Más sobre ciencia de datos en: cienciadedatos.net
- Regresión lineal con Python
- Regresión lineal múltiple con Python
- Regresión logística con Python
- Regularización Ridge, Lasso y Elastic Net con Python
- Machine learning con Python y Scikitlearn
- Árboles de decisión con Python: regresión y clasificación
- Random Forest con Python y Scikit-learn
- Gradient Boosting con Python y Scikit-learn
- Gradient Boosting probabilístico con Python
- Máquinas de Vector Soporte (SVM)
- Redes neuronales con Python
- Análisis de componentes principales PCA
- Clustering
- Detección de anomalías con PCA
- Detección de anomalías con autoencoders
- Detección de anomalías con Gaussian Mixture Models
- Detección de anomalías con Isolation Forest
- Análisis de texto (text mining) con Python
- Reglas de asociación
- Análisis Tweets con Python
Introducción¶
Un modelo Gradient Boosting está formado por un conjunto de árboles de decisión individuales, entrenados de forma secuencial, de forma que cada nuevo árbol trata de mejorar los errores de los árboles anteriores. La predicción de una nueva observación se obtiene combinando las predicciones de todos los árboles individuales que forman el modelo.
Muchos métodos predictivos generan modelos globales en los que una única ecuación se aplica a todo el espacio muestral. Cuando se dispone de múltiples predictores, que interaccionan entre ellos de forma compleja y no lineal, es muy difícil encontrar un único modelo global que sea capaz de reflejar la relación entre las variables. Los métodos estadísticos y de machine learning basados en árboles engloban a un conjunto de técnicas supervisadas no paramétricas que consiguen segmentar el espacio de los predictores en regiones simples, dentro de las cuales es más sencillo manejar las interacciones. Esta característica les proporciona gran parte de su potencial.
Los métodos basados en árboles se han convertido en un referente dentro del ámbito del machine learning por los buenos resultados que generan en problemas muy diversos. A lo largo de este documento se explora la forma en que se cómo se construyen y utilizan los modelos Gradient Boosting Trees.
✏️ Note
Dado que el elemento fundamental de un modelo Gradient Boosting Trees son los árboles de decisión, es fundamental entender cómo funcionan estos últimos. También es recomendable conocer los modelos Random Forest, que comparten muchas carácteristicas con Gradient boosting.
Ventajas
Son capaces de seleccionar predictores más relevantes de forma automática.
Pueden aplicarse a problemas de regresión y clasificación.
Los árboles pueden, en teoría, manejar tanto predictores numéricos como categóricos sin tener que crear variables dummy o one-hot-encoding. En la práctica, esto depende de la implementación del algoritmo que tenga cada librería.
Al ser métodos no paramétricos, no requieren que los datos sigan una distribución específica.
Por lo general, necesitan menos limpieza y preprocesamiento de datos en comparación con otros métodos de aprendizaje estadístico. Por ejemplo, no requieren estandarización.
Son menos susceptibles a ser influenciados por valores atípicos (outliers).
Si el valor de un predictor no está disponible para una observación, aún se puede realizar una predicción utilizando las observaciones del último nodo alcanzado. La precisión de la predicción se verá reducida pero al menos podrá obtenerse.
Son muy útiles en la exploración de datos, permiten identificar de forma rápida y eficiente las variables (predictores) más importantes.
Son adecuados para conjuntos de datos con un gran número de observaciones, demostrando una buena escalabilidad.
Desventajas
La combinación de múltiples árboles reduce la capacidad de interpretación en comparación con modelos basados en un solo árbol.
Al tratar con predictores continuos, se puede perder parte de la información al categorizarlos durante la división de los nodos.
Tal y como se describe más adelante, la creación de las ramificaciones de los árboles se consigue mediante el algoritmo de recursive binary splitting. Este algoritmo identifica y evalúa las posibles divisiones de cada predictor acorde a una determinada medida (RSS, Gini, entropía…). Los predictores continuos o predictores cualitativos con muchos niveles tienen mayor probabilidad de contener, solo por azar, algún punto de corte óptimo, por lo que suelen verse favorecidos en la creación de los árboles.
No son capaces de extrapolar fuera del rango observado en los datos de entrenamiento.
Gradient Boosting en Python¶
Debido a sus buenos resultados, Gradient Boosting se ha convertido en el algoritmo de referencia cuando se trata con datos tabulares, de ahí que se hayan desarrollado múltiples implementaciones. Todas ellas están muy optimizadas y se utilizan de forma similar, sin embargo, presentan diferencias en su implementación que pueden conducir a resultados distintos.
GradientBoostingClassifieryGradientBoostingRegressor: son las primeras implementaciones que se hicieron de Gradient Boosting en scikit-learn.- No realiza binning
- Utiliza un único core (no paraleliza ninguna de las partes del algoritmo)
- Permite trabajar sobre matrices sparse
- Necesario hacer one-hot-encoding de variables categóricas
HistGradientBoostingClassifieryHistGradientBoostingRegressor: nueva implementación de scikit-learn inspirada en gran medida en LightGBM. Acorde a los autores, esta segunda implementación tiene muchas más ventajas que la original, entre otras, su rapidez.- Sí realiza binning
- Multicore (paraleliza algunas partes del algoritmo)
- Permite que las observaciones incluyan valores missing
- Permite restricciones monotónicas
- No es necesario one-hot-encoding de variables categóricas.
-
- Permite que las observaciones incluyan valores missing
- Permite el uso de GPUs
- Entrenamiento paralelizado (paraleliza algunas partes del algoritmo)
- Permite restricciones monotónicas
- Permite trabajar sobre matrices sparse
- Acepta variables categóricas
-
- Permite que las observaciones incluyan valores missing
- Permite el uso de GPUs
- Entrenamiento paralelizado (paraleliza algunas partes del algoritmo)
- Permite restricciones monotónicas
- Permite trabajar sobre matrices sparse
- Acepta variables categóricas
-
- Optimizado principalmente para variables categóricas
- Utiliza árboles simétricos
- Permite que las observaciones incluyan valores missing
- Permite el uso de GPUs
- Entrenamiento paralelizado (paraleliza algunas partes del algoritmo)
- Permite restricciones monotónicas
- Acepta variables categóricas
-
- Sí realiza binning
- Multicore (paraleliza algunas partes del algoritmo)
- Permite que las observaciones incluyan valores missing
- Permite restricciones monotónicas
- Acepta variables categóricas
✏️ Note
Si bien todas estas librerías disponen de un API compatible scikit-learn, algunas de sus funcionalidades no son accesibles de esta forma, por lo que, para un uso más preciso, es recomendable utilizar su API nativa.
Gradient Boosting Trees¶
Un modelo Gradient Boosting Trees está formado por un conjunto (ensemble) de árboles de decisión individuales, entrenados de forma secuencial. Cada nuevo árbol emplea información del árbol anterior para aprender de sus errores, mejorando iteración a iteración. En cada árbol individual, las observaciones se van distribuyendo por bifurcaciones (nodos) generando la estructura del árbol hasta alcanzar un nodo terminal. La predicción de una nueva observación se obtiene agregando las predicciones de todos los árboles individuales que forman el modelo.
Para entender cómo funcionan los modelos Gradient Boosting Trees es necesario conocer primero los conceptos de ensemble y boosting.
Métodos de ensemble¶
Todos los modelos de aprendizaje estadístico y machine learning enfrentan el desafío del equilibrio entre sesgo y varianza.
El término "sesgo" (bias) se refiere a cuánto se desvían en promedio las predicciones de un modelo con respecto a los valores reales. Refleja la habilidad del modelo para capturar la verdadera relación entre los predictores y la variable de respuesta. Por ejemplo, si la relación sigue un patrón no lineal, un modelo de regresión lineal, independientemente de cuántos datos se disponga, no podrá modelar adecuadamente la relación y tendrá un sesgo alto.
Por otro lado, el término "varianza" hace referencia a cuánto cambia el modelo en función de los datos utilizados en su entrenamiento. Idealmente, un modelo no debería cambiar demasiado ante pequeñas variaciones en los datos de entrenamiento. Si esto ocurre, indica que el modelo está memorizando los datos en lugar de aprender la verdadera relación entre los predictores y la variable de respuesta. Por ejemplo, un modelo de árbol con muchos nodos tiende a cambiar su estructura incluso con pequeñas variaciones en los datos de entrenamiento, lo que indica que tiene alta varianza.
Conforme aumenta la complejidad de un modelo, este dispone una mayor flexibilidad para adaptarse a las observaciones, lo que conlleva una reducción del sesgo y una mejora en su capacidad predictiva. Sin embargo, una vez alcanzado un cierto nivel de complejidad, surge el problema del sobreajuste (overfitting). Este fenómeno se presenta cuando el modelo se ajusta tanto a los datos de entrenamiento que es incapaz de predecir correctamente nuevas observaciones. El modelo óptimo es aquel que logra encontrar un equilibrio adecuado entre sesgo y varianza.
¿Cómo se controlan el bias y varianza en los modelos basados en árboles? Por lo general, los árboles pequeños, con pocas ramificaciones, tienden a tener poca varianza pero pueden no captar de manera precisa la relación entre las variables, lo que se traduce en un alto sesgo. Por otro lado, los árboles grandes se ajustan mucho a los datos de entrenamiento, lo que reduce el sesgo pero incrementa la varianza. Una forma de solucionar este problema son los métodos de ensemble.
Los métodos de ensemble combinan múltiples modelos en uno nuevo con el objetivo de lograr un equilibro entre bias y varianza, consiguiendo así mejores predicciones que cualquiera de los modelos individuales originales. Dos de los tipos de ensemble más utilizados son:
Bagging: se ajustan múltiples modelos, cada uno con un subconjunto distinto de los datos de entrenamiento. Para predecir, todos los modelos que forman el agregado participan aportando su predicción. Como valor final, se toma la media de todas las predicciones (variables continuas) o la clase más frecuente (variables categóricas). Los modelos Random Forest están dentro de esta categoría.
Boosting: se ajustan secuencialmente múltiples modelos sencillos, llamados weak learners, de forma que cada modelo aprende de los errores del anterior. En el caso de Gradient Boosting Trees, los weak learners se consiguen utilizando árboles con una o pocas ramificaciones. Como valor final, al igual que en bagging, se toma la media de todas las predicciones (variables continuas) o la clase más frecuente (variables cualitativas). Tres de los algoritmos de boosting más empleados son AdaBoost, Gradient Boosting y Stochastic Gradient Boosting. Todos ellos se caracterizan por tener una cantidad considerable de hiperparámetros, cuyo valor óptimo se tiene que identificar mediante validación cruzada. Tres de los más importantes son:
El número de weak learners o número de iteraciones: a diferencia del bagging y random forest, el boosting puede sufrir overfitting si este valor es excesivamente alto. Para evitarlo, se emplea un término de regularización conocido como learning rate.
Learning rate: controla la influencia que tiene cada weak learner en el conjunto del ensemble, es decir, el ritmo al que aprende el modelo. Suelen recomendarse valores de 0.001 o 0.01, aunque la elección correcta puede variar dependiendo del problema. Cuanto menor sea su valor, más árboles se necesitan para alcanzar buenos resultados pero menor es el riesgo de overfitting.
Si los weak learners son árboles, el tamaño máximo permitido de cada árbol. Suelen emplearse valores pequeños, entre 1 y 10.
Aunque el objetivo final es el mismo, lograr un balance óptimo entre bias y varianza, existen dos diferencias importantes:
Forma en que consiguen reducir el error total. El error total de un modelo puede descomponerse como $bias + varianza + \epsilon$. En bagging, se emplean modelos con muy poco bias pero mucha varianza, agregándolos se consigue reducir la varianza sin apenas inflar el bias. En boosting, se emplean modelos con muy poca varianza pero mucho bias, ajustando secuencialmente los modelos se reduce el bias. Por lo tanto, cada una de las estrategias reduce una parte del error total.
Forma en que se introducen variaciones en los modelos que forman el ensemble. En bagging, cada modelo es distinto del resto porque cada uno se entrena con una muestra distinta obtenida mediante bootstrapping). En boosting, los modelos se ajustan secuencialmente y la importancia (peso) de las observaciones va cambiando en cada iteración, dando lugar a diferentes ajustes.
La clave para que los métodos de ensemble consigan mejores resultados que cualquiera de sus modelos individuales es que, los modelos que los forman, sean lo más diversos posibles (sus errores no estén correlacionados). Una analogía que refleja este concepto es la siguiente: supóngase un juego como el trivial en el que los equipos tienen que acertar preguntas sobre temáticas diversas. Un equipo formado por muchos jugadores, cada uno experto en un tema distinto, tendrá más posibilidades de ganar que un equipo formado por jugadores expertos en un único tema o por un único jugador que sepa un poco de todos los temas.
A continuación, se describen con más detalle las estrategias de boosting, sobre la que se fundamenta el modelo Gradient Boosting Trees.
AdaBoost¶
La publicación en 1995 del algoritmo AdaBoost (Adaptative Boosting) por parte de Yoav Freund y Robert Schapire supuso un avance muy importante en el campo del aprendizaje estadístico, ya que hizo posible aplicar la estrategia de boosting a multitud de problemas. Para el funcionamiento de AdaBoost (problema de clasificación binaria) es necesario establecer:
Un tipo de modelo, normalmente llamado weak learner o base learner, que sea capaz de predecir la variable respuesta con un porcentaje de acierto ligeramente superior a lo esperado por azar. En el caso de los árboles de regresión, este weak learner suele ser un árbol con apenas unos pocos nodos.
Codificar las dos clases de la variable respuesta como +1 y -1.
Un peso inicial e igual para todas las observaciones que forman el set de entrenamiento.
Una vez que estos tres puntos se han establecido, se inicia un proceso iterativo. En la primera iteración, se ajusta el weak learner empleando los datos de entrenamiento y los pesos iniciales (todos iguales). Con el weak learner ajustado y almacenado, se predicen las observaciones de entrenamiento y se identifican aquellas bien y mal clasificadas. Con esta información:
Se actualizan los pesos de las observaciones, disminuyendo el de las que están bien clasificadas y aumentando el de las mal clasificadas.
Se asigna un peso total al weak learner, proporcional al total de aciertos. Cuantos más aciertos consiga el weak learner, mayor su influencia en el conjunto del ensemble.
En la siguiente iteración, se llama de nuevo al weak learner y se vuelve a ajustar, esta vez, empleando los pesos actualizados en la iteración anterior. El nuevo weak learner se almacena, obteniendo así un nuevo modelo para el ensemble. Este proceso se repite M veces, generando un total de M weak learner. Para clasificar nuevas observaciones, se obtiene la predicción de cada uno de los weak learners que forman el ensemble y se agregan sus resultados, ponderando el peso de cada uno acorde al peso que se le ha asignado en el ajuste. El objetivo detrás de esta estrategia es que cada nuevo weak learner se centra en predecir correctamente las observaciones que los anteriores no han sido capaces.
Algoritmo AdaBoost
$n$: número de observaciones de entrenamiento
$M$: número de iteraciones de aprendizaje (número total de weak learners)
$G_m$: weak learner de la iteración $m$
$w_i$: peso de la observación $i$
$\alpha_m$: peso del weak learner $m$
Inicializar los pesos de las observaciones, asignando el mismo valor a todas ellas: $$w_i = \frac{1}{N}, i = 1, 2,..., N$$
Para $m=1$ hasta $M$:
2.1 Ajustar el weak learner $G_m$ utilizando las observaciones de entrenamiento y los pesos $w_i$.
2.2 Calcular el error del weak learner como: $$err_m = \frac{\sum^N_{i=1} w_iI(y_i \neq G_m(x_i))}{\sum^N_{i=1}w_i}$$
2.3 Calcular el peso asignado al weak learner $G_m$: $$\alpha_m = log(\frac{1-err_m}{err_m})$$
2.4 Actualizar los pesos de las observaciones: $$w_i = w_i exp[\alpha_m I(y_i \neq G_m(x_i))], \ \ \ i = 1, 2,..., N$$
Predicción de nuevas observaciones agregando todos los weak learners y ponderándolos por su peso:
Gradient Boosting¶
Gradient Boosting es una generalización del algoritmo AdaBoost que permite emplear cualquier función de coste, siempre que esta sea diferenciable. La flexibilidad de este algoritmo ha hecho posible aplicar boosting a multitud de problemas (regresión, clasificación múltiple...) convirtiéndolo en uno de los métodos de machine learning de mayor éxito. Si bien existen varias adaptaciones, la idea general de todas ellas es la misma: entrenar modelos de forma secuencial, de forma que cada modelo ajusta los residuos (errores) de los modelos anteriores.
Se ajusta un primer weak learner $f_1$ con el que se predice la variable respuesta $y$, y se calculan los residuos $y-f_1(x)$. A continuación, se ajusta un nuevo modelo $f_2$, que intenta predecir los residuos del modelo anterior, en otras palabras, trata de corregir los errores que ha hecho el modelo $f_1$.
$$f_1(x) ≈ y$$$$f_2(x) ≈ y - f_1(x)$$En la siguiente iteración, se calculan los residuos de los dos modelos de forma conjunta $y-f_1(x)-f_2(x)$, los errores cometidos por $f_1$ y que $f_2$ no ha sido capaz de corregir, y se ajusta un tercer modelo $f_3$ para tratar de corregirlos.
$$f_3(x) ≈ y - f_1(x) - f_2(x)$$Este proceso se repite $M$ veces, de forma que cada nuevo modelo minimiza los residuos (errores) del anterior.
Dado que el objetivo de Gradient Boosting es ir minimizando los residuos iteración a iteración, es susceptible de overfitting. Una forma de evitar este problema es empleando un valor de regularización, también conocido como learning rate ($\lambda$), que limite la influencia de cada modelo en el conjunto del ensemble. Como consecuencia de esta regularización, se necesitan más modelos para formar el ensemble pero se consiguen mejores resultados.
$$f_1(x) ≈ y$$$$f_2(x) ≈ y - \lambda f_1(x)$$$$f_3(x) ≈ y - \lambda f_1(x) - \lambda f_2(x)$$$$y ≈ \lambda f_1(x) + \lambda f_2(x) + \lambda f_3(x) + \ ... \ + \lambda f_m(x)$$Stochastic Gradient Boosting¶
Tiempo después de la publicación de algoritmo de Gradient Boosting, se le incorporó una de las propiedades de bagging, el muestreo aleatorio de observaciones de entrenamiento. En concreto, en cada iteración del algoritmo, el weak learner se ajusta empleando únicamente una fracción del set de entrenamiento, extraída de forma aleatoria y sin reemplazo (no con bootstrapping). Al resultado de esta modificación se le conoce como Stochastic Gradient Boosting y aporta dos ventajas: consigue mejorar la capacidad predictiva y permite estimar el out-of-bag-error.
A diferencia de Random Forest el out-of-bag-error de Stochastic Gradient Boosting solo es una buena aproximación del error de validación cruzada cuando el número de árboles en bajo. Ver detalles en Gradient Boosting Out-of-Bag estimates.
Binning¶
El principal cuello de botella que ralentiza al algoritmo de Gradient Boosting es la búsqueda de los puntos de corte (thresholds). Para encontrar el threshold óptimo en cada división, en cada árbol, es necesario iterar sobre todos los valores observados de cada uno de los predictores. El problema no es que haya muchos valores que comparar, sino que requiere ordenar cada vez las observaciones acorde a cada predictor, proceso computacionalmente muy costoso.
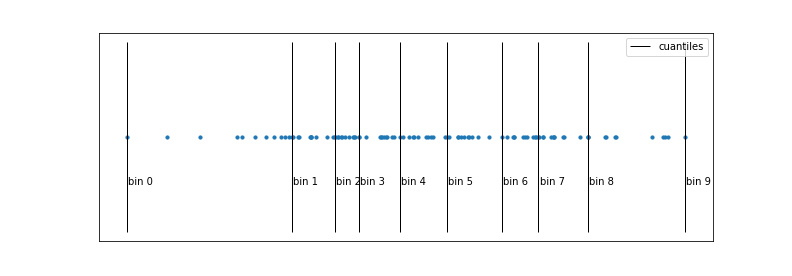
La estrategia de binning trata de reducir este cuello de botella agilizando el ordenamiento de las observaciones mediante una discretización de sus valores. Normalmente se emplean los cuantiles para hacer una discretización homogénea en cuanto al número de observaciones que cae en cada intervalo. Como resultado de este proceso, el ordenamiento es varios órdenes de magnitud más rápido. El potencial inconveniente de la discretización es que se pierde parte de la información, ya que únicamente se contemplan como posibles thresholds los límites de cada bin.
Esta es la principal característica que hace que las implementaciones de XGBoost, LightGBM, H2O y HistGradientBoosting sean mucho más rápida que la implementación original de scikitlearn GradientBoosting.
Parada temprana (early stopping)¶
Una de las características de los modelos Gradient Boosting es que, con el número suficiente de weak learners, el modelo final tiende a ajustarse perfectamente a los datos de entrenamiento causando overfitting. Este comportamiento implica que el analista tiene que encontrar el número adecuado de árboles y, para ello, suele tener que entrenar el modelo con cientos o miles de árboles hasta identificar el momento en el que empieza el overfitting. Esto suele ser poco eficiente en términos de tiempo, ya que, posiblemente, se estén ajustando muchos árboles innecesarios.
Para evitar este problema, la mayoría de implementaciones incluyen toda una serie de estrategias para detener el proceso de ajuste del modelo a partir del momento en el que este deja de mejorar. Por defecto, la métrica empleada se calcula utilizando un conjunto de validación. En la scikit-learn la estrategia de parada está controlada por los argumentos validation_fraction, n_iter_no_change y tol.
Importancia de los predictores¶
Si bien es cierto que el proceso de boosting (Gradient Boosting) consigue mejorar la capacidad predictiva en comparación a los modelos basados en un único árbol, esto tiene un coste asociado, la interpretabilidad del modelo se reduce. Al tratarse de una combinación de múltiples árboles, no es posible obtener una representación gráfica sencilla del modelo y no es inmediato identificar de forma visual que predictores son más importantes. Sin embargo, se han desarrollado nuevas estrategias para cuantificar la importancia de los predictores que hacen de los modelos de boosting (Gradient Boosting) una herramienta muy potente, no solo para predecir, sino también para el análisis exploratorio. Dos de estas medidas son: importancia por permutación e impureza de nodos.
Importancia por permutación
Identifica la influencia que tiene cada predictor sobre una determinada métrica de evaluación del modelo (estimada por out-of-bag error o validación cruzada). El valor asociado con cada predictor se obtiene de la siguiente forma:
Crear el conjunto de árboles que forman el modelo.
Calcular una determinada métrica de error (mse, classification error, ...). Este es el valor de referencia ($error_0$).
Para cada predictor $j$:
Permutar en todos los árboles del modelo los valores del predictor $j$ manteniendo el resto constante.
Recalcular la métrica tras la permutación, llámese ($error_j$).
Calcular el incremento en la métrica debido a la permutación del predictor $j$.
Si el predictor permutado estaba contribuyendo al modelo, es de esperar que el modelo aumente su error, ya que se pierde la información que proporcionaba esa variable. El porcentaje en que se incrementa el error debido a la permutación del predictor $j$ puede interpretarse como la influencia que tiene $j$ sobre el modelo. Algo que suele llevar a confusiones es el hecho de que este incremento puede resultar negativo. Si la variable no contribuye al modelo, es posible que, al reorganizarla aleatoriamente, solo por azar, se consiga mejorar ligeramente el modelo, por lo que $(error_j - error_0)$ es negativo. A modo general, se puede considerar que estas variables tiene una importancia próxima a cero.
Aunque esta estrategia suele ser la más recomendado, cabe tomar algunas precauciones en su interpretación. Lo que cuantifican es la influencia que tienen los predictores sobre el modelo, no su relación con la variable respuesta. ¿Por qué es esto tan importante? Supóngase un escenario en el que se emplea esta estrategia con la finalidad de identificar qué predictores están relacionados con el peso de una persona, y que dos de los predictores son: el índice de masa corporal (IMC) y la altura. Como IMC y altura están muy correlacionados entre sí (la información que aportan es redundante), cuando se permute uno de ellos, el impacto en el modelo será mínimo, ya que el otro aporta la misma información. Como resultado, estos predictores aparecerán como poco influyentes aun cuando realmente están muy relacionados con la variable respuesta. Una forma de evitar problemas de este tipo es, siempre que se excluyan predictores de un modelo, comprobar el impacto que tiene en su capacidad predictiva.
Incremento de la pureza de nodos
Cuantifica el incremento total en la pureza de los nodos debido a divisiones en las que participa el predictor (promedio de todos los árboles). La forma de calcularlo es la siguiente: en cada división de los árboles, se registra el descenso conseguido en la medida empleada como criterio de división (índice Gini, mse entropía, ...). Para cada uno de los predictores, se calcula el descenso medio conseguido en el conjunto de árboles que forman el ensemble. Cuanto mayor sea este valor medio, mayor la contribución del predictor en el modelo.
Ejemplo regresión¶
El set de datos Boston contiene precios de viviendas de la ciudad de Boston, así como información socio-económica del barrio en el que se encuentran. Se pretende ajustar un modelo de regresión que permita predecir el precio medio de una vivienda (MEDV) en función de las variables disponibles.
Librerías¶
Las librerías utilizadas en este ejemplo son:
# Tratamiento de datos
# ==============================================================================
import numpy as np
import pandas as pd
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
# Preprocesado y modelado
# ==============================================================================
import sklearn
from sklearn.ensemble import HistGradientBoostingRegressor, GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.metrics import root_mean_squared_error
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RepeatedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.inspection import permutation_importance
import xgboost
from xgboost import XGBRegressor
import lightgbm
from lightgbm import LGBMRegressor
import multiprocessing
# Configuración warnings
# ==============================================================================
import warnings
print(f"Versión scikit-learn: {sklearn.__version__}")
print(f"Versión pandas: {pd.__version__}")
print(f"Versión numpy: {np.__version__}")
print(f"Versión xgboost: {xgboost.__version__}")
print(f"Versión lightgbm: {lightgbm.__version__}")
Versión scikit-learn: 1.7.2 Versión pandas: 2.3.3 Versión numpy: 2.2.6 Versión xgboost: 3.0.5 Versión lightgbm: 4.6.0
Datos¶
El set de datos Boston contiene precios de viviendas de la ciudad de Boston, así como información socio-económica del barrio en el que se encuentran. Se pretende ajustar un modelo de regresión que permita predecir el precio medio de una vivienda (MEDV) en función de las variables disponibles.
Número de instancias: 506
Número de atributos: 13 predictivos numéricos/categoriales.
Información de los atributos (por orden):
- CRIM: tasa de delincuencia per cápita por ciudad.
- ZN: proporción de suelo residencial dividido para segmentos de más de 25.000 pies cuadrados.
- INDUS: proporción de superficie comerciales no minoristas por ciudad.
- CHAS: variable binaria sobre el río Charles (= 1 si la zona linda con el río; 0 en caso contrario).
- NOX: concentración de óxidos nítricos (partes por 10 millones).
- RM: número medio de habitaciones por vivienda.
- EDAD: proporción de viviendas ocupadas construidas antes de 1940.
- DIS: distancia ponderada a cinco centros de empleo en la ciudad de Boston.
- RAD: índice de accesibilidad a las autopistas radiales.
- TAX: impuesto sobre bienes inmuebles de valor íntegro por cada 10.000$.
- PTRATIO: ratio alumnos-profesor por ciudad.
- LSTAT: % de la población considerado de clase baja.
- MEDV: valor medio de las viviendas ocupadas por sus propietarios en miles de $.
Valores ausentes: Ninguno
# Descarga de datos
# ==============================================================================
url = (
'https://raw.githubusercontent.com/JoaquinAmatRodrigo/Estadistica-machine-learning-python/'
'master/data/Boston.csv'
)
datos = pd.read_csv(url, sep=',')
datos.head(3)
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 4.03 | 34.7 |
datos.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 506 entries, 0 to 505 Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CRIM 506 non-null float64 1 ZN 506 non-null float64 2 INDUS 506 non-null float64 3 CHAS 506 non-null int64 4 NOX 506 non-null float64 5 RM 506 non-null float64 6 AGE 506 non-null float64 7 DIS 506 non-null float64 8 RAD 506 non-null int64 9 TAX 506 non-null int64 10 PTRATIO 506 non-null float64 11 LSTAT 506 non-null float64 12 MEDV 506 non-null float64 dtypes: float64(10), int64(3) memory usage: 51.5 KB
Ajuste del modelo¶
Se ajusta un modelo empleando como variable respuesta MEDV y como predictores todas las otras variables disponibles.
La clase HistGradientBoostingRegressor del módulo sklearn.ensemble permite entrenar modelos Gradient Boosting para problemas de regresión. Los parámetros e hiperparámetros empleados por defecto son:
loss='squared_error'quantile=Nonelearning_rate=0.1max_iter=100max_leaf_nodes=31max_depth=Nonemin_samples_leaf=20l2_regularization=0.0max_bins=255categorical_features=Nonemonotonic_cst=Noneinteraction_cst=Nonewarm_start=Falseearly_stopping='auto'scoring='loss'validation_fraction=0.1n_iter_no_change=10tol=1e-07verbose=0random_state=None
Puede encontrarse una descripción detallada de todos ellos en sklearn.ensemble.GradientBoostingRegressor. En la práctica, cabe prestar especial atención a aquellos que controlan el crecimiento de los árboles, la velocidad de aprendizaje del modelo, y los que gestionan la parada temprana para evitar overfitting:
learning_rate: reduce la contribución de cada árbol multiplicando su influencia original por este valor.max_iter: número de árboles incluidos en el modelo.max_depth: profundidad máxima que pueden alcanzar los árboles.min_samples_leaf: número mínimo de observaciones que debe de tener cada uno de los nodos hijos para que se produzca la división. Si es un valor decimal se interpreta como fracción del total de observaciones de entrenamientoceil(min_samples_split * n_samples).max_leaf_nodes: número máximo de nodos terminales que pueden tener los árboles.early_stopping: Si es 'auto', se activa la parada temprana si el tamaño de la muestra es superior a 10000. Si esTrue, se activa la parada temprana; en caso contrario, se desactiva.validation_fraction: proporción de datos separados del conjunto entrenamiento y empleados como conjunto de validación para determinar la parada temprana (early stopping).n_iter_no_change: número de iteraciones consecutivas en las que no se debe superar eltolpara que el algoritmo se detenga (early stopping). Si su valor esNonese desactiva la parada temprana.tol: porcentaje mínimo de mejora entre dos iteraciones consecutivas por debajo del cual se considera que el modelo no ha mejorado.random_state: semilla para que los resultados sean reproducibles. Tiene que ser un valor entero.
Como en todo estudio predictivo, no solo es importante ajustar el modelo, sino también cuantificar su capacidad para predecir nuevas observaciones. Para poder hacer esta evaluación, se dividen los datos en dos grupos, uno de entrenamiento y otro de test.
# División de los datos en entrenamiento y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = "MEDV"),
datos['MEDV'],
random_state = 123
)
# Creación del modelo
# ==============================================================================
modelo = HistGradientBoostingRegressor(
max_iter = 10,
loss = 'squared_error',
random_state = 123
)
# Entrenamiento del modelo
# ==============================================================================
modelo.fit(X_train, y_train)
HistGradientBoostingRegressor(max_iter=10, random_state=123)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| loss | 'squared_error' | |
| quantile | None | |
| learning_rate | 0.1 | |
| max_iter | 10 | |
| max_leaf_nodes | 31 | |
| max_depth | None | |
| min_samples_leaf | 20 | |
| l2_regularization | 0.0 | |
| max_features | 1.0 | |
| max_bins | 255 | |
| categorical_features | 'from_dtype' | |
| monotonic_cst | None | |
| interaction_cst | None | |
| warm_start | False | |
| early_stopping | 'auto' | |
| scoring | 'loss' | |
| validation_fraction | 0.1 | |
| n_iter_no_change | 10 | |
| tol | 1e-07 | |
| verbose | 0 | |
| random_state | 123 |
Predicción y evaluación del modelo¶
Una vez entrenado el modelo, se evalúa la capacidad predictiva empleando el conjunto de test.
# Error de test del modelo inicial
# ==============================================================================
predicciones = modelo.predict(X = X_test)
rmse = root_mean_squared_error(
y_true = y_test,
y_pred = predicciones,
)
print(f"El error (rmse) de test es: {rmse}")
El error (rmse) de test es: 5.175175457179093
Optimización de hiperparámetros¶
El modelo inicial se ha entrenado utilizando 10 árboles (max_iter=10) y manteniendo el resto de hiperparámetros con su valor por defecto. Al ser hiperparámetros, no se puede saber de antemano cuál es el valor más adecuado, la forma de identificarlos es mediante el uso de estrategias de validación, por ejemplo validación cruzada.
✏️ Note
Cuando se busca el valor óptimo de un hiperparámetro con dos métricas distintas, el resultado obtenido raramente es el mismo. Lo importante es que ambas métricas identifiquen las mismas regiones de interés.
Número de árboles¶
En Gradient Boosting, el número de árboles es un hiperparámetro crítico en cuanto que, con forme se añaden árboles, se incrementa el riesgo de sobreajuste (overfitting).
# Validación empleando k-cross-validation y neg_root_mean_squared_error
# ==============================================================================
train_scores = []
cv_scores = []
# Valores evaluados
max_iter_range = range(1, 500, 25)
# Bucle para entrenar un modelo con cada valor de n_estimators y extraer su error
# de entrenamiento y de k-cross-validation.
for max_iter in max_iter_range:
modelo = HistGradientBoostingRegressor(
max_iter = max_iter,
random_state = 123
)
# Error de train
modelo.fit(X_train, y_train)
predicciones = modelo.predict(X = X_train)
rmse = root_mean_squared_error(
y_true = y_train,
y_pred = predicciones,
)
train_scores.append(rmse)
# Error de validación cruzada
scores = cross_val_score(
estimator = modelo,
X = X_train,
y = y_train,
scoring = 'neg_root_mean_squared_error',
cv = 5,
n_jobs = multiprocessing.cpu_count() - 1,
)
# Se agregan los scores de cross_val_score() y se pasa a positivo
cv_scores.append(-1*scores.mean())
# Gráfico con la evolución de los errores
fig, ax = plt.subplots(figsize=(5, 3))
ax.plot(max_iter_range, train_scores, label="train scores")
ax.plot(max_iter_range, cv_scores, label="cv scores")
ax.plot(max_iter_range[np.argmin(cv_scores)], min(cv_scores),
marker='o', color = "red", label="min score")
ax.set_ylabel("root_mean_squared_error")
ax.set_xlabel("n_estimators")
ax.set_title("Evolución del cv-error vs número árboles")
plt.legend();
print(f"Valor óptimo de n_estimators: {max_iter_range[np.argmin(cv_scores)]}")
Valor óptimo de n_estimators: 251

Los valores estimados por validación cruzada muestran que, a partir de los 50 árboles, el error del modelo se estabiliza, consiguiendo un mínimo con 251 árboles.
Learning rate¶
Junto con el número de árboles, el learning_rate es el hiperparámetro más importantes en Gradient Boosting, ya que es el que permite controlar cómo de rápido aprende el modelo y con ello el riesgo de llegar al overfitting. Estos dos hiperparámetros son interdependientes, cuanto menor es el learning rate, más árboles se necesitan para alcanzar buenos resultados pero menor es el riesgo de overfitting.
# Validación empleando k-cross-validation y neg_root_mean_squared_error
# ==============================================================================
resultados = {}
# Valores evaluados
learning_rates_grid = [0.001, 0.01, 0.1]
max_iter_grid = [10, 20, 100, 200, 300, 400, 500, 1000, 2000, 5000]
# Bucle para entrenar un modelo con cada combinacion de learning_rate y n_estimator
# y extraer su error de entrenamiento y k-cross-validation.
for learning_rate in learning_rates_grid:
train_scores = []
cv_scores = []
for n_estimator in max_iter_grid:
modelo = HistGradientBoostingRegressor(
max_iter = n_estimator,
learning_rate = learning_rate,
random_state = 123
)
# Error de train
modelo.fit(X_train, y_train)
predicciones = modelo.predict(X = X_train)
rmse = root_mean_squared_error(
y_true = y_train,
y_pred = predicciones
)
train_scores.append(rmse)
# Error de validación cruzada
scores = cross_val_score(
estimator = modelo,
X = X_train,
y = y_train,
scoring = 'neg_root_mean_squared_error',
cv = 3,
n_jobs = multiprocessing.cpu_count() - 1
)
# Se agregan los scores de cross_val_score() y se pasa a positivo
cv_scores.append(-1*scores.mean())
resultados[learning_rate] = {'train_scores': train_scores, 'cv_scores': cv_scores}
# Gráfico con la evolución de los errores de entrenamiento
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(9, 3))
for key, value in resultados.items():
axs[0].plot(max_iter_grid, value['train_scores'], label=f"Learning rate {key}")
axs[0].set_ylabel("root_mean_squared_error")
axs[0].set_xlabel("n_estimators")
axs[0].set_title("Evolución del train error vs learning rate")
axs[1].plot(max_iter_grid, value['cv_scores'], label=f"Learning rate {key}")
axs[1].set_ylabel("root_mean_squared_error")
axs[1].set_xlabel("n_estimators")
axs[1].set_title("Evolución del cv-error vs learning rate")
plt.legend();

Puede observarse que, cuanto mayor es el valor del learning rate, más rápido aprende el modelo pero antes puede aparecer el overfitting. En este caso, los errores estimados por validación cruzada indican que, el mejor modelo se consigue con un learning rate de 0.1.
Max depth¶
La profundidad de los árboles (max_depth) en los modelos Gradient Boosting suele ser un valor muy bajo, haciendo así que cada árbol solo pueda aprender un pequeña parte de la relación entre predictores y variable respuesta (weak learner).
# Validación empleando k-cross-validation y neg_root_mean_squared_error
# ==============================================================================
train_scores = []
cv_scores = []
# Valores evaluados
max_depths = [1, 3, 5, 10, 20]
# Bucle para entrenar un modelo con cada valor de max_depth y extraer su error
# de entrenamiento y de k-cross-validation.
for max_depth in max_depths:
modelo = HistGradientBoostingRegressor(
max_iter = 25,
max_depth = max_depth,
random_state = 123
)
# Error de train
modelo.fit(X_train, y_train)
predicciones = modelo.predict(X = X_train)
rmse = root_mean_squared_error(
y_true = y_train,
y_pred = predicciones
)
train_scores.append(rmse)
# Error de validación cruzada
scores = cross_val_score(
estimator = modelo,
X = X_train,
y = y_train,
scoring = 'neg_root_mean_squared_error',
cv = 5,
n_jobs = multiprocessing.cpu_count() - 1
)
# Se agregan los scores de cross_val_score() y se pasa a positivo
cv_scores.append(-1*scores.mean())
# Gráfico con la evolución de los errores
fig, ax = plt.subplots(figsize=(5, 3))
ax.plot(max_depths, train_scores, label="train scores")
ax.plot(max_depths, cv_scores, label="cv scores")
ax.plot(max_depths[np.argmin(cv_scores)], min(cv_scores),
marker='o', color = "red", label="min score")
ax.set_ylabel("root_mean_squared_error")
ax.set_xlabel("max_depth")
ax.set_title("Evolución del cv-error vs profundidad árboles")
plt.legend();
print(f"Valor óptimo de max_depth: {max_depths[np.argmin(cv_scores)]}")
Valor óptimo de max_depth: 5

Grid search¶
Aunque el análisis individual de los hiperparámetros es útil para entender su impacto en el modelo e identificar rangos de interés, la búsqueda final no debe hacerse de forma secuencial, ya que cada hiperparámetro interacciona con los demás. Es preferible recurrir a grid search o random search para analizar varias combinaciones de hiperparámetros. Puede encontrarse más información sobre las estrategias de búsqueda en Machine learning con Python y Scikit-learn.
Cuando los recursos computacionales (o tiempo) son limitados, es aconsejable seguir una de las siguientes estrategias para identificar los hiperparámetros óptimos de un modelo Gradient Boosting:
Fijar el número de árboles y optimizar el learning rate.
Fijar el learning rate y añadir tantos árboles como sea necesario pero activando la parada temprana para evitar overfitting.
Una vez identificados los valores de estos hiperparámetros, se refinan el resto.
💡 Tip
Cuando los recursos computacionales (o tiempo) son limitados, es aconsejable seguir una de las siguientes estrategias para identificar los hiperparámetros óptimos de un modelo Gradient Boosting:
Fijar el número de árboles y optimizar el learning rate.
Fijar el learning rate y añadir tantos árboles como sea necesario pero activando la parada temprana para evitar overfitting.
Grid Search basado en validación cruzada¶
En la siguiente búsqueda de hiperparámetros, se emplea la estrategia de no incluir el número de árboles como hiperparámetro en el grid. En su lugar, se utiliza por defecto un número muy elevado y se activa la parada temprana.
En las implementaciones nativas de scikit-learn (GradientBoosting y HistGradientBoosting), el conjunto de validación para la parada temprana se extrae automáticamente de los datos de entrenamiento utilizados en cada ajuste, por lo que puede integrarse directamente en el GridSearchCV() o RandomizedSearchCV().
# Grid de hiperparámetros evaluados
# ==============================================================================
param_grid = {'loss' : ['squared_error', 'absolute_error'],
'learning_rate' : [0.001, 0.01, 0.1],
'max_depth' : [3, 5, 10, 20],
'l2_regularization': [0, 1, 10]
}
# Búsqueda por grid search con validación cruzada
# ==============================================================================
grid = GridSearchCV(
estimator = HistGradientBoostingRegressor(
max_iter = 1000,
random_state = 123,
# Activación de la parada temprana
early_stopping = True,
validation_fraction = 0.1,
n_iter_no_change = 10,
tol = 1e-7,
scoring = 'loss',
),
param_grid = param_grid,
scoring = 'neg_root_mean_squared_error',
n_jobs = multiprocessing.cpu_count() - 1,
cv = RepeatedKFold(n_splits=3, n_repeats=1, random_state=123),
refit = True,
verbose = 0,
return_train_score = True
)
grid.fit(X = X_train, y = y_train)
# Resultados
# ==============================================================================
resultados = pd.DataFrame(grid.cv_results_)
resultados.filter(regex = '(param.*|mean_t|std_t)') \
.drop(columns = 'params') \
.sort_values('mean_test_score', ascending = False) \
.head(4)
| param_l2_regularization | param_learning_rate | param_loss | param_max_depth | mean_test_score | std_test_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|
| 43 | 1 | 0.1 | squared_error | 20 | -3.669431 | 0.448214 | -2.337653 | 0.595595 |
| 42 | 1 | 0.1 | squared_error | 10 | -3.669431 | 0.448214 | -2.337653 | 0.595595 |
| 17 | 0 | 0.1 | squared_error | 5 | -3.716610 | 0.384398 | -2.406267 | 0.574598 |
| 18 | 0 | 0.1 | squared_error | 10 | -3.771660 | 0.454215 | -2.478086 | 0.451284 |
# Mejores hiperparámetros por validación cruzada
# ==============================================================================
print("----------------------------------------")
print("Mejores hiperparámetros encontrados (cv)")
print("----------------------------------------")
print(grid.best_params_, ":", grid.best_score_, grid.scoring)
----------------------------------------
Mejores hiperparámetros encontrados (cv)
----------------------------------------
{'l2_regularization': 1, 'learning_rate': 0.1, 'loss': 'squared_error', 'max_depth': 10} : -3.6694305864579335 neg_root_mean_squared_error
⚠️ Warning
Aunque se ha indicado que n_estimator = 1000`, debido a la activación de la parada temprana, el entrenamiento puede haberse detenido antes.
# Número de árboles del modelo final (early stopping)
# ==============================================================================
print(f"Número de árboles del modelo: {grid.best_estimator_.n_iter_}")
Número de árboles del modelo: 50
Una vez identificados los mejores hiperparámetros, se reentrena el modelo indicando los valores óptimos en sus argumentos. Si en el GridSearchCV() se indica refit=True, este reentrenamiento se hace automáticamente y el modelo resultante se encuentra almacenado en .best_estimator_.
# Error de test del modelo final
# ==============================================================================
modelo_final = grid.best_estimator_
predicciones = modelo_final.predict(X = X_test)
rmse = root_mean_squared_error(
y_true = y_test,
y_pred = predicciones
)
print(f"El error (rmse) de test es: {rmse}")
El error (rmse) de test es: 4.125497064570422
Tras optimizar los hiperparámetros, se consigue reducir el error rmse del modelo de 5.2 a 4.1. Las predicciones del modelo final se alejan en promedio 4.1 unidades (4100 dólares) del valor real.
Importancia de predictores¶
HistGradientBoostingRegressor ya no incorpora la importancia de los predictores basándose en la pureza de nodos por las evidencias de que esta forma de calcular la importancia está altamente influenciada por el número de predictores utilizados. En su lugar, se recomienda el uso del método de permutación.
importancia = permutation_importance(
estimator = modelo_final,
X = X_train,
y = y_train,
n_repeats = 5,
scoring = 'neg_root_mean_squared_error',
n_jobs = multiprocessing.cpu_count() - 1,
random_state = 123
)
# Se almacenan los resultados (media y desviación) en un dataframe
df_importancia = pd.DataFrame(
{k: importancia[k] for k in ['importances_mean', 'importances_std']}
)
df_importancia['feature'] = X_train.columns
df_importancia.sort_values('importances_mean', ascending=False)
| importances_mean | importances_std | feature | |
|---|---|---|---|
| 11 | 5.446604 | 0.288384 | LSTAT |
| 5 | 4.903891 | 0.176809 | RM |
| 7 | 0.856145 | 0.080632 | DIS |
| 4 | 0.847798 | 0.065242 | NOX |
| 0 | 0.465227 | 0.030585 | CRIM |
| 6 | 0.335038 | 0.046341 | AGE |
| 10 | 0.308566 | 0.026022 | PTRATIO |
| 9 | 0.230401 | 0.033951 | TAX |
| 2 | 0.155159 | 0.013061 | INDUS |
| 8 | 0.093236 | 0.014850 | RAD |
| 1 | 0.002374 | 0.000775 | ZN |
| 3 | 0.000000 | 0.000000 | CHAS |
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(figsize=(5, 4))
sorted_idx = importancia.importances_mean.argsort()
ax.boxplot(
importancia.importances[sorted_idx].T,
vert = False,
labels = datos.drop(columns = "MEDV").columns[sorted_idx]
)
ax.set_title('Importancia de los predictores (train)')
ax.set_xlabel('Incremento del error tras la permutación')
fig.tight_layout();

Ambas estrategias identifican LSTAT y RM como los predictores más influyentes, acorde a los datos de entrenamiento.
XGBoost y LighGBM¶
XGBoost¶
A diferencia de las implementaciones nativas de scikit-learn, en XGBoost y LightGBM, el conjunto de validación para la parada temprana, no se extrae automáticamente. Para poder integrar la parada temprana con el GridSearchCV() o RandomizedSearchCV() y que no haya observaciones que participan en ambos procesos, se tiene que separar manualmente un conjunto de validación del de entrenamiento.
# Grid de hiperparámetros evaluados
# ==============================================================================
param_grid = {'max_depth' : [3, 5, 10, 20],
'subsample' : [0.5, 1],
'learning_rate' : [0.001, 0.01, 0.1],
'booster' : ['gbtree']
}
# Crear conjunto de validación
# ==============================================================================
np.random.seed(123)
idx_validacion = np.random.choice(
X_train.shape[0],
size=int(X_train.shape[0]*0.1), #10% de los datos de entrenamiento
replace=False
)
X_val = X_train.iloc[idx_validacion, :].copy()
y_val = y_train.iloc[idx_validacion].copy()
X_train_grid = X_train.reset_index(drop = True).drop(idx_validacion, axis = 0).copy()
y_train_grid = y_train.reset_index(drop = True).drop(idx_validacion, axis = 0).copy()
# XGBoost necesita pasar los paramétros específicos del entrenamiento al llamar
# al método .fit()
fit_params = {
"eval_set": [(X_val, y_val)],
"verbose": False
}
# Búsqueda por grid search con validación cruzada
# ==============================================================================
grid = GridSearchCV(
estimator = XGBRegressor(
n_estimators = 1000,
early_stopping_rounds = 5,
eval_metric = "rmse",
random_state = 123
),
param_grid = param_grid,
scoring = 'neg_root_mean_squared_error',
n_jobs = multiprocessing.cpu_count() - 1,
cv = RepeatedKFold(n_splits=3, n_repeats=1, random_state=123),
refit = True,
verbose = 0,
return_train_score = True
)
grid.fit(X = X_train_grid, y = y_train_grid, **fit_params)
# Resultados
# ==============================================================================
resultados = pd.DataFrame(grid.cv_results_)
resultados.filter(regex = '(param.*|mean_t|std_t)') \
.drop(columns = 'params') \
.sort_values('mean_test_score', ascending = False) \
.head(4)
| param_booster | param_learning_rate | param_max_depth | param_subsample | mean_test_score | std_test_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|
| 18 | gbtree | 0.10 | 5 | 0.5 | -3.780975 | 0.601978 | -1.222699 | 0.670224 |
| 22 | gbtree | 0.10 | 20 | 0.5 | -3.814522 | 0.676036 | -1.098650 | 0.380221 |
| 20 | gbtree | 0.10 | 10 | 0.5 | -3.889702 | 0.649555 | -1.098182 | 0.620475 |
| 14 | gbtree | 0.01 | 20 | 0.5 | -3.893593 | 0.603064 | -1.705033 | 0.405872 |
# Mejores hiperparámetros por validación cruzada
# ==============================================================================
print("----------------------------------------")
print("Mejores hiperparámetros encontrados (cv)")
print("----------------------------------------")
print(grid.best_params_, ":", grid.best_score_, grid.scoring)
# Número de árboles del modelo final (early stopping)
# ==============================================================================
n_arboles_incluidos = len(grid.best_estimator_.get_booster().get_dump())
print(f"Número de árboles incluidos en el modelo: {n_arboles_incluidos}")
----------------------------------------
Mejores hiperparámetros encontrados (cv)
----------------------------------------
{'booster': 'gbtree', 'learning_rate': 0.1, 'max_depth': 5, 'subsample': 0.5} : -3.7809748896923665 neg_root_mean_squared_error
Número de árboles incluidos en el modelo: 34
# Error de test del modelo final
# ==============================================================================
modelo_final = grid.best_estimator_
predicciones = modelo_final.predict(X_test)
rmse = root_mean_squared_error(
y_true = y_test,
y_pred = predicciones
)
print(f"El error (rmse) de test es: {rmse}")
El error (rmse) de test es: 3.7360376054022693
LightGBM¶
Para este ejemplo, se incorpora en la búsqueda el número de árboles en lugar de activar la parada temprana.
# Grid de hiperparámetros evaluados
# =================================================================-1,=============
param_grid = {'n_estimators' : [100, 500, 1000],
'max_depth' : [3, 5, 10, 20],
'subsample' : [0.5, 1],
'learning_rate' : [0.001, 0.01, 0.1],
'boosting_type' : ['gbdt']
}
# Búsqueda por grid search con validación cruzada
# ==============================================================================
grid = GridSearchCV(
estimator = LGBMRegressor(random_state=123, verbose=-1),
param_grid = param_grid,
scoring = 'neg_root_mean_squared_error',
n_jobs = multiprocessing.cpu_count() - 1,
cv = RepeatedKFold(n_splits=3, n_repeats=1, random_state=123),
refit = True,
verbose = 0,
return_train_score = True
)
grid.fit(X = X_train_grid, y = y_train_grid)
# Resultados
# ==============================================================================
resultados = pd.DataFrame(grid.cv_results_)
resultados.filter(regex = '(param.*|mean_t|std_t)') \
.drop(columns = 'params') \
.sort_values('mean_test_score', ascending = False) \
.head(4)
| param_boosting_type | param_learning_rate | param_max_depth | param_n_estimators | param_subsample | mean_test_score | std_test_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|---|
| 50 | gbdt | 0.1 | 3 | 500 | 0.5 | -3.803656 | 0.772055 | -1.071614 | 0.104883 |
| 51 | gbdt | 0.1 | 3 | 500 | 1.0 | -3.803656 | 0.772055 | -1.071614 | 0.104883 |
| 60 | gbdt | 0.1 | 10 | 100 | 0.5 | -3.805746 | 0.764872 | -1.773668 | 0.183944 |
| 61 | gbdt | 0.1 | 10 | 100 | 1.0 | -3.805746 | 0.764872 | -1.773668 | 0.183944 |
# Mejores hiperparámetros por validación cruzada
# ==============================================================================
print("----------------------------------------")
print("Mejores hiperparámetros encontrados (cv)")
print("----------------------------------------")
print(grid.best_params_, ":", grid.best_score_, grid.scoring)
----------------------------------------
Mejores hiperparámetros encontrados (cv)
----------------------------------------
{'boosting_type': 'gbdt', 'learning_rate': 0.1, 'max_depth': 3, 'n_estimators': 500, 'subsample': 0.5} : -3.8036560847224155 neg_root_mean_squared_error
# Error de test del modelo final
# ==============================================================================
modelo_final = grid.best_estimator_
predicciones = modelo_final.predict(X = X_test,)
rmse = root_mean_squared_error(
y_true = y_test,
y_pred = predicciones
)
print(f"El error (rmse) de test es: {rmse}")
El error (rmse) de test es: 4.1326656546767015
Ejemplo clasificación¶
Librerías¶
Las librerías utilizadas en este documento son:
# Tratamiento de datos
# ==============================================================================
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
# Preprocesado y modelado
# ==============================================================================
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import OrdinalEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RepeatedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.inspection import permutation_importance
import xgboost
from xgboost import XGBClassifier
import lightgbm
from lightgbm import LGBMClassifier
import multiprocessing
# Configuración warnings
# ==============================================================================
import warnings
print(f"Versión de scikit-learn: {sklearn.__version__}")
print(f"Versión de pandas: {pd.__version__}")
print(f"Versión de numpy: {np.__version__}")
print(f"Versión de xgboost: {xgboost.__version__}")
print(f"Versión de lightgbm: {lightgbm.__version__}")
Versión de scikit-learn: 1.7.2 Versión de pandas: 2.3.3 Versión de numpy: 2.2.6 Versión de xgboost: 3.0.5 Versión de lightgbm: 4.6.0
Datos¶
El set de datos Carseats, original del paquete de R ISLR y accesible en Python a través de statsmodels.datasets.get_rdataset, contiene información sobre la venta de sillas infantiles en 400 tiendas distintas. Para cada una de las 400 tiendas se han registrado 11 variables. Se pretende generar un modelo de clasificación que permita predecir si una tienda tiene ventas altas (Sales > 8) o bajas (Sales <= 8) en función de todas las variables disponibles.
✏️ Note
Listado de todos los set de datos disponibles en Rdatasets
# Lectura de datos
# ==============================================================================
carseats = sm.datasets.get_rdataset("Carseats", "ISLR")
datos = carseats.data
datos.head(3)
| Sales | CompPrice | Income | Advertising | Population | Price | ShelveLoc | Age | Education | Urban | US | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9.50 | 138 | 73 | 11 | 276 | 120 | Bad | 42 | 17 | Yes | Yes |
| 1 | 11.22 | 111 | 48 | 16 | 260 | 83 | Good | 65 | 10 | Yes | Yes |
| 2 | 10.06 | 113 | 35 | 10 | 269 | 80 | Medium | 59 | 12 | Yes | Yes |
Como Sales es una variable continua y el objetivo del estudio es clasificar las tiendas según si venden mucho o poco, se crea una nueva variable binaria (0, 1) llamada ventas_altas.
datos['ventas_altas'] = np.where(datos.Sales > 8, 0, 1)
# Una vez creada la nueva variable respuesta se descarta la original
datos = datos.drop(columns = 'Sales')
Ajuste del modelo y optimización de hiperparámetros¶
Se ajusta un modelo de clasificación empleando como variable respuesta ventas_altas y como predictores todas las variables disponibles.
✏️ Note
A diferencia del ejemplo previo, en estos datos se incluyen variables categóricas. Aunque todas las librerías empleadas en este documento son capaces de manejar variables categóricas de manera nativa, en algunos modelos o implementaciones podría ser necesario aplicar la técnica de one-hot-encoding. La sección titulada Variables Categóricas proporciona un detallado análisis del uso de estas variables con cada una de las bibliotecas.
# División de los datos en train y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = 'ventas_altas'),
datos['ventas_altas'],
random_state = 123
)
# Ordinal encoding de las variables categóricas
# ==============================================================================
# Se identifica el nobre de las columnas categóricas
cat_cols = X_train.select_dtypes(include=['object', 'category']).columns.to_list()
# HistGradientBoostingClassifier requiere que los valores de categoría se codifiquen
# en [0, n_unique_categories - 1], por lo que se utiliza un OrdinalEncoder para
# preprocesar los datos. Los valores missing se codifican como -1. Si una nueva
# categoría se encuentra en el conjunto de test se codifica como -1.
cat_cols = X_train.select_dtypes(exclude=[np.number]).columns.tolist()
preprocessor = make_column_transformer(
(
OrdinalEncoder(
dtype=int,
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-1
),
cat_cols
),
remainder="passthrough",
verbose_feature_names_out=False,
).set_output(transform="pandas")
# Una vez que se ha definido el objeto ColumnTransformer, con el método fit()
# se aprenden las transformaciones con los datos de entrenamiento y se aplican a
# los dos conjuntos con transform(). Ambas operaciones a la vez con fit_transform().
X_train_prep = preprocessor.fit_transform(X_train)
X_test_prep = preprocessor.transform(X_test)
X_train_prep.info()
<class 'pandas.core.frame.DataFrame'> Index: 300 entries, 170 to 365 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 ShelveLoc 300 non-null int64 1 Urban 300 non-null int64 2 US 300 non-null int64 3 CompPrice 300 non-null int64 4 Income 300 non-null int64 5 Advertising 300 non-null int64 6 Population 300 non-null int64 7 Price 300 non-null int64 8 Age 300 non-null int64 9 Education 300 non-null int64 dtypes: int64(10) memory usage: 25.8 KB
Si bien HistGradientBoostingClassifier tiene valores por defecto para sus hiperparámetros, no se puede saber de antemano si estos son los más adecuados, la forma de identificarlos es mediante el uso de estrategias de validación, por ejemplo validación cruzada. Cabe tener en cuenta que, cuando se busca el valor óptimo de un hiperparámetro con dos métricas distintas, el resultado obtenido raramente es el mismo. Lo importante es que ambas métricas identifiquen las mismas regiones de interés.
Aunque el análisis individual de los hiperparámetros es útil para entender su impacto en el modelo e identificar rangos de interés, la búsqueda final no debe hacerse de forma secuencial, ya que cada hiperparámetro interacciona con los demás. Es preferible recurrir a grid search o random search para analizar varias combinaciones de hiperparámetros. Puede encontrarse más información sobre las estrategias de búsqueda en Machine learning con Python y Scikit-learn.
Grid Search basado en validación cruzada¶
# Grid de hiperparámetros evaluados
# ==============================================================================
param_grid = {
'max_iter' : [50, 100, 500, 1000],
'max_depth' : [3, 5, 10, 20],
'learning_rate' : [0.001, 0.01, 0.1]
}
# Búsqueda por grid search con validación cruzada
# ==============================================================================
grid = GridSearchCV(
estimator = HistGradientBoostingClassifier(random_state=123, categorical_features=cat_cols),
param_grid = param_grid,
scoring = 'accuracy',
n_jobs = multiprocessing.cpu_count() - 1,
cv = RepeatedKFold(n_splits=3, n_repeats=1, random_state=123),
refit = True,
verbose = 0,
return_train_score = True
)
grid.fit(X = X_train_prep, y = y_train)
# Resultados
# ==============================================================================
resultados = pd.DataFrame(grid.cv_results_)
resultados.filter(regex = '(param*|mean_t|std_t)') \
.drop(columns = 'params') \
.sort_values('mean_test_score', ascending = False) \
.head(4)
| param_learning_rate | param_max_depth | param_max_iter | mean_test_score | std_test_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|---|---|
| 38 | 0.1 | 5 | 500 | 0.843333 | 0.054365 | 1.0 | 0.0 |
| 34 | 0.1 | 3 | 500 | 0.836667 | 0.061824 | 1.0 | 0.0 |
| 39 | 0.1 | 5 | 1000 | 0.836667 | 0.049889 | 1.0 | 0.0 |
| 43 | 0.1 | 10 | 1000 | 0.833333 | 0.062361 | 1.0 | 0.0 |
# Mejores hiperparámetros por validación cruzada
# ==============================================================================
print("----------------------------------------")
print("Mejores hiperparámetros encontrados (cv)")
print("----------------------------------------")
print(grid.best_params_, ":", grid.best_score_, grid.scoring)
----------------------------------------
Mejores hiperparámetros encontrados (cv)
----------------------------------------
{'learning_rate': 0.1, 'max_depth': 5, 'max_iter': 500} : 0.8433333333333333 accuracy
Una vez identificados los mejores hiperparámetros, se reentrena el modelo indicando los valores óptimos en sus argumentos. Si en el GridSearchCV() se indica refit=True, este reentrenamiento se hace automáticamente y
el modelo resultante se encuentra almacenado en .best_estimator_.
modelo_final = grid.best_estimator_
modelo_final
HistGradientBoostingClassifier(categorical_features=['ShelveLoc', 'Urban',
'US'],
max_depth=5, max_iter=500, random_state=123)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| loss | 'log_loss' | |
| learning_rate | 0.1 | |
| max_iter | 500 | |
| max_leaf_nodes | 31 | |
| max_depth | 5 | |
| min_samples_leaf | 20 | |
| l2_regularization | 0.0 | |
| max_features | 1.0 | |
| max_bins | 255 | |
| categorical_features | ['ShelveLoc', 'Urban', ...] | |
| monotonic_cst | None | |
| interaction_cst | None | |
| warm_start | False | |
| early_stopping | 'auto' | |
| scoring | 'loss' | |
| validation_fraction | 0.1 | |
| n_iter_no_change | 10 | |
| tol | 1e-07 | |
| verbose | 0 | |
| random_state | 123 | |
| class_weight | None |
Predicción y evaluación del modelo¶
Por último, se evalúa la capacidad predictiva del modelo final empleando el conjunto de test.
# Error de test del modelo final
# ==============================================================================
predicciones = modelo_final.predict(X = X_test_prep)
predicciones[:10]
array([0, 1, 0, 0, 0, 0, 1, 1, 1, 1])
mat_confusion = confusion_matrix(
y_true = y_test,
y_pred = predicciones
)
accuracy = accuracy_score(
y_true = y_test,
y_pred = predicciones,
normalize = True
)
print("Matriz de confusión")
print("-------------------")
print(mat_confusion)
print("")
print(f"El accuracy de test es: {100 * accuracy} %")
fig, ax = plt.subplots(figsize=(3, 3))
ConfusionMatrixDisplay(mat_confusion).plot(ax=ax);
Matriz de confusión ------------------- [[38 12] [ 5 45]] El accuracy de test es: 83.0 %

Tras optimizar los hiperparámetros, se consigue un porcentaje de acierto del 83%.
Predicción de probabilidades¶
La mayoría de implementaciones de Gradient Boosting Trees, entre ellas la de scikit-learn, permiten predecir probabilidades cuando se trata de problemas de clasificación. Es importante entender cómo se calculan estos valores para interpretarlos y utilizarlos correctamente.
En el ejemplo anterior, al aplicar .predict() se devuelve $1$ (ventas elevadas) o $0$ (ventas bajas) para cada observación de test. Sin embargo, no se dispone de ningún tipo de información sobre la seguridad con la que el modelo realiza esta asignación. Con .predict_proba(), en lugar de una clasificación, se obtiene la probabilidad con la que el modelo considera que cada observación puede pertenecer a cada una de las clases.
# Predicción de probabilidades
# ==============================================================================
predicciones = modelo_final.predict_proba(X = X_test_prep)
predicciones[:5, :]
array([[8.35357869e-01, 1.64642131e-01],
[2.15360382e-01, 7.84639618e-01],
[9.99999727e-01, 2.73092904e-07],
[8.22826079e-01, 1.77173921e-01],
[9.99996651e-01, 3.34906400e-06]])
El resultado de .predict_proba() es un array con una fila por observación y tantas columnas como clases tenga la variable respuesta. El valor de la primera columna se corresponde con la probabilidad, acorde al modelo, de que la observación pertenezca a la clase 0, y así sucesivamente. El valor de probabilidad mostrado para cada predicción se corresponde con la fracción de observaciones de cada clase en los nodos terminales a los que ha llegado la observación predicha en el conjunto de los árboles.
Por defecto, .predict() asigna cada nueva observación a la clase con mayor probabilidad (en caso de empate se asigna de forma aleatoria). Sin embargo, este no tiene por qué ser el comportamiento deseado en todos los casos.
# Clasificación empleando la clase de mayor probabilidad
# ==============================================================================
df_predicciones = pd.DataFrame(data=predicciones, columns=['0', '1'])
df_predicciones['clasificacion_default_0.5'] = np.where(df_predicciones['0'] > df_predicciones['1'], 0, 1)
df_predicciones.head(3)
| 0 | 1 | clasificacion_default_0.5 | |
|---|---|---|---|
| 0 | 0.835358 | 1.646421e-01 | 0 |
| 1 | 0.215360 | 7.846396e-01 | 1 |
| 2 | 1.000000 | 2.730929e-07 | 0 |
Supóngase el siguiente escenario: la campaña de navidad se aproxima y los propietarios de la cadena quieren duplicar el stock de artículos en aquellas tiendas de las que se preve que tengan ventas elevadas. Como el transporte de este material hasta las tiendas supone un coste elevado, el director quiere limitar esta estrategia únicamente a tiendas para las que se tenga mucha seguridad de que van conseguir muchas ventas.
Si se dispone de las probabilidades, se puede establecer un punto de corte concreto, por ejemplo, considerando únicamente como clase $1$ (ventas altas) aquellas tiendas cuya predicción para esta clase sea superior al 0.9 (90%). De esta forma, la clasificación final se ajusta mejor a las necesidades del caso de uso.
# Clasificación final empleando un threshold de 0.8 para la clase 1.
# ==============================================================================
df_predicciones['clasificacion_custom_0.8'] = np.where(df_predicciones['1'] > 0.9, 1, 0)
df_predicciones[df_predicciones['clasificacion_custom_0.8']!=df_predicciones['clasificacion_default_0.5']] \
.head(3)
| 0 | 1 | clasificacion_default_0.5 | clasificacion_custom_0.8 | |
|---|---|---|---|---|
| 1 | 0.215360 | 0.784640 | 1 | 0 |
| 33 | 0.227356 | 0.772644 | 1 | 0 |
| 95 | 0.117894 | 0.882106 | 1 | 0 |
¿Hasta que punto se debe de confiar en estas probabilidades?
Es muy importante tener en cuenta la diferencia entre la "visión" que tiene el modelo del mundo y el mundo real. Todo lo que sabe un modelo sobre el mundo real es lo que ha podido aprender de los datos de entrenamiento y, por lo tanto, tiene una "visión" limitada. Por ejemplo, supóngase que, en los datos de entrenamiento, todas las tiendas que están en zona urbana Urban='Yes' tienen ventas altas independientemente del valor que tomen el resto de predictores. Cuando el modelo trate de predecir una nueva observación, si esta está en zona urbana, clasificará a la tienda como ventas elevadas con un 100% de seguridad. Sin embargo, esto no significa que sea inequivocamente cierto, podría haber tiendas en zonas úrbanas que no tienen ventas elevadas pero, al no estar presentes en los datos de entrenamiento, el modelo no contempla esta posibilidad.
Teniendo en cuenta todo esto, hay que considerar las probabilidades generadas por el modelo como la seguridad que tiene este, desde su visión limitada, al realizar las predicciones. Pero no como la probailidad en el mundo real de que así lo sea.
Importancia de predictores¶
Importancia por permutación¶
importancia = permutation_importance(
estimator = modelo_final,
X = X_train_prep,
y = y_train,
n_repeats = 5,
scoring = 'accuracy',
n_jobs = multiprocessing.cpu_count() - 1,
random_state = 123
)
# Se almacenan los resultados (media y desviación) en un dataframe
df_importancia = pd.DataFrame(
{k: importancia[k] for k in ['importances_mean', 'importances_std']}
)
df_importancia['feature'] = X_train_prep.columns
df_importancia.sort_values('importances_mean', ascending=False)
| importances_mean | importances_std | feature | |
|---|---|---|---|
| 7 | 0.249333 | 0.019137 | Price |
| 0 | 0.206667 | 0.013499 | ShelveLoc |
| 3 | 0.133333 | 0.017385 | CompPrice |
| 5 | 0.088667 | 0.011470 | Advertising |
| 8 | 0.044667 | 0.007180 | Age |
| 4 | 0.030000 | 0.006325 | Income |
| 6 | 0.003333 | 0.002108 | Population |
| 1 | 0.000000 | 0.000000 | Urban |
| 2 | 0.000000 | 0.000000 | US |
| 9 | 0.000000 | 0.000000 | Education |
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(figsize=(3.5, 4))
df_importancia = df_importancia.sort_values('importances_mean', ascending=True)
ax.barh(
df_importancia['feature'],
df_importancia['importances_mean'],
xerr=df_importancia['importances_std'],
align='center',
alpha=0
)
ax.plot(
df_importancia['importances_mean'],
df_importancia['feature'],
marker="D",
linestyle="",
alpha=0.8,
color="r"
)
ax.set_title('Importancia de los predictores (train)')
ax.set_xlabel('Incremento del error tras la permutación');

Acorde a los datos de entrenamiento, se identifican Price y ShelveLoc como los predictores más influyentes, seguidos de cerca por CompPrice y Advertising.
Variables categóricas¶
En el campo del aprendizaje automático (machine learning), las variables categóricas desempeñan un papel fundamental a la hora de determinar la capacidad predictiva de un modelo. Las variables categóricas son aquellas que pueden tomar un número limitado de valores, como el color, el género o la ubicación. Si bien estas variables pueden proporcionar información útil sobre los patrones y relaciones que hay en los datos, presentan retos únicos.
Uno de estos retos es la necesidad de convertir valores categóricos en valores numéricos que puedan ser procesados por algoritmos de aprendizaje automático. Otro reto aparece al tratar con categorías poco frecuentes, que pueden dar lugar a modelos sesgados. Si una variable categórica tiene un gran número de categorías, pero algunas de ellas aparecen con poca frecuencia en los datos, el modelo puede no ser capaz de aprender de ellas dando lugar a predicciones sesgadas y resultados inexactos. A pesar de estas dificultades, las variables categóricas siguen siendo un componente esencial en muchos casos de uso. Cuando se codifican y manejan adecuadamente, pueden proporcionar información muy útil para lograr mejores predicciones.
Algunos modelos como los de XGBoost, LightGBM, CatBoost e HistGradientBoosting, son capaces de tratar predictores categóricos de forma nativa, pero asumen que las categorías son números enteros que empiezan por 0 hasta el número de categorías [0, 1, ..., n_categories-1]. En la práctica, las variables categóricas no suelen estar codificadas como números, sino con cadenas de caracteres (strings), por lo que es necesario un paso intermedio de transformación. Hay dos opciones:
Convertir las columnas con variables categóricas al tipo
pandas.category. En pandas, la estructura de datos de una columna de tipocategoryconsiste en una matriz de categorías y una matriz de valores enteros (códigos) que apuntan al valor real de la matriz de categorías. Es decir, internamente es una matriz numérica con un mapeo que relaciona cada valor con una categoría. Los modelos son capaces de identificar automáticamente las columnas de tipocategoryy acceder a sus códigos internos. Este enfoque es aplicable a XGBoost, LightGBM y CatBoost.Preprocesar las columnas categóricas con un
OrdinalEncoderpara transformar sus valores en números enteros e indicar explícitamente que las columnas deben tratarse como categóricas. Si no se realiza este último paso, los modelos tratarán las variables como si fueran numéricas.
⚠️ Warning
Cuando se despliegan modelos en producción, se recomienda encarecidamente evitar el uso de la detección automática basada en columnas de tipo category de Pandas. Aunque Pandas proporciona una codificación interna para estas columnas, no es consistente entre diferentes conjuntos de datos y puede variar dependiendo de las categorías presentes en cada uno. Por lo tanto, es crucial ser consciente de este problema y tomar las medidas adecuadas para garantizar la coherencia en la codificación de las variables categóricas al desplegar los modelos en producción. Se pueden encontrar más detalles sobre este problema en este github issue y en stackoverflow.
✏️ Note
Los siguientes ejemplos pretenden mostrar cómo incorporar variables categóricas a los modelos, el resto de configuraciones se dejan por defecto.
LightGBM¶
LightGBM permite tanto la detección automática basada en el tipo de las columnas como indicar qué columnas se deben tratar como categorías (siempre que hayan sido previamente codificadas como número esteros). A continuación, se muestran las dos aproximaciones.
Codificar las categorías como números enteros y especificar explícitamente los nombres de las variables categóricas (recomendado)
# Lectura de datos
# ==============================================================================
carseats = sm.datasets.get_rdataset("Carseats", "ISLR")
datos = carseats.data
datos['ventas_altas'] = np.where(datos.Sales > 8, 0, 1)
# Una vez creada la nueva variable respuesta se descarta la original
datos = datos.drop(columns = 'Sales')
# División de los datos en train y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = 'ventas_altas'),
datos['ventas_altas'],
random_state = 123
)
# Ordinal encoding de las variables categóricas
# ==============================================================================
# Se utiliza un OrdinalEncoder para preprocesar los datos. Los valores missing se
# codifican como -1. Si una nueva categoría se encuentra en el conjunto de test
# se codifica como -1.
cat_cols = X_train.select_dtypes(exclude=[np.number]).columns.tolist()
preprocessor = make_column_transformer(
(
OrdinalEncoder(
dtype=int,
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-1
),
cat_cols
),
remainder="passthrough",
verbose_feature_names_out=False,
).set_output(transform="pandas")
# Una vez que se ha definido el objeto ColumnTransformer, con el método fit()
# se aprenden las transformaciones con los datos de entrenamiento y se aplican a
# los dos conjuntos con transform(). Ambas operaciones a la vez con fit_transform().
X_train_prep = preprocessor.fit_transform(X_train)
X_test_prep = preprocessor.transform(X_test)
# Entreanmiento del modelo
# ==============================================================================
modelo = LGBMClassifier(
n_estimators = 100,
random_state = 123,
verbose = -1
)
# En los modelos LGBMRegressor y LGBMClassifier, el argumento categorical_feature
# se especifica en el método fit y no durante su inicialización.
modelo.fit(X = X_train_prep, y = y_train, categorical_feature=cat_cols)
LGBMClassifier(random_state=123, verbose=-1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| boosting_type | 'gbdt' | |
| num_leaves | 31 | |
| max_depth | -1 | |
| learning_rate | 0.1 | |
| n_estimators | 100 | |
| subsample_for_bin | 200000 | |
| objective | None | |
| class_weight | None | |
| min_split_gain | 0.0 | |
| min_child_weight | 0.001 | |
| min_child_samples | 20 | |
| subsample | 1.0 | |
| subsample_freq | 0 | |
| colsample_bytree | 1.0 | |
| reg_alpha | 0.0 | |
| reg_lambda | 0.0 | |
| random_state | 123 | |
| n_jobs | None | |
| importance_type | 'split' | |
| verbose | -1 |
El UserWarning indica que se han incluido predictores categóricos. Se puede suprimir este warning utilizando warnings.filterwarnings('ignore') y activarlas de nuevo con warnings.filterwarnings('default') o warnings.resetwarnings().
# Predicciones
# ==============================================================================
predicciones = modelo.predict(X = X_test_prep)
predicciones
array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1,
0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1])
Detección automática variables categóricas
# Lectura de datos
# ==============================================================================
carseats = sm.datasets.get_rdataset("Carseats", "ISLR")
datos = carseats.data
datos['ventas_altas'] = np.where(datos.Sales > 8, 0, 1)
# Una vez creada la nueva variable respuesta se descarta la original
datos = datos.drop(columns = 'Sales')
# Convertir las variables no numéricas a tipo category
# ==============================================================================
cat_cols = X_train.select_dtypes(exclude=[np.number]).columns.tolist()
datos[cat_cols] = datos[cat_cols].astype('category')
# División de los datos en train y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = 'ventas_altas'),
datos['ventas_altas'],
random_state = 123
)
# Entreanmiento del modelo
# ==============================================================================
modelo = LGBMClassifier(
n_estimators = 100,
random_state = 123,
verbose = -1
)
# En los modelos LGBMRegressor y LGBMClassifier, el argumento categorical_feature
# se especifica en el método fit y no durante su inicialización.
modelo.fit(X = X_train, y = y_train, categorical_feature='auto')
LGBMClassifier(random_state=123, verbose=-1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| boosting_type | 'gbdt' | |
| num_leaves | 31 | |
| max_depth | -1 | |
| learning_rate | 0.1 | |
| n_estimators | 100 | |
| subsample_for_bin | 200000 | |
| objective | None | |
| class_weight | None | |
| min_split_gain | 0.0 | |
| min_child_weight | 0.001 | |
| min_child_samples | 20 | |
| subsample | 1.0 | |
| subsample_freq | 0 | |
| colsample_bytree | 1.0 | |
| reg_alpha | 0.0 | |
| reg_lambda | 0.0 | |
| random_state | 123 | |
| n_jobs | None | |
| importance_type | 'split' | |
| verbose | -1 |
# Predicciones
# ==============================================================================
predicciones = modelo.predict(X = X_test)
predicciones
array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1,
0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1])
Scikit-learn HistogramGradientBoosting¶
Scikit-learn no incluye una detección automática de variables categóricas basada en el tipo de las columnas. En su lugar, es necesario indicar qué columnas son categóricas durante la instanciación del modelo utilizando el argumento categorical_feature. Además, los valores de estas columnas deben estar codificados como números enteros.
# Lectura de datos
# ==============================================================================
carseats = sm.datasets.get_rdataset("Carseats", "ISLR")
datos = carseats.data
datos['ventas_altas'] = np.where(datos.Sales > 8, 0, 1)
# Una vez creada la nueva variable respuesta se descarta la original
datos = datos.drop(columns = 'Sales')
# División de los datos en train y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = 'ventas_altas'),
datos['ventas_altas'],
random_state = 123
)
# Ordinal encoding de las variables categóricas
# ==============================================================================
# OrdinalEncoder para preprocesar los datos. Los valores missing se codifican
# como -1. Si una nueva categoría se encuentra en el conjunto de test se codifica
# como -1.
cat_cols = X_train.select_dtypes(exclude=[np.number]).columns.tolist()
preprocessor = make_column_transformer(
(
OrdinalEncoder(
dtype=int,
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-1
),
cat_cols
),
remainder="passthrough",
verbose_feature_names_out=False,
).set_output(transform="pandas")
# Una vez que se ha definido el objeto ColumnTransformer, con el método fit()
# se aprenden las transformaciones con los datos de entrenamiento y se aplican a
# los dos conjuntos con transform(). Ambas operaciones a la vez con fit_transform().
X_train_prep = preprocessor.fit_transform(X_train)
X_test_prep = preprocessor.transform(X_test)
# Entreanmiento del modelo
# ==============================================================================
modelo = HistGradientBoostingClassifier(
max_iter = 100,
categorical_features = cat_cols,
random_state = 123
)
modelo.fit(X = X_train_prep, y = y_train)
HistGradientBoostingClassifier(categorical_features=['ShelveLoc', 'Urban',
'US'],
random_state=123)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| loss | 'log_loss' | |
| learning_rate | 0.1 | |
| max_iter | 100 | |
| max_leaf_nodes | 31 | |
| max_depth | None | |
| min_samples_leaf | 20 | |
| l2_regularization | 0.0 | |
| max_features | 1.0 | |
| max_bins | 255 | |
| categorical_features | ['ShelveLoc', 'Urban', ...] | |
| monotonic_cst | None | |
| interaction_cst | None | |
| warm_start | False | |
| early_stopping | 'auto' | |
| scoring | 'loss' | |
| validation_fraction | 0.1 | |
| n_iter_no_change | 10 | |
| tol | 1e-07 | |
| verbose | 0 | |
| random_state | 123 | |
| class_weight | None |
# Predicciones
# ==============================================================================
predicciones = modelo.predict(X = X_test_prep)
predicciones
array([1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0,
0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1])
XGBoost¶
XGBoost permite tanto la detección automática basada en el tipo de las columnas como indicar qué columnas se deben tratar como categorías (siempre que hayan sido previamente codificadas como número esteros). A diferencia de LightGBM o scikit-learn, XGBoost no proporciona una opción para indicar los nombres de las variables categóricas. En su lugar, los tipos de variables se especifican pasando una lista al argumento feature_types, donde 'c' denota variables categóricas y 'q' numéricas. Además, el argumento enable_categorical debe ser True y tree_method 'hist'.
Codificar las categorías como números enteros y especificar explícitamente las variables categóricas (recomendado)
# Lectura de datos
# ==============================================================================
carseats = sm.datasets.get_rdataset("Carseats", "ISLR")
datos = carseats.data
datos['ventas_altas'] = np.where(datos.Sales > 8, 0, 1)
# Una vez creada la nueva variable respuesta se descarta la original
datos = datos.drop(columns = 'Sales')
# División de los datos en train y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = 'ventas_altas'),
datos['ventas_altas'],
random_state = 123
)
# Ordinal encoding de las variables categóricas
# ==============================================================================
# Se utiliza un OrdinalEncoder para preprocesar los datos. Los valores missing se
# codifican como -1. Si una nueva categoría se encuentra en el conjunto de test
# se codifica como -1.
cat_cols = X_train.select_dtypes(exclude=[np.number]).columns.tolist()
preprocessor = make_column_transformer(
(
OrdinalEncoder(
dtype=int,
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-1
),
cat_cols
),
remainder="passthrough",
verbose_feature_names_out=False,
).set_output(transform="pandas")
# Una vez que se ha definido el objeto ColumnTransformer, con el método fit()
# se aprenden las transformaciones con los datos de entrenamiento y se aplican a
# los dos conjuntos con transform(). Ambas operaciones a la vez con fit_transform().
X_train_prep = preprocessor.fit_transform(X_train)
X_test_prep = preprocessor.transform(X_test)
# Se crea una lista para identificar si cada columna es categórica ('c') o numérica ('n')
feature_types = ['c' if col in cat_cols else 'q' for col in X_train_prep.columns]
feature_types
['c', 'c', 'c', 'q', 'q', 'q', 'q', 'q', 'q', 'q']
# Entreanmiento del modelo
# ==============================================================================
modelo = XGBClassifier(
n_estimators = 100,
tree_method='hist',
enable_categorical=True,
feature_types=feature_types,
random_state = 123
)
modelo.fit(X = X_train_prep, y = y_train)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=True, eval_metric=None,
feature_types=['c', 'c', 'c', 'q', 'q', 'q', 'q', 'q', 'q', 'q'],
feature_weights=None, gamma=None, grow_policy=None,
importance_type=None, interaction_constraints=None,
learning_rate=None, max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None, max_depth=None,
max_leaves=None, min_child_weight=None, missing=nan,
monotone_constraints=None, multi_strategy=None, n_estimators=100,
n_jobs=None, num_parallel_tree=None, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| objective | 'binary:logistic' | |
| base_score | None | |
| booster | None | |
| callbacks | None | |
| colsample_bylevel | None | |
| colsample_bynode | None | |
| colsample_bytree | None | |
| device | None | |
| early_stopping_rounds | None | |
| enable_categorical | True | |
| eval_metric | None | |
| feature_types | ['c', 'c', ...] | |
| feature_weights | None | |
| gamma | None | |
| grow_policy | None | |
| importance_type | None | |
| interaction_constraints | None | |
| learning_rate | None | |
| max_bin | None | |
| max_cat_threshold | None | |
| max_cat_to_onehot | None | |
| max_delta_step | None | |
| max_depth | None | |
| max_leaves | None | |
| min_child_weight | None | |
| missing | nan | |
| monotone_constraints | None | |
| multi_strategy | None | |
| n_estimators | 100 | |
| n_jobs | None | |
| num_parallel_tree | None | |
| random_state | 123 | |
| reg_alpha | None | |
| reg_lambda | None | |
| sampling_method | None | |
| scale_pos_weight | None | |
| subsample | None | |
| tree_method | 'hist' | |
| validate_parameters | None | |
| verbosity | None |
# Predicciones
# ==============================================================================
predicciones = modelo.predict(X = X_test_prep)
predicciones
array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1,
0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1])
Detección automática variables categóricas
# Lectura de datos
# ==============================================================================
carseats = sm.datasets.get_rdataset("Carseats", "ISLR")
datos = carseats.data
datos['ventas_altas'] = np.where(datos.Sales > 8, 0, 1)
# Una vez creada la nueva variable respuesta se descarta la original
datos = datos.drop(columns = 'Sales')
# Convertir las variables no numéricas a tipo category
# ==============================================================================
cat_cols = X_train.select_dtypes(exclude=[np.number]).columns.tolist()
datos[cat_cols] = datos[cat_cols].astype('category')
# División de los datos en train y test
# ==============================================================================
X_train, X_test, y_train, y_test = train_test_split(
datos.drop(columns = 'ventas_altas'),
datos['ventas_altas'],
random_state = 123
)
# Entreanmiento del modelo
# ==============================================================================
modelo = XGBClassifier(
n_estimators = 100,
tree_method='hist',
enable_categorical=True,
random_state = 123
)
modelo.fit(X = X_train, y = y_train)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=True, eval_metric=None, feature_types=None,
feature_weights=None, gamma=None, grow_policy=None,
importance_type=None, interaction_constraints=None,
learning_rate=None, max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None, max_depth=None,
max_leaves=None, min_child_weight=None, missing=nan,
monotone_constraints=None, multi_strategy=None, n_estimators=100,
n_jobs=None, num_parallel_tree=None, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| objective | 'binary:logistic' | |
| base_score | None | |
| booster | None | |
| callbacks | None | |
| colsample_bylevel | None | |
| colsample_bynode | None | |
| colsample_bytree | None | |
| device | None | |
| early_stopping_rounds | None | |
| enable_categorical | True | |
| eval_metric | None | |
| feature_types | None | |
| feature_weights | None | |
| gamma | None | |
| grow_policy | None | |
| importance_type | None | |
| interaction_constraints | None | |
| learning_rate | None | |
| max_bin | None | |
| max_cat_threshold | None | |
| max_cat_to_onehot | None | |
| max_delta_step | None | |
| max_depth | None | |
| max_leaves | None | |
| min_child_weight | None | |
| missing | nan | |
| monotone_constraints | None | |
| multi_strategy | None | |
| n_estimators | 100 | |
| n_jobs | None | |
| num_parallel_tree | None | |
| random_state | 123 | |
| reg_alpha | None | |
| reg_lambda | None | |
| sampling_method | None | |
| scale_pos_weight | None | |
| subsample | None | |
| tree_method | 'hist' | |
| validate_parameters | None | |
| verbosity | None |
# Predicciones
# ==============================================================================
predicciones = modelo.predict(X = X_test)
predicciones
array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1,
0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1])
Gradient Boosting Monótono¶
Los modelos basados en Gradient Boosting son capaces de aprender interacciones complejas entre los predictores y la variable respuesta. Esto puede convertirse en una desventaja cuando, debido al ruido de los datos, el modelo aprende comportamientos que no reflejan la realidad. Una estrategia para evitar este tipo de problemas consiste en forzar a que la relación de cada predictor (numérico) con la variable respuesta sea monótona, es decir tenga siempre la misma dirección (positiva o negativa).
Aunque el algoritmo es más complejo, a grandes rasgos, se consigue una relación monótona respecto a una determinada variable si, además de otros criterios, solo se permiten divisiones de nodos cuando el valor medio del nodo hijo derecho es mayor que el nodo hijo izquierdo (o a la inversa si se quiere una relación negativa).
x = np.linspace(start=0, stop=15, num=200)
y = x**2 + 10
fig, ax = plt.subplots(figsize=(5, 3))
ax.scatter(x, y, color = "black")
ax.set_title('Relación verdadera Y~X');

Supóngase ahora que los datos contienen cierto ruido y que, por lo tanto, la relación observada no es exactamente la verdadera.
y = y + np.random.normal(loc=0, scale=20, size=y.shape)
fig, ax = plt.subplots(figsize=(5, 3))
ax.scatter(x, y, color = "black")
ax.set_title('Relación con ruido Y~X');

Si se ajusta un modelo de gradient boosting a estos datos el modelo asume como verdadero parte del ruido, lo que conlleva que, en determinadas zonas, considere negativa la relación entre X e Y.
# Modelo Gradient Boosting Trees
modelo_gbm = HistGradientBoostingRegressor(max_iter=500, max_depth=5)
modelo_gbm.fit(x.reshape(-1, 1), y)
# Predicciones
prediccion_gbm = modelo_gbm.predict(x.reshape(-1, 1))
# Gráfico
fig, ax = plt.subplots(figsize=(5, 3))
ax.scatter(x, y, color = "black")
ax.plot(x, prediccion_gbm, color = "red", label = "predicción", linewidth=3)
ax.set_title("Modelo Gradient Boosting")
plt.legend();

Si se dispone de suficiente conocimiento sobre el problema en cuestión como para saber que la relación entre predictor y variable es monótona, forzar el comportamiento puede resultar en un modelo con mayor capacidad de generalizar a nuevas observaciones. Las clases HistGradientBoosting tiene un argumento llamado monotonic_cst que recibe una lista de longitud igual al número de predictores del modelo, con valores +1 para monotonía positiva, -1 para negativa y 0 para no restricciones. Esta misma característica tambien esta dispobible en XGBoost, LightGBM y H2O.
Se repite el ajuste del modelo, esta vez forzando la monotonía positiva.
# Modelo Gradient Boosting Trees con
modelo_gbm_monotonic = HistGradientBoostingRegressor(max_iter=500, max_depth=5, monotonic_cst=[1])
modelo_gbm_monotonic.fit(x.reshape(-1, 1), y)
# Predicciones
prediccion_gbm_monotonic = modelo_gbm_monotonic.predict(x.reshape(-1, 1))
# Gráfico
fig, ax = plt.subplots(figsize=(5, 3))
ax.scatter(x, y, color = "black")
ax.plot(x, prediccion_gbm_monotonic, color = "red", label = "predicción", linewidth=3)
ax.set_title("Modelo Gradient Boosting monotónico")
plt.legend();

Esta vez, aunque la relación y~x no es constante, si es siempre positiva.
Extrapolación con modelos Gradient Boosting Trees¶
Una límitación importante de los árboles de regresióna, y por lo tanto de Gradient Boosting Trees es que no extrapolan fuera del rango de entrenamiento. Cuando se aplica el modelo a una nueva observación, cuyo valor o valores de los predictores son superiores o inferiores a los observados en el entrenamiento, la predicción siempre es la media del nodo más cercano, independientemente de cuanto se aleje el valor. Vease el siguiente ejemplo en el que se entrenan dos modelos, un modelo lineal y un arbol de regresión, y luego se predicen valores de $X$ fuera del rango de entrenamiento.
# Datos simulados
# ==============================================================================
X = np.linspace(0, 150, 100)
y = (X + 100) + np.random.normal(loc=0.0, scale=5.0, size=X.shape)
X_train = X[(X>=50) & (X<100)]
y_train = y[(X>=50) & (X<100)]
X_test_inf = X[X < 50]
y_test_inf = y[X < 50]
X_test_sup = X[X >= 100]
y_test_sup = y[X >= 100]
fig, ax = plt.subplots(figsize=(6, 3))
ax.plot(X_train, y_train, c='black', linestyle='dashed', label = "Datos train")
ax.axvspan(50, 100, color='gray', alpha=0.2, lw=0)
ax.plot(X_test_inf, y_test_inf, c='blue', linestyle='dashed', label = "Datos test")
ax.plot(X_test_sup, y_test_sup, c='blue', linestyle='dashed')
ax.set_title("Datos de entrenamiento y test")
plt.legend();

# Modelo lineal
modelo_lineal = LinearRegression()
modelo_lineal.fit(X_train.reshape(-1, 1), y_train)
# Modelo Gradient Boosting Trees
modelo_gbm = GradientBoostingRegressor()
modelo_gbm.fit(X_train.reshape(-1, 1), y_train)
# Predicciones
prediccion_lineal = modelo_lineal.predict(X.reshape(-1, 1))
prediccion_gbm = modelo_gbm.predict(X.reshape(-1, 1))
fig, ax = plt.subplots(figsize=(6, 3))
ax.plot(X_train, y_train, c='black', linestyle='dashed', label = "Datos train")
ax.axvspan(50, 100, color='gray', alpha=0.2, lw=0)
ax.plot(X_test_inf, y_test_inf, c='blue', linestyle='dashed', label = "Datos test")
ax.plot(X_test_sup, y_test_sup, c='blue', linestyle='dashed')
ax.plot(X, prediccion_lineal, c='firebrick',
label = "Prediccion modelo lineal")
ax.plot(X, prediccion_gbm, c='orange',
label = "Prediccion modelo gbm")
ax.set_title("Extrapolación de un modelo lineal y un modelo de Gradient Boosting")
plt.legend();

La gráfica muestra que, con el modelo Gradient Boosting Trees, el valor predicho fuera del rango de entrenamiento, es el mismo independientemente de cuanto se aleje X. Una estrategia que permite que los modelos basados en árboles extrapolen es ajustar un modelo lineal en cada nodo terminal, pero esto no está disponible en Scikit-learn.
Variables dummy (one-hot-encoding) en Gradient Boosting Trees¶
Los modelos basados en árboles de decisión, entre ellos Gradient Boosting Trees, son capaces de utilizar predictores categóricos en su forma natural sin necesidad de convertirlos en variables dummy mediante one-hot-encoding. Sin embargo, en la práctica, depende de la implementación que tenga la librería o software utilizado. Esto tiene impacto directo en la estructura de los árboles generados y, en consecuencia, en los resultados predictivos del modelo y en la importancia calculada para los predictores.
El libro Feature Engineering and Selection A Practical Approach for Predictive Models By Max Kuhn, Kjell Johnson, los autores realizan un experimento en el que se comparan modelos entrenados con y sin one-hot-encoding en 5 sets de datos distintos, los resultados muestran que:
No hay una diferencia clara en términos de capacidad predictiva de los modelos. Solo en el caso de stocastic gradient boosting se apecian ligeras diferencias en contra de aplicar one-hot-encoding.
El entrenamiento de los modelos tarda en promedio 2.5 veces más cuando se aplica one-hot-encoding. Esto es debido al aumento de dimensionalidad al crear las nuevas variables dummy, obligando a que el algoritmo tenga que analizar muchos más puntos de división.
En base a los resultados obtenidos, los autores recomiendan no aplicar one-hot-encoding. Solo si los resultados son buenos, probar entonces si se mejoran al crear las variables dummy.
Otra comparación detallada puede encontrarse en Are categorical variables getting lost in your random forests? By Nick Dingwall, Chris Potts, donde los resultados muestran que:
Al convertir una variable categórica en múltiples variables dummy su importancia queda diluida, dificultando que el modelo pueda aprender de ella y perdiendo así capacidad predictiva. Este efecto es mayor cuantos más niveles tiene la variable original.
Al diluir la importancia de los predictores categóricos, estos tienen menos probabilidad de ser seleccionada por el modelo, lo que desvirtúa las métricas que miden la importancia de los predictores.
Comparación Gradient Boosting y Random Forest¶
Random Forest se compara con frecuencia con otro algoritmo basado en árboles, Gradient Boosting Trees. Ambos métodos son muy potentes y la superioridad de uno u otro depende del problema al que se apliquen. Algunos aspectos a tener en cuenta son:
Gracias al out-of-bag error, el método de Random Forest no necesita recurrir a validación cruzada para la optimización de sus hiperparámetros. Esto puede ser una ventaja muy importante cuando los requerimientos computacionales son limitantes. Esta característica también está presente en Stochastic Gradient Boosting pero no en AdaBoost y Gradient Boosting.
Random forest tiene menos hiperparámetros, lo que hace más sencillo su correcta implementación.
Si existe una proporción alta de predictores irrelevantes, Random Forest puede verse perjudicado, sobre todo a medida que se reduce el número de predictores ($m$) evaluados. Supóngase que, de 100 predictores, 90 de ellos no aportan información (son ruidos). Si el hiperparámetro $m$ es igual a 3 (en cada división se evalúan 3 predictores aleatorios), es muy probable que los 3 predictores seleccionados sean de los que no aportan nada. Aun así, el algoritmo seleccionará el mejor de ellos, incorporándolo al modelo. Cuanto mayor sea el porcentaje de predictores no relevantes, mayor la frecuencia con la que esto ocurre, por lo que los árboles que forman el Random Forest contendrán predictores irrelevantes. Como consecuencia, se reduce su capacidad predictiva. En el caso de Gradient Boosting Trees, siempre se evalúan todos los predictores, por lo que los no relevantes se ignoran.
En Random Forest, cada modelo que forma el ensemble es independiente del resto, esto permite que el entrenamiento sea paralelizable.
Random Forest no sufre problemas de overfitting por muchos árboles que se agreguen.
Si se realiza una buena optimización de hiperparámetros, Gradient Boosting Trees suele obtener resultados superiores.
El tamaño final de los modelos Gradient Boosting Trees suele ser menor.
Gradient Boosting Trees suele ser más rápido prediciendo.
Información de sesión¶
import session_info
session_info.show(html=False)
----- lightgbm 4.6.0 matplotlib 3.10.7 numpy 2.2.6 pandas 2.3.3 session_info v1.0.1 sklearn 1.7.2 statsmodels 0.14.5 xgboost 3.0.5 ----- IPython 9.6.0 jupyter_client 8.6.3 jupyter_core 5.9.1 ----- Python 3.13.9 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 19:16:10) [GCC 11.2.0] Linux-6.14.0-35-generic-x86_64-with-glibc2.39 ----- Session information updated at 2025-11-18 11:24
Bibliografía¶
Introduction to Statistical Learning, Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani
Applied Predictive Modeling Max Kuhn, Kjell Johnson
T.Hastie, R.Tibshirani, J.Friedman. The Elements of Statistical Learning. Springer, 2009
Bradley Efron and Trevor Hastie. 2016. Computer Age Statistical Inference: Algorithms, Evidence, and Data Science (1st. ed.). Cambridge University Press, USA.
Chen, Tianqi & Guestrin, Carlos. (2016). XGBoost: A Scalable Tree Boosting System. 785-794. [DOI: 10.1145/2939672.2939785](http://dmlc.cs.washington.edu/data/pdf/XGBoostArxiv.pdf)
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Gradient Boosting con Python por Joaquín Amat Rodrigo, disponible bajo una licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://www.cienciadedatos.net/documentos/py09_gradient_boosting_python.html
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊



Este documento creado por Joaquín Amat Rodrigo tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.