Fundamento Teórico: En lugar de estimar la media condicional $\mathbb{E}[Y|X]$ o los parámetros de una distribución entera $P(Y|X)$, la regresión cuantílica estima directamente un cuantil específico $Q_\tau(Y|X)$ (por ejemplo, $\tau = 0.9$ para el percentil 90). Es matemáticamente "libre de distribución" (distribution-free), por lo que no asume ninguna forma (ni normal, ni gamma, ni ninguna otra).
Mecanismo de Optimización: Abandona el error cuadrático medio (MSE) o la estimación de máxima verosimilitud en favor de minimizar la Pérdida Pinball (Quantile Loss): $$L_\tau(y, \hat{y}) = \max(\tau(y - \hat{y}), (\tau - 1)(y - \hat{y}))$$ Esta función asimétrica penaliza las subestimaciones y sobreestimaciones de manera diferente dependiendo del cuantil $\tau$ objetivo.
Ventajas: Es extremadamente robusta frente a outliers y heterocedasticidad. No requiere suposiciones paramétricas previas.
Limitaciones: Mientras que NGBoost, BART o GBM-LSS estiman la curva de probabilidad entera (PDF), la regresión cuantílica solo predice puntos específicos predefinidos (cuantiles). Al carecer de la distribución completa, se pierde flexibilidad analítica a posteriori: si en el futuro se requiere conocer la varianza exacta o consultar la probabilidad en un nuevo umbral, será necesario reentrenar el modelo para calcular esos nuevos puntos.
| Atributo | NGBoost | GBM-LSS | BART | Regresión Cuantílica |
|---|---|---|---|---|
| Objetivo | Densidad Completa (PDF) | Densidad Completa (PDF) | Densidad Completa (Posterior) | Puntos de la CDF |
| Aproximación | Paramétrica ($\mu, \sigma$) | Paramétrica ($\mu, \sigma, \nu, \tau$) | Bayesiana (No paramétrica) | Libre de distribución (Empírica) |
| Optimización | Gradiente Natural (MLE/CRPS) | Expansión de Taylor (Newton-Raphson) | Muestreo MCMC | Pinball Loss |
| Salida Predicha | Parámetros distribucionales | Parámetros distribucionales | Promedio de cadenas de Markov | Intervalos directos (ej. $y_{10}$ a $y_{90}$) |
| Problemas Típicos | Lento de entrenar | Complejo de estabilizar / ajustar | Escasa escalabilidad a Big Data | Quantile Crossing |
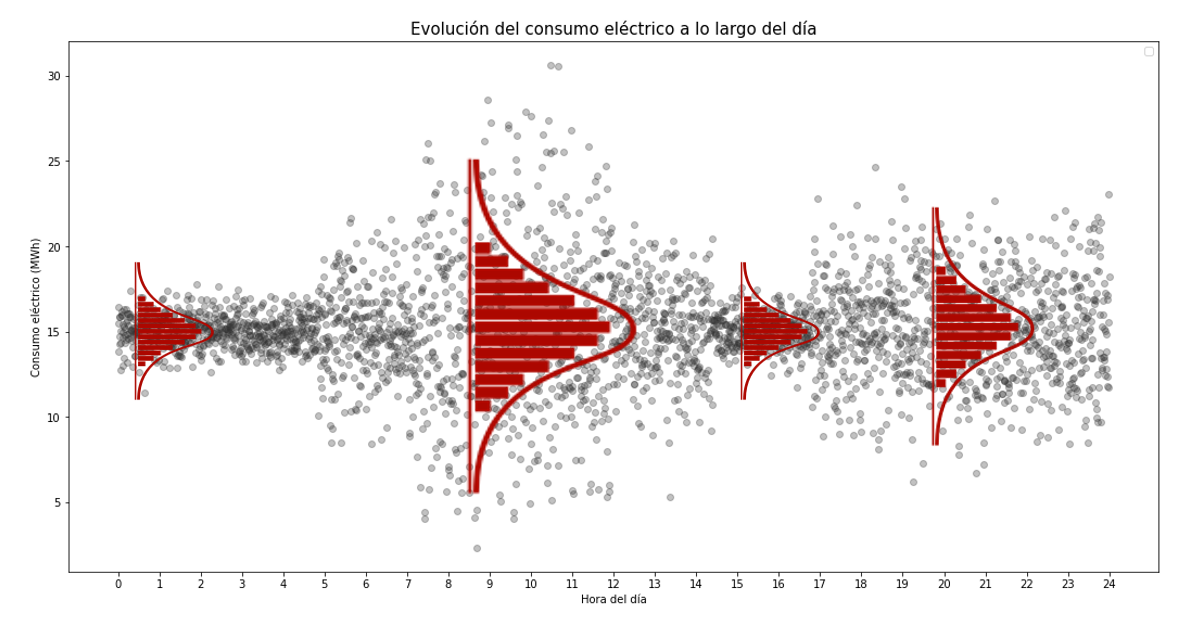
Ejemplo 1¶
Una empresa suministradora de energía eléctrica dispone del consumo horario de todas las casas de una ciudad. Para distribuir sus recursos de la forma más óptima, quiere ser capaz de generar un modelo probabilístico que le permita predecir, con un intervalo de predicción del 90%, el consumo promedio para cada hora del día. También quieren poder calcular la probabilidad a lo largo del día de que el consumo exceda un determinado valor.
Librerías¶
Las librerías utilizadas en este documento son:
# Tratamiento de datos
# ==============================================================================
import pandas as pd
import numpy as np
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
# Modelado
# ==============================================================================
from ngboost import NGBRegressor
from ngboost import scores
from ngboost import distns
from sklearn.tree import DecisionTreeRegressor
from scipy import stats
# Configuración warnings
# ==============================================================================
import warnings
warnings.filterwarnings('once')
Datos¶
Se simulan datos a partir de una distribución normal con una varianza distinta dependiendo de la hora del día.
# Datos simulados
# ==============================================================================
# Simulación ligeramente modificada del ejemplo publicado en
# XGBoostLSS – An extension of XGBoost to probabilistic forecasting Alexander März
np.random.seed(seed=1234)
n = 3000
# Distribución normal con varianza cambiante
x = np.linspace(start=0, stop= 24, num=n)
y = np.random.normal(
loc = 15,
scale = (
1 + 1.5 * ((4.8 < x) & (x < 7.2)) + 4 * ((7.2 < x) & (x < 12))
+ 1.5 * ((12 < x) & (x < 14.4)) + 2 * (x > 16.8)
)
)
Dado que los datos se han simulado empleando distribuciones normales, se conoce el valor de los cuantiles teóricos para cada hora.
# Cálculo del cuantil 0.1 y 0.9 para cada posición de x simulada
# ==============================================================================
cuantil_10 = stats.norm.ppf(
q = 0.1,
loc = 15,
scale = (
1 + 1.5 * ((4.8 < x) & (x < 7.2)) + 4 * ((7.2 < x) & (x < 12))
+ 1.5 * ((12 < x) & (x < 14.4)) + 2 * (x > 16.8)
)
)
cuantil_90 = stats.norm.ppf(
q = 0.9,
loc = 15,
scale = (
1 + 1.5 * ((4.8 < x) & (x < 7.2)) + 4 * ((7.2 < x) & (x < 12))
+ 1.5 * ((12 < x) & (x < 14.4)) + 2 * (x > 16.8)
)
)
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(7, 3.5))
ax.scatter(x, y, alpha = 0.3, c = "black", s = 8)
ax.plot(x, cuantil_10, c = "black")
ax.plot(x, cuantil_90, c = "black")
ax.fill_between(x, cuantil_10, cuantil_90, alpha=0.3, color='red',
label='Intervalo cuantílico teórico 0.1-0.9')
ax.set_xticks(range(0, 25))
ax.set_title('Evolución del consumo eléctrico a lo largo del día')
ax.set_xlabel('Hora del día')
ax.set_ylabel('Consumo eléctrico (MWh)')
plt.legend();

Modelo¶
Para calcular los cuantiles, es necesario obtener primero la distribución probabilística de los datos. Con el objetivo de facilitar la demostración de este ejemplo, se asumen dos simplificaciones:
Se asume que la distribución es de tipo normal (se han simulado con esta distribución).
Se utilizan los hiperparámetros por defecto al ajustar el modelo.
En la práctica, es necesario un análisis preliminar que permita determinar estos dos puntos (ver ejemplo 2).
# Ajuste del modelo
# ==============================================================================
modelo = NGBRegressor(
Dist = distns.Normal,
Base = DecisionTreeRegressor(criterion='friedman_mse', max_depth=3),
Score = scores.LogScore,
natural_gradient = True,
n_estimators = 500,
learning_rate = 0.01,
minibatch_frac = 1.0,
col_sample = 1.0,
random_state = 123,
)
modelo.fit(X=x.reshape(-1, 1), Y=y)
[iter 0] loss=2.5299 val_loss=0.0000 scale=2.0000 norm=4.5902 [iter 100] loss=2.2691 val_loss=0.0000 scale=2.0000 norm=4.4540 [iter 200] loss=2.2101 val_loss=0.0000 scale=1.0000 norm=2.2067 [iter 300] loss=2.1927 val_loss=0.0000 scale=2.0000 norm=4.3769 [iter 400] loss=2.1775 val_loss=0.0000 scale=2.0000 norm=4.3366
NGBRegressor(random_state=RandomState(MT19937) at 0x70F7927DD140)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| Dist | <class 'ngboo...ormal.Normal'> | |
| Score | <class 'ngboo...res.LogScore'> | |
| Base | DecisionTreeR..., max_depth=3) | |
| natural_gradient | True | |
| n_estimators | 500 | |
| learning_rate | 0.01 | |
| minibatch_frac | 1.0 | |
| col_sample | 1.0 | |
| verbose | True | |
| random_state | RandomState(M...0x70F7927DD140 | |
| validation_fraction | 0.1 | |
| early_stopping_rounds | None |
DecisionTreeRegressor(criterion='friedman_mse', max_depth=3)
Parameters
| criterion | 'friedman_mse' | |
| splitter | 'best' | |
| max_depth | 3 | |
| min_samples_split | 2 | |
| min_samples_leaf | 1 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | None | |
| random_state | None | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.0 | |
| ccp_alpha | 0.0 | |
| monotonic_cst | None |
Predicciones¶
Los modelos NGBRegressor tienen dos métodos de predicción:
predict(): devuelve una predicción de tipo puntual (point estimate), tal como hacen la mayoría de modelos. Este es el valor esperado de la variable respuesta acorde al valor de los predictores en la observación de test $\mathbb{E}[y|x=x_i]$.pred_dist(): devuelve un objetongboost.distnsque contiene la distribución condicional de la variable respuesta para el valor de los predictores en la observación de test $P(y|x=x_i)$. Dentro de cada uno de estos objetos se encuentran almacenados los parámetros estimados.
# Predicción point estimate
# ==============================================================================
predicciones_point = modelo.predict(X=x.reshape(-1, 1))
predicciones_point
array([15.02650577, 15.02650577, 15.02650577, ..., 15.13872404,
21.92369649, 17.73664598], shape=(3000,))
# Predicción distribución condicional
# ==============================================================================
predicciones_dist = modelo.pred_dist(X=x.reshape(-1, 1))
predicciones_dist
<ngboost.distns.normal.Normal at 0x70f7925edbd0>
# Dentro de cada objeto distns.distn se encuentran los parámetros estimados
predicciones_dist[0].params
{'loc': np.float64(15.026505766709645),
'scale': np.float64(0.9610903262391606)}
# Parámetros estimados para cada hora
# ==============================================================================
df_parametros = pd.DataFrame([dist.params for dist in predicciones_dist])
df_parametros['hora'] = x
df_parametros
| loc | scale | hora | |
|---|---|---|---|
| 0 | 15.026506 | 0.961090 | 0.000000 |
| 1 | 15.026506 | 0.961090 | 0.008003 |
| 2 | 15.026506 | 0.961090 | 0.016005 |
| 3 | 15.026506 | 0.961090 | 0.024008 |
| 4 | 15.026506 | 0.961090 | 0.032011 |
| ... | ... | ... | ... |
| 2995 | 15.674938 | 1.789045 | 23.967989 |
| 2996 | 13.786219 | 2.108075 | 23.975992 |
| 2997 | 15.138724 | 0.974876 | 23.983995 |
| 2998 | 21.923696 | 1.180863 | 23.991997 |
| 2999 | 17.736646 | 1.102145 | 24.000000 |
3000 rows × 3 columns
Predicción intervalos¶
Una vez conocidos los parámetros de la distribución condicional, se pueden calcular los cuantiles del consumo energético esperado para cada hora.
Un cuantil de orden $\tau$ $(0 < \tau < 1)$ de una distribución es el valor que marca un corte tal que, una proporción $\tau$ de valores de la población, es menor o igual que dicho valor. Por ejemplo, el cuantil de orden 0.36 deja un 36% de valores por debajo y el cuantil de orden 0.50 el 50% (se corresponde con la mediana de la distribución).
Todas las distribuciones de generadas por NGBRegressor son clases de scipy.stats, por lo que disponen de los métodos pdf(), logpdf(), cdf(), ppf() y rvs() con los que calcular la densidad, logaritmo de densidad, probabilidad acumulada, cuantiles, y muestreo de nuevos valores.
Los pasos a seguir para calcular los intervalos cuantílicos son:
Generar un grid de valores que cubra todo el intervalo de valores observado.
Para cada valor del grid, obtener los parámetros predichos por el modelo.
Calcular los cuantiles de la distribución seleccionada con los parámetros predichos.
# Cálculo de los cuantiles teóricos para establecer el intervalo central que
# acumula un 90% de probabilidad empleando los parámetros predichos.
# ==============================================================================
grid_X = np.linspace(start=min(x), stop=max(x), num=1000)
predicciones_dist = modelo.pred_dist(X=grid_X.reshape(-1, 1))
pred_cuantil_10 = [stats.norm.ppf(q=0.1, **dist.params) for dist in predicciones_dist]
pred_cuantil_90 = [stats.norm.ppf(q=0.9, **dist.params) for dist in predicciones_dist]
# Gráfico intervalo cuantílico 10%-90%
# ==============================================================================
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(7, 3.5))
ax.scatter(x, y, alpha = 0.3, c = "black", s = 8)
ax.plot(x, cuantil_10, c = "black")
ax.plot(x, cuantil_90, c = "black")
ax.fill_between(x, cuantil_10, cuantil_90, alpha=0.3, color='red',
label='Intervalo cuantílico teórico 0.1-0.9')
ax.plot(grid_X, pred_cuantil_10, c = "blue", label='Intervalo cuantílico predicho')
ax.plot(grid_X, pred_cuantil_90, c = "blue")
ax.set_xticks(range(0, 25))
ax.set_title('Evolución del consumo eléctrico a lo largo del día')
ax.set_xlabel('Hora del día')
ax.set_ylabel('Consumo eléctrico (MWh)')
plt.legend();

Cobertura¶
Una de las métricas empleadas para evaluar intervalos es la cobertura (coverage). Su valor se corresponde con el porcentaje de observaciones que caen dentro del intervalo estimado. Idealmente, la cobertura debe ser igual a la confianza del intervalo, por lo que, en la práctica, cuanto más próximo sea su valor, mejor.
En este ejemplo, se han calculado los cuantiles 0.1 y 0.9, así que, el intervalo, tiene una confianza del 80%. Si el intervalo predicho es correcto, aproximadamente el 80% de las observaciones estarán dentro.
# Predicción intervalos para las observaciones disponibles
# ==============================================================================
predicciones_dist = modelo.pred_dist(X=x.reshape(-1, 1))
pred_cuantil_10 = [stats.norm.ppf(q=0.1, **dist.params) for dist in predicciones_dist]
pred_cuantil_90 = [stats.norm.ppf(q=0.9, **dist.params) for dist in predicciones_dist]
# Cobertura del intervalo predicho
# ==============================================================================
dentro_intervalo = np.where((y >= pred_cuantil_10) & (y <= pred_cuantil_90), True, False)
cobertura = dentro_intervalo.mean()
print(f"Cobertura del intervalo predicho: {100 * cobertura:.2f}%")
Cobertura del intervalo predicho: 80.03333333333333
Predicción probabilistica¶
Si por ejemplo, se desea conocer la probabilidad de que a las 8h el consumo supere los 22.5 MWh, primero se predicen los parámetros de la distribución para $hora=8$ y después, con esos parámetros, se calcula la probabilidad de $consumo≥22.5$ con la función de distribución acumulada.
# Predicción de los parámetros de la distribución cuando x=8
# ==============================================================================
distribucion = modelo.pred_dist(X=np.array([8]).reshape(-1, 1))
distribucion.params
{'loc': array([14.1530422]), 'scale': array([4.52000988])}
# Probabilidad de que el consumo supere un valor de 22.5
# ==============================================================================
100 * (1 - stats.norm.cdf(x=22.5, **distribucion.params))
array([3.2397633])
Acorde a la distribución predicha por el modelo, existe una probabilidad del 3.24% de que el consumo a las 8h sea igual o superior a 22.5 MWh.
Si este mismo cálculo se realiza para todo el rango horario, se puede conocer la probabilidad de que el consumo exceda un determinado valor a lo largo del día.
# Predicción de probabilidad en todo el rango horario
# ==============================================================================
grid_X = np.linspace(start=0, stop=24, num=500)
predicciones_dist = modelo.pred_dist(X=grid_X.reshape(-1, 1))
predicciones_proba = [(1 - stats.norm.cdf(x=22.5, **dist.params)) for dist in predicciones_dist]
# Gráfico probabilidades
# ==============================================================================
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(7, 3))
ax.plot(grid_X, predicciones_proba)
ax.set_xticks(range(0, 25))
ax.set_title('Probabilidad de que el consumo supere los 22.5 MWh',
fontdict={'fontsize':13})
ax.set_xlabel('Hora del día')
ax.set_ylabel('Probabilidad');

Ejemplo 2¶
El set de datos dbbmi (Fourth Dutch Growth Study, Fredriks et al. (2000a, 2000b)), disponible en el paquete de R gamlss.data, contiene información sobre la edad (age) e índice de masa corporal (bmi) de 7294 jóvenes holandeses de entre 0 y 20 años. El objetivo es entrenar un modelo capaz de predecir cuantiles del índice de masa corporal en función de la edad, ya que este es uno de los estándares empleados para detectar casos anómalos que pueden requerir atención médica.
Librerías¶
# Tratamiento de datos
# ==============================================================================
import pandas as pd
import numpy as np
from tqdm import tqdm
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
# Modelado
# ==============================================================================
from ngboost import NGBRegressor
from ngboost import scores
from ngboost import distns
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV
from scipy import stats
import multiprocessing
# Configuración warnings
# ==============================================================================
import warnings
warnings.filterwarnings('once')
Datos¶
# Lectura de datos
# ==============================================================================
url = (
'https://raw.githubusercontent.com/JoaquinAmatRodrigo/'
'Estadistica-machine-learning-python/master/data/dbbmi.csv'
)
datos = pd.read_csv(url)
datos.head(3)
| age | bmi | |
|---|---|---|
| 0 | 0.03 | 13.235289 |
| 1 | 0.04 | 12.438775 |
| 2 | 0.04 | 14.541775 |
# Gráfico distribución de los valores de bmi
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
ax.hist(datos.bmi, bins=30, density=True, color='#3182bd', alpha=0.8)
ax.set_title('Distribución valores índice masa corporal')
ax.set_xlabel('bmi')
ax.set_ylabel('densidad');

# Gráfico distribución índice masa corporal en función de la edad
# ==============================================================================
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(8, 4), sharey=True)
datos[datos.age <= 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[0]
)
axs[0].set_ylim([10, 30])
axs[0].set_title('Edad <= 2.5 años')
datos[datos.age > 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[1]
)
axs[1].set_title('Edad > 2.5 años')
fig.tight_layout()
plt.subplots_adjust(top = 0.85)
fig.suptitle('Distribución índice masa corporal en función de la edad', fontsize = 12);

Esta distribución muestra tres características importantes que hay que tener en cuenta a la hora de modelarla:
La relación entre la edad y el índice de masa corporal no es lineal ni constante. Tiene una relación positiva notable hasta los 0.25 años, después se estabiliza hasta los 10 años y vuelve a ascender notablemente de los 10 a los 20 años.
La varianza es heterogénea (heterocedasticidad), siendo esta menor en edades bajas y mayor en edades altas.
La distribución de la variable respuesta no es de tipo normal, muestra asimetría y una cola positiva.
Dadas estas características, se necesita un modelo que:
Sea capaz de aprender relaciones no lineales.
Sea capaz de modelar explícitamente la varianza en función de los predictores, ya que esta no es constante.
Sea capaz de aprender distribuciones asimétricas con una marcada cola positiva.
Selección distribución paramétrica¶
Los modelos NGBoost requieren que se especifique un tipo de distribución paramétrica, por lo que el primer paso es identificar cuál de las tres distribuciones disponibles en NGBoost (normal, lognormal y exponencial) se ajusta mejor a los datos.
Se procede a ajustar cada una de las distribuciones y se evalúan gráficamente superponiéndolas con el histograma. Puede encontrarse información detallada de cómo comparar distribuciones en Ajuste y selección de distribuciones con Python.
def fit_plot_distribution(
x: np.ndarray,
nombre_distribucion,
ax=None,
verbose: bool = True,
):
'''
Esta función superpone la(s) curva(s) de densidad de una o varias
distribuciones con el histograma de los datos.
Parameters
----------
x : array_like
datos con los que ajustar la distribución.
nombre_distribucion : str o list
nombre de una distribución o lista de nombres de distribuciones
disponibles en `scipy.stats`.
ax : matplotlib.axes.Axes, optional
eje sobre el que realizar el gráfico. Si es None, se crea uno nuevo.
verbose : bool, optional
Si True, imprime los resultados del ajuste. Para múltiples distribuciones,
imprime advertencias de errores (default True).
Returns
-------
ax: matplotlib.axes.Axes
gráfico creado
'''
# Validación de entrada
x = np.asarray(x)
if x.size == 0:
raise ValueError("El array 'x' no puede estar vacío")
if not np.all(np.isfinite(x)):
raise ValueError("El array 'x' contiene valores NaN o infinitos")
if isinstance(nombre_distribucion, str):
nombre_distribucion = [nombre_distribucion]
if not isinstance(nombre_distribucion, (list, tuple)):
raise TypeError("El parámetro 'nombre_distribucion' debe ser un string, lista o tupla")
# Crear gráfico
if ax is None:
fig, ax = plt.subplots(figsize=(7,4))
# Graficar histograma
ax.hist(x=x, density=True, bins=30, color="#3182bd", alpha=0.5)
ax.plot(x, np.full_like(x, -0.01), '|k', markeredgewidth=1)
ax.set_title('Ajuste distribución' if len(nombre_distribucion) == 1 else
'Ajuste distribuciones')
ax.set_xlabel('x')
ax.set_ylabel('Densidad de probabilidad')
for nombre in tqdm(nombre_distribucion):
if not hasattr(stats, nombre):
if verbose:
print(f"⚠️ La distribución '{nombre}' no existe en scipy.stats")
continue
try:
distribucion = getattr(stats, nombre)
parametros = distribucion.fit(data=x)
is_continuous = isinstance(distribucion, stats.rv_continuous)
pdf_func = distribucion.pdf if is_continuous else distribucion.pmf
x_hat = np.linspace(min(x), max(x), num=100)
y_hat = pdf_func(x_hat, *parametros)
ax.plot(x_hat, y_hat, linewidth=2, label=distribucion.name)
except Exception as e:
if verbose:
print(f"⚠️ Error al ajustar la distribución '{nombre}': {type(e).__name__}: {e}")
ax.legend(loc='best')
return ax
fig, ax = plt.subplots(figsize=(6, 3))
fit_plot_distribution(
x=datos.bmi.to_numpy(),
nombre_distribucion=['lognorm', 'norm', 'expon'],
ax=ax
);

La representación gráfica muestra claras evidencias de que, entre las distribuciones disponibles, la lognormal es la que mejor se ajusta.
Modelo¶
A diferencia del ejemplo anterior, en este caso, se recurre a validación cruzada para identificar los hiperparámetros óptimos.
X = datos.age.to_numpy()
y = datos.bmi.to_numpy()
# Grid de hiperparámetros
# ==============================================================================
b1 = DecisionTreeRegressor(criterion='friedman_mse', max_depth=2)
b2 = DecisionTreeRegressor(criterion='friedman_mse', max_depth=4)
param_grid = {
'Base': [b1, b2],
'n_estimators': [100, 500, 1000]
}
# Búsqueda por validación cruzada
# ==============================================================================
grid = GridSearchCV(
estimator = NGBRegressor(
Dist = distns.LogNormal,
Score = scores.LogScore,
verbose = False
),
param_grid = param_grid,
scoring = 'neg_root_mean_squared_error', # Evalúa la predicción puntual (valor esperado). Para evaluar la calidad distribucional completa se usaría neg-log-likelihood o CRPS.
n_jobs = multiprocessing.cpu_count() - 1,
cv = 5,
verbose = 0
)
# Se asigna el resultado a _ para que no se imprima por pantalla
_ = grid.fit(X = X.reshape(-1, 1), y = y)
# Resultados del grid
# ==============================================================================
resultados = pd.DataFrame(grid.cv_results_)
resultados.filter(regex = '(param.*|mean_t|std_t)')\
.drop(columns = 'params')\
.sort_values('mean_test_score', ascending = False)
| param_Base | param_n_estimators | mean_test_score | std_test_score | |
|---|---|---|---|---|
| 1 | DecisionTreeRegressor(criterion='friedman_mse'... | 500 | -2.254565 | 0.420097 |
| 2 | DecisionTreeRegressor(criterion='friedman_mse'... | 1000 | -2.256332 | 0.360156 |
| 4 | DecisionTreeRegressor(criterion='friedman_mse'... | 500 | -2.291792 | 0.307326 |
| 3 | DecisionTreeRegressor(criterion='friedman_mse'... | 100 | -2.334395 | 0.438422 |
| 5 | DecisionTreeRegressor(criterion='friedman_mse'... | 1000 | -2.372743 | 0.200955 |
| 0 | DecisionTreeRegressor(criterion='friedman_mse'... | 100 | -2.444140 | 0.651819 |
# Mejores hiperparámetros
# ==============================================================================
print("-----------------------------------")
print("Mejores hiperparámetros encontrados")
print("-----------------------------------")
print(grid.best_params_, ":", grid.best_score_, grid.scoring)
-----------------------------------
Mejores hiperparámetros encontrados
-----------------------------------
{'Base': DecisionTreeRegressor(criterion='friedman_mse', max_depth=2), 'n_estimators': 500} : -2.2545651891289116 neg_root_mean_squared_error
# Mejor modelo encontrado
# ==============================================================================
modelo = grid.best_estimator_
Predicción intervalos¶
Una vez conocidos los parámetros de la distribución condicional, se pueden calcular los cuantiles del índice de masa corporal esperados para cada edad.
# Cálculo de los cuantiles teóricos para establecer el intervalo central que
# acumula un 90% de probabilidad empleando los parámetros predichos.
# ==============================================================================
grid_X = np.linspace(start=min(datos.age), stop=max(datos.age), num=2000)
predicciones_dist = modelo.pred_dist(X=grid_X.reshape(-1, 1))
pred_cuantil_10 = [stats.lognorm.ppf(q=0.1, **dist.params) for dist in predicciones_dist]
pred_cuantil_90 = [stats.lognorm.ppf(q=0.9, **dist.params) for dist in predicciones_dist]
df_intervalos = pd.DataFrame({
'age': grid_X,
'pred_cuantil_10': pred_cuantil_10,
'pred_cuantil_90': pred_cuantil_90
})
# Gráfico intervalo cuantílico 10%-90%
# ==============================================================================
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(10, 4.5), sharey=True)
datos[datos.age <= 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[0]
)
df_intervalos[df_intervalos.age <= 2.5].plot(
x = 'age',
y = 'pred_cuantil_10',
c = 'red',
kind = "line",
ax = axs[0]
)
df_intervalos[df_intervalos.age <= 2.5].plot(
x = 'age',
y = 'pred_cuantil_90',
c = 'red',
kind = "line",
ax = axs[0]
)
axs[0].set_ylim([10, 30])
axs[0].set_title('Edad <= 2.5 años')
datos[datos.age > 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[1]
)
df_intervalos[df_intervalos.age > 2.5].plot(
x = 'age',
y = 'pred_cuantil_10',
c = 'red',
kind = "line",
ax = axs[1]
)
df_intervalos[df_intervalos.age > 2.5].plot(
x = 'age',
y = 'pred_cuantil_90',
c = 'red',
kind = "line",
ax = axs[1]
)
axs[1].set_title('Edad > 2.5 años')
axs[1].get_legend().remove()
fig.tight_layout()
plt.subplots_adjust(top = 0.85)
fig.suptitle('Distribución índice masa corporal en función de la edad', fontsize = 14);

Cobertura¶
Una de las métricas empleadas para evaluar intervalos es la cobertura (coverage). Su valor se corresponde con el porcentaje de observaciones que caen dentro del intervalo estimado. Idealmente, la cobertura debe ser igual a la confianza del intervalo, por lo que, en la práctica, cuanto más próximo sea su valor, mejor.
En este ejemplo, se han calculado los cuantiles 0.1 y 0.9 empleando una distribución LogNormal, así que el intervalo tiene una confianza del 80%. Si el modelo y la distribución elegida son correctos, aproximadamente el 80% de las observaciones estarán dentro.
# Predicción intervalos para las observaciones disponibles
# ==============================================================================
predicciones_dist = modelo.pred_dist(X=X.reshape(-1, 1))
pred_cuantil_10 = [stats.lognorm.ppf(q=0.1, **dist.params) for dist in predicciones_dist]
pred_cuantil_90 = [stats.lognorm.ppf(q=0.9, **dist.params) for dist in predicciones_dist]
# Cobertura del intervalo predicho
# ==============================================================================
dentro_intervalo = np.where((y >= pred_cuantil_10) & (y <= pred_cuantil_90), True, False)
cobertura = dentro_intervalo.mean()
print(f"Cobertura del intervalo predicho: {100 * cobertura:.2f}%")
Cobertura del intervalo predicho: 82.10858239649028
Anomalías (outliers)¶
Conocer la distribución de probabilidad resulta útil para detectar anomalías, observaciones con valores muy poco probables acorde al modelo considerado.
Dada una determinada edad, índices de masa corporal bajos son un indicativo de posibles problemas de malnutrición y, valores muy altos, son indicativos de potenciales problemas de sobrepeso. Utilizando el modelo entrenado, se identifican aquellas personas con valores de bmi muy poco probables para la edad que tienen.
# Predicción intervalos del 98% para las observaciones disponibles
# ==============================================================================
X = datos.age.to_numpy()
y = datos.bmi.to_numpy()
predicciones_dist = modelo.pred_dist(X=X.reshape(-1, 1))
pred_cuantil_01 = [stats.lognorm.ppf(q=0.01, **dist.params) for dist in predicciones_dist]
pred_cuantil_99 = [stats.lognorm.ppf(q=0.99, **dist.params) for dist in predicciones_dist]
dentro_intervalo = np.where((y >= pred_cuantil_01) & (y <= pred_cuantil_99), True, False)
df_intervalos = pd.DataFrame({
'age': X,
'bmi': y,
'pred_cuantil_01': pred_cuantil_01,
'pred_cuantil_99': pred_cuantil_99,
'dentro_intervalo': dentro_intervalo
})
df_intervalos.head()
| age | bmi | pred_cuantil_01 | pred_cuantil_99 | dentro_intervalo | |
|---|---|---|---|---|---|
| 0 | 0.03 | 13.235289 | 11.016612 | 17.542151 | True |
| 1 | 0.04 | 12.438775 | 11.016612 | 17.542151 | True |
| 2 | 0.04 | 14.541775 | 11.016612 | 17.542151 | True |
| 3 | 0.04 | 11.773954 | 11.016612 | 17.542151 | True |
| 4 | 0.04 | 15.325614 | 11.016612 | 17.542151 | True |
Se resaltan en rojo aquellos individuos para los que, acorde al modelo, tienen una probabilidad de ocurrir igual o inferior al 1%.
# Gráfico anomalías
# ==============================================================================
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(10, 4.5), sharey=True)
df_intervalos[df_intervalos.age <= 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[0]
)
df_intervalos[(df_intervalos.age <= 2.5) & (df_intervalos.dentro_intervalo == False)].plot(
x = 'age',
y = 'bmi',
c = 'red',
kind = "scatter",
label = 'anomalia',
ax = axs[0]
)
axs[0].set_ylim([10, 30])
axs[0].set_title('Edad <= 2.5 años')
df_intervalos[df_intervalos.age > 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[1]
)
df_intervalos[(df_intervalos.age > 2.5) & (df_intervalos.dentro_intervalo == False)].plot(
x = 'age',
y = 'bmi',
c = 'red',
kind = "scatter",
ax = axs[1]
)
axs[1].set_title('Edad > 2.5 años')
fig.tight_layout()
plt.subplots_adjust(top = 0.85)
fig.suptitle('Distribución índice masa corporal en función de la edad', fontsize = 14);

Información de sesión¶
import session_info
session_info.show(html=False)
----- matplotlib 3.10.8 ngboost 0.5.10 numpy 2.3.5 pandas 2.3.3 scipy 1.15.3 seaborn 0.13.2 session_info v1.0.1 sklearn 1.7.2 tqdm 4.67.3 ----- IPython 9.10.0 jupyter_client 8.8.0 jupyter_core 5.9.1 ----- Python 3.13.11 | packaged by Anaconda, Inc. | (main, Dec 10 2025, 21:28:48) [GCC 14.3.0] Linux-6.17.0-20-generic-x86_64-with-glibc2.39 ----- Session information updated at 2026-04-13 21:47
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Gradient boosting probabilístico con python: NGBoost por Joaquín Amat Rodrigo, disponible bajo una licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://www.cienciadedatos.net/documentos/py26-gradient-boosting-probabilistico-python.html
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊



Este documento creado por Joaquín Amat Rodrigo tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.