Más sobre ciencia de datos en: cienciadedatos.net
- Regresión lineal con Python
- Regresión lineal múltiple con Python
- Regresión logística con Python
- Regularización Ridge, Lasso y Elastic Net con Python
- Machine learning con Python y Scikitlearn
- Árboles de decisión con Python: regresión y clasificación
- Random Forest con Python y Scikit-learn
- Gradient Boosting con Python y Scikit-learn
- Gradient Boosting probabilístico con Python
- Máquinas de Vector Soporte (SVM)
- Redes neuronales con Python
- Análisis de componentes principales PCA
- Clustering
- Detección de anomalías con PCA
- Detección de anomalías con autoencoders
- Detección de anomalías con Gaussian Mixture Models
- Detección de anomalías con Isolation Forest
- Análisis de texto (text mining) con Python
- Reglas de asociación
Introducción¶
La predicción de una variable continua $Y$ en función de uno o varios predictores $X$ es un problema fundamental en el aprendizaje supervisado, abordable mediante múltiples métodos de Machine Learning y estadística clásica. Ya sea asumiendo relaciones lineales o permitiendo complejas interacciones no lineales, el objetivo estándar de la mayoría de estos algoritmos es estimar el valor promedio de la variable respuesta condicionado a los predictores: $E[Y|X=x]$. A este enfoque se le conoce como estimación puntual (point estimate).
Si bien conocer la esperanza matemática (la media) es crucial, este estadístico resume la información de tal modo que ignora otras características de la distribución de $Y$ que pueden ser vitales para la toma de decisiones, especialmente conocer qué ocurre en los extremos de la distribución. Es aquí donde interviene la regresión de cuantiles (quantile regression).
El cuantil de orden $\tau$ (donde $0 < \tau < 1$) de una distribución es el valor que divide los datos de tal forma que una proporción $\tau$ de la población es menor o igual a dicho valor. Por ejemplo, el cuantil 0.36 deja el 36% de los valores por debajo, y el cuantil 0.50 corresponde a la mediana. En la práctica, con muestras finitas, la proporción observada por debajo del plano de regresión estimado será aproximadamente $\tau$, ajustándose mejor cuanto mayor sea el tamaño de la muestra.
Aunque la matemática subyacente en los modelos de regresión cuantílica es distinta (se minimizan desviaciones absolutas ponderadas en lugar de errores al cuadrado), la lectura de los resultados es análoga: se obtienen coeficientes que estiman el efecto de cada predictor, pero ahora sobre un cuantil específico de la variable respuesta, no sobre su media. Esta flexibilidad permite modelar la influencia de los predictores a lo largo de toda la distribución.
La limitación de predecir la media: un ejemplo práctico
Imaginemos un escenario simplificado sobre el consumo eléctrico de una ciudad. Supongamos que el consumo medio se mantiene constante durante todo el día en 15 MWh. Sin embargo, la dispersión de este consumo no es constante (fenómeno conocido como heterocedasticidad): de madrugada el consumo es muy estable, pero en horas pico oscila ampliamente.
Si entrenamos un modelo de regresión estándar, este predecirá correctamente un valor cercano a 15 MWh tanto para las 02:00h como para las 10:00h. El modelo "acierta" el promedio, pero falla en contar la historia completa.
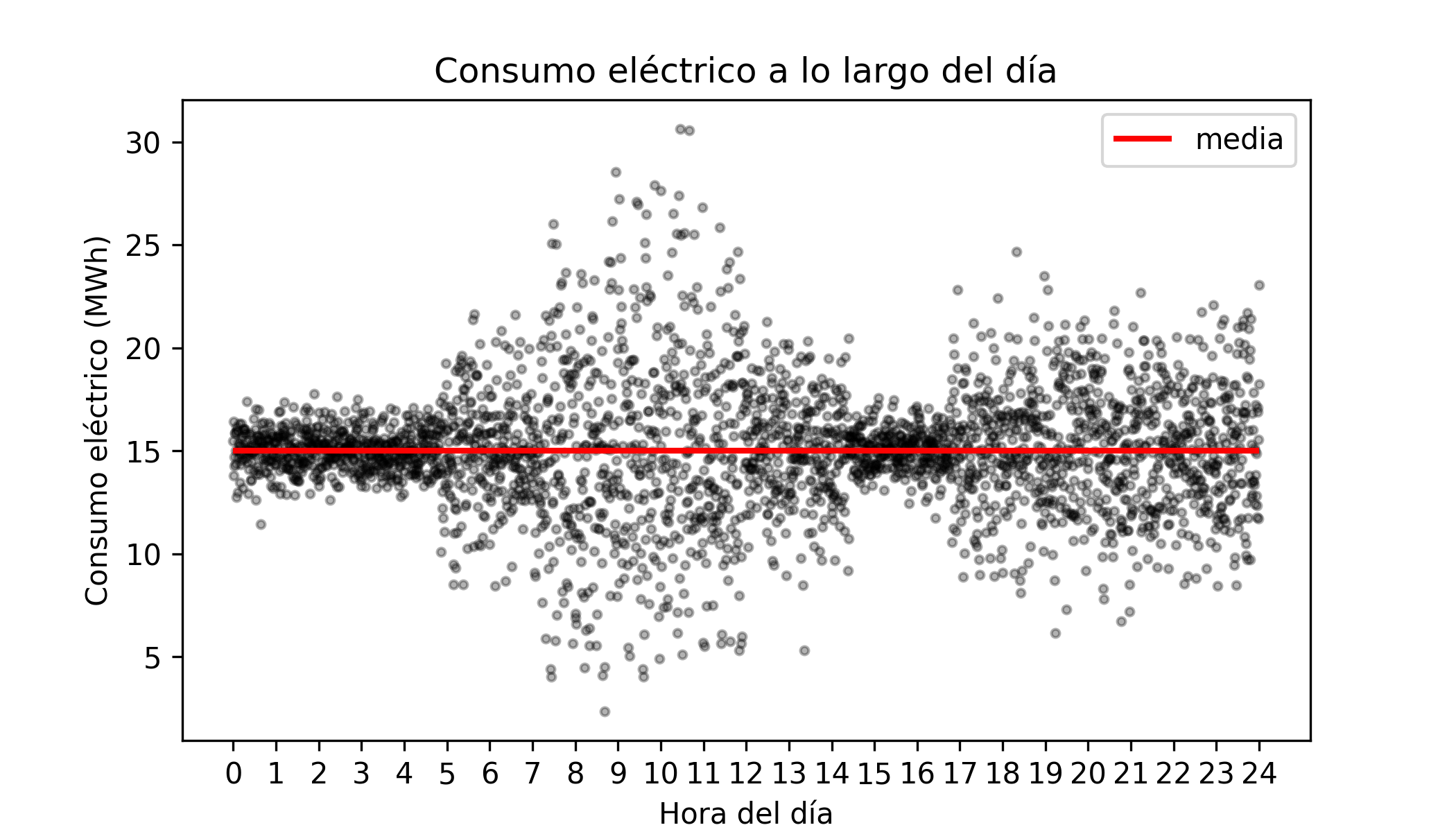
Supongamos ahora que la compañía eléctrica debe garantizar el suministro incluso si la demanda sube un 50% sobre la media (llegando a 22.5 MWh). Mantener esa capacidad de reserva es costoso.
Un modelo basado en la media dirá que el consumo esperado es 15 MWh a ambas horas, ocultando el riesgo.
En la realidad, a las 02:00h la probabilidad de llegar a 22.5 MWh es casi nula (podemos ahorrar costes).
A las 10:00h, debido a la alta varianza, alcanzar ese pico es una posibilidad real (necesitamos la reserva).
Para responder a preguntas sobre riesgos, extremos y dispersión, necesitamos ir más allá del promedio y emplear la regresión de cuantiles (quantile regression). Esta técnica permite modelar la influencia de los predictores sobre cualquier parte de la distribución de la variable respuesta, no solo su centro.
El cuantil de orden $\tau$ (donde $0 < \tau < 1$) de una variable aleatoria es el valor que divide su distribución de tal forma que una proporción $\tau$ de la población se encuentra por debajo de dicho valor.
El cuantil $\tau = 0.5$ corresponde a la mediana (deja el 50% de los datos por debajo).
El cuantil $\tau = 0.9$ indica un valor que solo es superado por el 10% de los casos (ideal para estimar picos de demanda).
Al predecir múltiples cuantiles (por ejemplo, el 0.1, 0.5 y 0.9) condicionados a los predictores, obtenemos una visión completa del comportamiento de la variable respuesta. Esto permite:
Generar intervalos de predicción: acotando entre qué valores es probable que oscile la realidad.
Robustez: modelar la mediana ($\tau=0.5$) es mucho más robusto frente a valores atípicos (outliers) que modelar la media.
Detección de heterocedasticidad: identificar en qué regiones del espacio de los predictores la incertidumbre es mayor.
Detección de anomalías: identificar observaciones que caen fuera de los rangos cuantílicos esperados.
En definitiva, mientras que la regresión clásica nos dice qué esperar en promedio, la regresión de cuantiles nos permite entender qué es posible esperar en los extremos, proporcionando una herramienta para la gestión de riesgos y la toma de decisiones informada.
A lo largo de este documento se muestra cómo entrenar modelos de regresión cuantílica lineales y no lineales utilizando Python.
💡 Tip
Este documento forma parte de una serie sobre machine learning probabilístico.
Modelos lineales¶
El siguiente ejemplo muestra cómo utilizar modelos de regresión lineales para predecir cuantiles.
Librerías¶
# Procesado y manipulación de datos
# ==============================================================================
import pandas as pd
import numpy as np
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
import matplotlib.cm as cm
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
import seaborn as sns
# Modelos
# ==============================================================================
import statsmodels.api as sm
from statsmodels.regression.quantile_regression import QuantReg
from sklearn.linear_model import QuantileRegressor, LinearRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer, mean_pinball_loss
from sklearn.ensemble import HistGradientBoostingRegressor
from catboost import CatBoostRegressor
# Configuración de warnings
# ==============================================================================
import warnings
warnings.filterwarnings('once')
Datos¶
Se emplea un conjunto de datos simulados en el que la varianza no es constante (heterocedasticidad), sino que aumenta a medida que lo hace el valor de la variable predictora $X$.
# Datos
# ==============================================================================
X = np.linspace(0, 100, 100)
varianza = 0.1 + 0.05 * X
b_0 = 6
b_1 = 0.1
rng = np.random.default_rng(seed=12345)
error = rng.normal(loc=0, scale=varianza, size=100)
y = b_0 + b_1 * X + error
datos = pd.DataFrame({"x": X, "y": y})
datos.head(3)
| x | y | |
|---|---|---|
| 0 | 0.000000 | 5.857617 |
| 1 | 1.010101 | 6.291208 |
| 2 | 2.020202 | 6.027008 |
# Gráfico con recta de regresión e intervalo de confianza
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
sns.regplot(
data=datos,
x="x",
y="y",
ci=95,
scatter_kws={"alpha": 0.7, 'color': "gray", "s": 25},
line_kws={"color": "blue", "linewidth": 2},
ax=ax
)
ax.set_ylim(0, 25)
ax.set_xlabel("x")
ax.set_ylabel("y")
plt.show()

La representación gráfica muestra una clara falta de homocedasticidad: la varianza de la variable respuesta aumenta conforme lo hace el valor del predictor. Esto supone una violación de los supuestos necesarios para la regresión lineal por mínimos cuadrados ordinarios, lo que limita la validez e interpretación de sus resultados.
A pesar de que la regresión lineal por mínimos cuadrados ordinarios proporciona una estimación no sesgada de la media y, en ese sentido, es la mejor estimación posible, para valores altos de $X$ (por ejemplo, $X$ = 75) los intervalos de confianza resultan excesivamente optimistas en comparación con lo que realmente reflejan los datos. Existen distintas estrategias para mitigar este problema, como la regresión por mínimos cuadrados ponderados (Weighted Least Squares). No obstante, esta sección se centra en la regresión por cuantiles.
Modelo¶
Existen varias librerías en Python que permiten ajustar modelos de regresión cuantílica. En este ejemplo se utilizan la clase QuantReg del paquete statsmodels y la clase QuantileRegressor del paquete sklearn.
Statsmodels
# Modelo de regresión lineal por cuantiles statsmodels
# ==============================================================================
modelo = QuantReg(datos['y'], sm.add_constant(datos['x']))
cuantil = 0.9
res = modelo.fit(q=cuantil)
print(res.summary())
QuantReg Regression Results
==============================================================================
Dep. Variable: y Pseudo R-squared: 0.5282
Model: QuantReg Bandwidth: 2.932
Method: Least Squares Sparsity: 8.690
Date: Mon, 02 Mar 2026 No. Observations: 100
Time: 19:21:44 Df Residuals: 98
Df Model: 1
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 6.5870 0.557 11.834 0.000 5.482 7.692
x 0.1436 0.010 14.889 0.000 0.124 0.163
==============================================================================
El summary() de un modelo devuelve los coeficientes de regresión de cada predictor junto con los correspondientes intervalos de confianza. Acorde al modelo, por cada unidad que se incrementa el predictor $X$, el cuantil 0.9 de la variable respuesta aumenta en promedio 0.14 unidades. Además, como el intervalo de confianza no contiene el 0, hay evidencias de que el predictor influye de forma significativa.
Empleando las estimaciones de intercept y del predictor se puede representar la recta de regresión del cuantil.
# Grafico con recta de regresión para un cuantil
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
ax.scatter(datos['x'], datos['y'], color='gray', alpha=0.7, s=25)
# Recta de regresión cuantílica = intercepto + pendiente * x
x_pred = np.linspace(datos['x'].min(), datos['x'].max(), 100)
y_pred = res.params['const'] + res.params['x'] * x_pred
ax.plot(x_pred, y_pred, color='red', linewidth=1, label=f'Regresión cuantílica (q={cuantil})')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend();

# Grafico con recta de regresión para varios cuantiles
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
ax.scatter(datos['x'], datos['y'], color='gray', alpha=0.7, s=25)
for cuantil in [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]:
res = modelo.fit(q=cuantil)
x_pred = np.linspace(datos['x'].min(), datos['x'].max(), 100)
y_pred = res.params['const'] + res.params['x'] * x_pred
ax.plot(x_pred, y_pred, color='firebrick', linewidth=1)
ax.set_xlabel('x')
ax.set_ylabel('y')
Text(0, 0.5, 'y')

Se puede observar que la pendiente de la recta de cada cuantil es distinta, lo que significa que el predictor X influye de forma distinta en cada cuantil de la variable respuesta. Para estudiar cómo varía esta influencia y su significancia, se puede representar la pendiente para cada cuantil.
# Pendiente de la recta de regresión de cada cuantil
# ==============================================================================
pendientes = []
cuantiles = np.arange(0.1, 1.0, 0.1)
# Pendiente de la recta de regresión por cuantiles
for cuantil in cuantiles:
res = modelo.fit(q=cuantil)
pendientes.append(res.params['x'])
# Pendiente de la recta de regresión por mínimos cuadrados ordinarios
modelo_ols = sm.OLS(datos['y'], sm.add_constant(datos['x']))
res_ols = modelo_ols.fit()
pendiente_ols = res_ols.params['x']
intervalo_ols = res_ols.conf_int(alpha=0.05).loc['x'].to_numpy()
fig, ax = plt.subplots(figsize=(6, 3))
ax.plot(cuantiles, pendientes, marker='o', color='darkblue', label='Pendiente por cuantiles')
ax.axhline(pendiente_ols, color='black', linestyle='--', label='Pendiente OLS')
ax.fill_between(cuantiles, intervalo_ols[0], intervalo_ols[1], color='gray', alpha=0.2, label='IC 95% OLS')
ax.set_xlabel('Cuantil')
ax.set_ylabel('Pendiente de la recta de regresión')
ax.set_title('Pendiente de la recta de regresión por cuantiles')
ax.legend()
plt.show()

Cada punto representa el coeficiente de regresión estimado de un cuantil. La línea discontinua negra es el coeficiente de regresión estimado para el predictor utilizando mínimos cuadrados ordinarios y la banda gris sombreada sus límites de confianza del 95%. Para este ejemplo, los cuantiles 0.1, 0.2, 0.3, 0.7, 0.8 y 0.9 se diferencian significativamente del valor obtenido por mínimos cuadrados ordinarios.
Scikit-learn
Este mismo tipo de modelo puede ser entrenado utilizando la clase QuantileRegressor del paquete sklearn. Esta implementación no proporciona un resumen estadístico del modelo, pero es útil para integrarlo en pipelines de machine learning. A continuación se muestra un ejemplo para el cuantil 0.9.
# Modelo de regresión lineal por cuantiles sklearn
# ==============================================================================
cuantil = 0.9
modelo = QuantileRegressor(quantile=cuantil, alpha=0)
modelo.fit(datos[['x']], datos['y'])
print(f'Intercepto : {modelo.intercept_}')
print(f'Coeficiente: {modelo.coef_[0]}')
Intercepto : 6.586959528616822 Coeficiente: 0.14360578177073394
Regresión cuantílica en distribuciones normales¶
Una de las propiedades de la distribución normal es que el valor de la media y mediana son iguales. Esto significa que el resultado de comparar las medias (regresión por mínimos cuadrados ordinarios) y medianas (regresión del cuantil 0.5) tiende a ser el mismo a medida que aumenta el tamaño muestral. Las pequeñas diferencias se deben a que cada estimador utiliza internamente un procedimiento de optimización distinto.
# Datos de una distribución normal con relación lineal
# ==============================================================================
np.random.seed(12345)
X_normal = np.random.uniform(0, 100, 500)
# y tiene una relación lineal con x más ruido normal (homocedastico)
y_normal = 5 + 0.5 * X_normal + np.random.normal(0, 5, 500)
datos_normal = pd.DataFrame({'x': X_normal, 'y': y_normal})
# Modelo de regresión cuantilica sklearn
# ==============================================================================
cuantil = 0.5
modelo_quantil = QuantileRegressor(quantile=cuantil, alpha=0)
modelo_quantil.fit(datos_normal[['x']], datos_normal['y'])
print('QuantileRegressor (q=0.5)')
print(f' Intercepto : {modelo_quantil.intercept_:.4f}')
print(f' Coeficiente: {modelo_quantil.coef_[0]:.4f}')
QuantileRegressor (q=0.5) Intercepto : 5.1464 Coeficiente: 0.4982
# Modelo de regresión por mínimos cuadrados ordinarios sklearn
# ==============================================================================
modelo_ols = LinearRegression()
modelo_ols.fit(datos_normal[['x']], datos_normal['y'])
print(f'LinearRegression (OLS)')
print(f' Intercepto : {modelo_ols.intercept_:.4f}')
print(f' Coeficiente: {modelo_ols.coef_[0]:.4f}')
LinearRegression (OLS) Intercepto : 5.1862 Coeficiente: 0.4965
# Grafico comparando las rectas de regresión
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
ax.scatter(datos_normal['x'], datos_normal['y'], color='gray', alpha=0.5, s=15)
# Predicciones con ambos modelos
x_pred_normal = np.linspace(datos_normal['x'].min(), datos_normal['x'].max(), 100).reshape(-1, 1)
y_pred_ols = modelo_ols.predict(x_pred_normal)
y_pred_quantil = modelo_quantil.predict(x_pred_normal)
# Rectas de regresión
ax.plot(x_pred_normal, y_pred_ols, color='blue', linewidth=2, label='LinearRegression (media)')
ax.plot(x_pred_normal, y_pred_quantil, color='red', linewidth=2, linestyle='--', label='QuantileRegressor (q=0.5, mediana)')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Comparación: OLS vs Regresión Cuantílica (q=0.5)')
ax.legend()
plt.show()

Modelos no lineales¶
Existen varios algoritmos de machine learning que permiten ajustar modelos de regresión cuantílica no lineales. Uno de los más utilizados, y que mejor rendimiento ofrece, es el Gradient Boosting. Todas las principales implementaciones en Python de este algoritmo (Scikit-learn, XGBoost, LightGBM y CatBoost) permiten entrenar modelos de regresión cuantílica.
Datos¶
El set de datos dbbmi (Fourth Dutch Growth Study, Fredriks et al. (2000a, 2000b)), disponible en el paquete de R gamlss.data, contiene información sobre la edad (age) e índice de masa corporal (bmi) de 7294 jóvenes holandeses de entre 0 y 20 años. El objetivo es entrenar un modelo capaz de predecir cuantiles del índice de masa corporal en función de la edad, ya que este es uno de los estándares empleados para detectar casos anómalos que pueden requerir atención médica.
# Lectura de datos
# ==============================================================================
url = (
'https://raw.githubusercontent.com/JoaquinAmatRodrigo/'
'Estadistica-machine-learning-python/master/data/dbbmi.csv'
)
datos = pd.read_csv(url)
datos.head(3)
| age | bmi | |
|---|---|---|
| 0 | 0.03 | 13.235289 |
| 1 | 0.04 | 12.438775 |
| 2 | 0.04 | 14.541775 |
# Gráfico distribución de los valores de bmi
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
ax.hist(datos.bmi, bins=30, density=True, color='#3182bd', alpha=0.8)
ax.set_title('Distribución valores índice masa corporal')
ax.set_xlabel('bmi')
ax.set_ylabel('densidad');

# Gráfico distribución índice masa corporal en función de la edad
# ==============================================================================
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(8, 4), sharey=True)
datos[datos.age <= 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[0]
)
axs[0].set_ylim([10, 30])
axs[0].set_title('Edad <= 2.5 años')
datos[datos.age > 2.5].plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = axs[1]
)
axs[1].set_title('Edad > 2.5 años')
fig.tight_layout()
plt.subplots_adjust(top = 0.85)
fig.suptitle('Distribución índice masa corporal en función de la edad', fontsize = 12);

Esta distribución muestra tres características importantes que hay que tener en cuenta a la hora de modelarla:
La relación entre la edad y el índice de masa corporal no es lineal ni constante. Tiene una relación positiva notable hasta los 0.25 años, después se estabiliza hasta los 10 años y vuelve a ascender notablemente de los 10 a los 20 años.
La varianza es heterogénea (heterocedasticidad), siendo esta menor en edades bajas y mayor en edades altas.
La distribución de la variable respuesta no es de tipo normal, muestra asimetría y una cola positiva.
Dadas estas características, se necesita un modelo que:
Sea capaz de aprender relaciones no lineales.
Sea capaz de modelar explícitamente la varianza en función de los predictores, ya que esta no es constante.
Sea capaz de aprender distribuciones asimétricas con una marcada cola positiva.
Modelo¶
Para este ejemplo se utiliza la implementación de Gradient Boosting de la librería scikit-learn, aunque el procedimiento es similar para las demás librerías mencionadas anteriormente.
# Modelo gradient boosting para cuantiles
# ==============================================================================
modelo = HistGradientBoostingRegressor(
loss='quantile',
quantile=0.9,
learning_rate=0.1,
max_iter=50,
max_depth=10,
min_samples_leaf=20,
random_state=12345
)
modelo.fit(X=datos[['age']], y=datos['bmi'])
HistGradientBoostingRegressor(loss='quantile', max_depth=10, max_iter=50,
quantile=0.9, random_state=12345)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| loss | 'quantile' | |
| quantile | 0.9 | |
| learning_rate | 0.1 | |
| max_iter | 50 | |
| max_leaf_nodes | 31 | |
| max_depth | 10 | |
| min_samples_leaf | 20 | |
| l2_regularization | 0.0 | |
| max_features | 1.0 | |
| max_bins | 255 | |
| categorical_features | 'from_dtype' | |
| monotonic_cst | None | |
| interaction_cst | None | |
| warm_start | False | |
| early_stopping | 'auto' | |
| scoring | 'loss' | |
| validation_fraction | 0.1 | |
| n_iter_no_change | 10 | |
| tol | 1e-07 | |
| verbose | 0 | |
| random_state | 12345 |
# Predicciones
# ==============================================================================
predicciones_q90 = modelo.predict(datos[['age']])
predicciones = pd.DataFrame({
'age': datos['age'],
'cuantil_90': predicciones_q90
}).sort_values('age').reset_index(drop=True)
predicciones.head(3)
| age | cuantil_90 | |
|---|---|---|
| 0 | 0.03 | 15.348746 |
| 1 | 0.04 | 15.348746 |
| 2 | 0.04 | 15.348746 |
# Gráfico predicciones cuantil 90
# ==============================================================================
fig, ax = plt.subplots(figsize=(8, 4))
datos.plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = ax
)
predicciones.plot(
x = 'age',
y = 'cuantil_90',
c = 'red',
kind = "line",
ax = ax
)
ax.set_title('Distribución índice masa corporal en función de la edad', fontsize = 12);

Optimización de hiperparámetros¶
Del mismo modo que el error cuadrático medio (MSE) se utiliza como función de coste para entrenar modelos que estiman el valor medio condicional, en la regresión cuantílica se necesita una función de coste específica que permita estimar cuantiles condicionales de la variable objetivo. La función más utilizada en este contexto es la pinball loss (también conocida como quantile loss). Para un conjunto de $n$ muestras, se define como:
$$ L_{\alpha}(y, \hat{y}) = \frac{1}{n} \sum_{i=1}^{n} \left[ \alpha \max(y_i - \hat{y}_i, 0) + (1 - \alpha)\max(\hat{y}_i - y_i, 0) \right] $$donde:
- $\alpha \in (0,1)$ es el cuantil objetivo (por ejemplo, 0.5 para la mediana),
- $y_i$ es el valor real,
- $\hat{y}_i$ es la predicción del cuantil $\alpha$.
La pinball loss introduce una penalización asimétrica del error:
- Si $y_i > \hat{y}_i$ (subestimación), el error se penaliza con peso $\alpha$.
- Si $y_i < \hat{y}_i$ (sobreestimación), el error se penaliza con peso $1 - \alpha$.
Esto implica que el coste depende directamente del cuantil que se esté estimando:
- Para cuantiles altos (por ejemplo, $\alpha = 0.9$), las subestimaciones se penalizan más fuertemente que las sobreestimaciones.
- Para cuantiles bajos (por ejemplo, $\alpha = 0.1$), ocurre lo contrario.
- Cuando $\alpha = 0.5$, la pérdida se vuelve simétrica y equivale a minimizar el error absoluto medio (MAE).
En la práctica, la optimización de hiperparámetros en modelos de regresión cuantílica debe realizarse minimizando la pinball loss correspondiente al cuantil objetivo. Algunos aspectos importantes a considerar:
- Los hiperparámetros óptimos pueden variar significativamente según el cuantil.
- No es recomendable reutilizar los mismos hiperparámetros ajustados para la media (MSE) en un modelo cuantílico.
- Si se entrenan múltiples cuantiles simultáneamente, puede ser necesario optimizar una función agregada o realizar validación cruzada específica por cuantil.
En todos los casos, el objetivo sigue siendo el mismo principio general de aprendizaje supervisado: minimizar la función de coste definida, donde un menor valor de la pinball loss indica un mejor ajuste del modelo al cuantil objetivo.
Sklearn proporciona la función mean_pinball_loss para calcular la pinball loss de un modelo. Combinada con make_scorer, facilita la evaluación y comparación de modelos de regresión cuantílica durante el proceso de optimización de hiperparámetros.
# Optimización de hiperparámetros para regresión cuantílica
# ==============================================================================
alpha = 0.9
neg_mean_pinball_loss_90p_scorer = make_scorer(
mean_pinball_loss,
alpha=alpha,
greater_is_better=False, # mayor pinball loss es peor, por eso se invierte el signo
)
modelo = HistGradientBoostingRegressor(
loss='quantile',
quantile=alpha,
learning_rate=0.1,
max_iter=50,
max_depth=10,
min_samples_leaf=20,
random_state=12345
)
param_grid = {
'learning_rate': [0.01, 0.1],
'max_iter': [50, 100],
'max_depth': [5, 10],
'min_samples_leaf': [10, 20]
}
search_90p = GridSearchCV(
modelo,
param_grid,
scoring=neg_mean_pinball_loss_90p_scorer,
n_jobs=2,
cv=5,
verbose=1
).fit(datos[['age']], datos['bmi'])
# Mejores hiperparámetros
# ==============================================================================
print("-----------------------------------")
print("Mejores hiperparámetros encontrados")
print("-----------------------------------")
print(f"{search_90p.best_params_} : {search_90p.best_score_} ({search_90p.scoring})")
Fitting 5 folds for each of 16 candidates, totalling 80 fits
-----------------------------------
Mejores hiperparámetros encontrados
-----------------------------------
{'learning_rate': 0.1, 'max_depth': 5, 'max_iter': 50, 'min_samples_leaf': 20} : -0.48501445660604076 (make_scorer(mean_pinball_loss, greater_is_better=False, response_method='predict', alpha=0.9))
# Resultados del grid
# ==============================================================================
resultados = pd.DataFrame(search_90p.cv_results_)
resultados.filter(regex = '(param.*|mean_t|std_t)')\
.drop(columns = 'params')\
.sort_values('mean_test_score', ascending = False)
| param_learning_rate | param_max_depth | param_max_iter | param_min_samples_leaf | mean_test_score | std_test_score | |
|---|---|---|---|---|---|---|
| 9 | 0.10 | 5 | 50 | 20 | -0.485014 | 0.142316 |
| 11 | 0.10 | 5 | 100 | 20 | -0.490251 | 0.137747 |
| 15 | 0.10 | 10 | 100 | 20 | -0.492876 | 0.138301 |
| 13 | 0.10 | 10 | 50 | 20 | -0.494067 | 0.146655 |
| 8 | 0.10 | 5 | 50 | 10 | -0.503220 | 0.134202 |
| 14 | 0.10 | 10 | 100 | 10 | -0.507211 | 0.123880 |
| 12 | 0.10 | 10 | 50 | 10 | -0.507859 | 0.127315 |
| 10 | 0.10 | 5 | 100 | 10 | -0.509143 | 0.131648 |
| 7 | 0.01 | 10 | 100 | 20 | -0.549994 | 0.189920 |
| 6 | 0.01 | 10 | 100 | 10 | -0.553063 | 0.185208 |
| 3 | 0.01 | 5 | 100 | 20 | -0.556236 | 0.191080 |
| 2 | 0.01 | 5 | 100 | 10 | -0.557444 | 0.191834 |
| 5 | 0.01 | 10 | 50 | 20 | -0.615320 | 0.249112 |
| 4 | 0.01 | 10 | 50 | 10 | -0.615577 | 0.249770 |
| 0 | 0.01 | 5 | 50 | 10 | -0.620067 | 0.252319 |
| 1 | 0.01 | 5 | 50 | 20 | -0.621626 | 0.255432 |
Intervalos de predicción¶
Un intervalo de predicción proporciona un rango de valores dentro del cual se espera que caiga una futura observación con una probabilidad determinada.
Al combinar las predicciones de regresión cuantílica, es posible construir un intervalo de predicción donde se estiman de forma directa los límites inferior y superior. Por ejemplo, si ajustamos nuestro modelo para los siguientes cuantiles:
- $Q = 0.05$
- $Q = 0.95$
las predicciones generadas definen, respectivamente, el límite inferior y el límite superior del intervalo.
La cobertura teórica del intervalo se calcula como la diferencia entre ambos: $0.95 - 0.05 = 0.9$.
Por tanto, se obtiene un intervalo de predicción del 90%. Esto significa que, bajo una buena calibración del modelo y asumiendo que no existe un cruce de cuantiles (quantile crossing), aproximadamente el 90% de los valores reales deberían situarse dentro de dicho intervalo.
# Predicciones cuantiles 05 y 95 para crear un intervalo del 90%
# ==============================================================================
modelo_05p = HistGradientBoostingRegressor(
loss='quantile',
quantile=0.05,
learning_rate=0.1,
max_iter=50,
max_depth=5,
min_samples_leaf=20,
random_state=12345
)
modelo_05p.fit(datos[['age']], datos['bmi'])
predicciones_q05 = modelo_05p.predict(datos[['age']])
modelo_95p = HistGradientBoostingRegressor(
loss='quantile',
quantile=0.95,
learning_rate=0.1,
max_iter=50,
max_depth=10,
min_samples_leaf=20,
random_state=12345
)
modelo_95p.fit(datos[['age']], datos['bmi'])
predicciones_q95 = modelo_95p.predict(datos[['age']])
predicciones = pd.DataFrame({
'age' : datos['age'].to_numpy(),
'bmi' : datos['bmi'].to_numpy(),
'pred_cuantil_05': predicciones_q05,
'pred_cuantil_95': predicciones_q95
}).sort_values('age').reset_index(drop=True)
predicciones.head(3)
| age | bmi | pred_cuantil_05 | pred_cuantil_95 | |
|---|---|---|---|---|
| 0 | 0.03 | 13.235289 | 11.871362 | 15.995399 |
| 1 | 0.04 | 12.438775 | 11.871362 | 15.995399 |
| 2 | 0.04 | 11.773954 | 11.871362 | 15.995399 |
# Gráfico intervalo cuantílico 05-95
# ==============================================================================
fig, ax = plt.subplots(figsize=(8, 4))
datos.plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = ax
)
predicciones.plot(
x = 'age',
y = 'pred_cuantil_05',
c = 'red',
kind = "line",
ax = ax
)
predicciones.plot(
x = 'age',
y = 'pred_cuantil_95',
c = 'red',
kind = "line",
ax = ax
)
ax.set_title('Distribución índice masa corporal en función de la edad', fontsize = 12);

✏️ Note
Cabe destacar que, para conseguir un mejor intervalo, es recomendable realizar una optimización de hiperparámetros específica para cada cuantil. Reutilizar los mismos hiperparámetros ajustados para la media (optimizados mediante MSE) o para otro cuantil suele resultar en intervalos subóptimos o mal calibrados.
Cobertura del Intervalo
En el contexto de los intervalos de predicción, la cobertura (o probabilidad de cobertura) es la proporción de veces que el valor real de la variable objetivo cae efectivamente dentro del intervalo predicho. Es la principal métrica para evaluar si nuestro modelo está bien calibrado.
Es importante distinguir entre dos conceptos:
Cobertura Nominal (o Teórica): Es la confianza objetivo o el nivel de probabilidad esperado según la construcción del intervalo.
Cobertura Empírica (o Real): Es la proporción real de observaciones que caen dentro de los límites generados por el modelo.
Un modelo está bien calibrado cuando su cobertura empírica es aproximadamente igual a su cobertura nominal. Si la cobertura empírica es mucho menor (por ejemplo, del 60% en lugar del 90% esperado), significa que el modelo está demasiado confiado y produce intervalos demasiado estrechos. Si es mucho mayor, los intervalos son probablemente demasiado amplios e informativos.
# Cobertura del intervalo predicho
# ==============================================================================
def coverage_fraction(y, y_low, y_high):
"""
Calcula la proporción de veces que y está entre y_low e y_high
"""
return np.mean(np.logical_and(y >= y_low, y <= y_high))
cobertura = coverage_fraction(
y = predicciones['bmi'],
y_low = predicciones['pred_cuantil_05'],
y_high = predicciones['pred_cuantil_95'],
)
print(f"Cobertura empírica: {100 * cobertura:.2f}%")
Cobertura empírica: 90.02%
Detección de anomalías
Conocer los intervalos de predicción resulta útil para detectar anomalías, observaciones con valores muy poco probables acorde al modelo considerado.
Dada una determinada edad, índices de masa corporal bajos son un indicativo de posibles problemas de malnutrición y, valores muy altos, son indicativos de potenciales problemas de sobrepeso. Utilizando el modelo entrenado, se identifican aquellas personas con valores de bmi muy poco probables para la edad que tienen.
# Detección de anomalías acorde al intervalo de predicción del 90%
# ==============================================================================
# Anomalías (valores fuera del intervalo del 90%)
predicciones['anomalia'] = (
(predicciones['bmi'] < predicciones['pred_cuantil_05']) |
(predicciones['bmi'] > predicciones['pred_cuantil_95'])
)
predicciones.head()
| age | bmi | pred_cuantil_05 | pred_cuantil_95 | anomalia | |
|---|---|---|---|---|---|
| 0 | 0.03 | 13.235289 | 11.871362 | 15.995399 | False |
| 1 | 0.04 | 12.438775 | 11.871362 | 15.995399 | False |
| 2 | 0.04 | 11.773954 | 11.871362 | 15.995399 | True |
| 3 | 0.04 | 14.541775 | 11.871362 | 15.995399 | False |
| 4 | 0.04 | 15.325614 | 11.871362 | 15.995399 | False |
# Anomalías detectadas
# ==============================================================================
fig, ax = plt.subplots(figsize=(8, 4))
datos.plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = ax
)
predicciones[predicciones['anomalia']].plot(
x = 'age',
y = 'bmi',
c = 'red',
kind = "scatter",
label = 'anomalía',
ax = ax
)
ax.set_title('Distribución índice masa corporal en función de la edad', fontsize = 12);

Modelos para múltiples cuantiles¶
Una de las ventajas de la implementación de CatBoost es que dispone de la función de coste MultiQuantile, que permite que un único modelo aprenda múltiples cuantiles de forma simultánea, evitando así la necesidad de entrenar varios modelos.
# Predicciones multi-cuantil con CatBoost
# ==============================================================================
cuantiles = np.arange(0.1, 1.0, 0.1).round(2).tolist()
cuantiles_str = ",".join(map(str, cuantiles))
modelo = CatBoostRegressor(
random_state=123,
silent=True,
allow_writing_files=False,
loss_function=f'MultiQuantile:alpha={cuantiles_str}',
)
modelo.fit(datos[['age']], datos['bmi'])
preds = modelo.predict(datos[['age']])
nombres_columnas = [f'pred_cuantil_{int(q * 100)}' for q in cuantiles]
predicciones = pd.DataFrame(preds, columns=nombres_columnas, index=datos.index)
predicciones['age'] = datos['age'].values
predicciones = predicciones.sort_values('age').reset_index(drop=True)
predicciones.head()
| pred_cuantil_10 | pred_cuantil_20 | pred_cuantil_30 | pred_cuantil_40 | pred_cuantil_50 | pred_cuantil_60 | pred_cuantil_70 | pred_cuantil_80 | pred_cuantil_90 | age | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 12.188598 | 12.43901 | 13.162931 | 13.243538 | 13.665211 | 14.263665 | 14.372886 | 14.541328 | 15.202162 | 0.03 |
| 1 | 12.188598 | 12.43901 | 13.162931 | 13.243538 | 13.665211 | 14.263665 | 14.372886 | 14.541328 | 15.202162 | 0.04 |
| 2 | 12.188598 | 12.43901 | 13.162931 | 13.243538 | 13.665211 | 14.263665 | 14.372886 | 14.541328 | 15.202162 | 0.04 |
| 3 | 12.188598 | 12.43901 | 13.162931 | 13.243538 | 13.665211 | 14.263665 | 14.372886 | 14.541328 | 15.202162 | 0.04 |
| 4 | 12.188598 | 12.43901 | 13.162931 | 13.243538 | 13.665211 | 14.263665 | 14.372886 | 14.541328 | 15.202162 | 0.04 |
# Gráfico de múltiples cuantiles (10 al 90)
# ==============================================================================
pred_cols = [c for c in predicciones.columns if c != 'age']
colores = cm.coolwarm(np.linspace(0, 1, len(pred_cols)))
fig, ax = plt.subplots(figsize=(8, 4))
datos.plot(
x = 'age',
y = 'bmi',
c = 'black',
kind = "scatter",
alpha = 0.1,
ax = ax
)
for col, color in zip(pred_cols, colores):
ax.plot(
predicciones['age'],
predicciones[col],
color=color,
label=col
)
ax.set_title('Distribución del índice de masa corporal por edad', fontsize=14)
ax.set_xlabel('age')
ax.set_ylabel('bmi')
#ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
fig.tight_layout()
plt.show()

Comparación con otros modelos probabilísticos¶
Dada la necesidad crítica de incorporar la incertidumbre en la toma de decisiones, la comunidad ha desarrollado múltiples enfoques para ir más allá de las predicciones puntuales. Esta sección compara cuatro de las metodologías más utilizadas para la estimación probabilística y la regresión condicional.
NGBoost (Natural Gradient Boosting)
Desarrollado por el laboratorio de ML de Stanford, NGBoost es una extensión del Gradient Boosting tradicional orientada a la estimación de incertidumbre.
¿Cómo funciona?: NGBoost asume que la variable objetivo sigue una distribución paramétrica $P(y|\theta)$, donde $\theta$ es un vector de parámetros (por ejemplo, $\theta = (\mu, \sigma)$ para una distribución Normal). El modelo no predice $y$ directamente, sino que modela los parámetros $\theta$ como funciones aditivas de las variables $X$.
Gradiente Natural: A diferencia del gradiente estándar (utilizado en modelos de gradient boosting estandar) que mide distancias entre números, el gradiente natural mide la distancia entre distribuciones de probabilidad (usando la Divergencia de Kullback-Leibler). Esto hace que el aprendizaje sea más estable y matemáticamente elegante.
Ventaja: Proporciona estimaciones de incertidumbre muy precisas y estables.
Desventaja: Es más lento que los modelos de boosting tradicionales porque el cálculo del gradiente natural es computacionalmente costoso.
BART (Bayesian Additive Regression Trees)
BART es un modelo bayesiano que no depende de la optimización del gradiente, sino se basa en el muestreo estadístico bayesiano.
¿Cómo funciona?: BART construye un "ensamble" de árboles muy simples (débiles). A diferencia del boosting, donde cada árbol corrige al anterior, en BART los árboles se van modificando mediante un proceso llamado MCMC (Markov Chain Monte Carlo). En cada iteración, se propone una modificación a un árbol (crecer, podar, cambiar regla o permutar) y se acepta/rechaza según el ratio de Metropolis-Hastings.
Regularización (Priors): BART impone priors fuertemente regularizadores que penalizan la profundidad de los árboles y los pesos de los nodos hoja. Esto obliga a que cada árbol contribuya de manera marginal (efecto shrinkage natural), evitando el sobreajuste.
Mecanismo de Inferencia: Durante el entrenamiento, el modelo genera miles de versiones posibles del "bosque" de árboles. La predicción final no es un solo número, sino el promedio de todas estas versiones. La incertidumbre se obtiene viendo cuánto varían las predicciones entre todos los bosques generados.
Ventaja: No necesitas elegir una distribución (es no paramétrico). Es extraordinariamente robusto a la configuración de hiperparámetros.
Desventaja: El proceso secuencial de MCMC es difícilmente paralelizable y computacionalmente restrictivo ($O(n)$ por iteración), lo que limita su escalabilidad.
GBM-LSS (Gradient Boosting for Location, Scale, and Shape)
GBM-LSS lleva el concepto de "Location, Scale and Shape" (Ubicación, Escala y Forma) al mundo del Gradient Boosting de alto rendimiento (como XGBoost o LightGBM).
¿Cómo funciona?: Modela la distribución condicional estimando múltiples parámetros $\theta = (\theta_1, \theta_2, \theta_3, \theta_4)$, que típicamente corresponden a métricas de ubicación ($\mu$), escala ($\sigma$), asimetría ($\nu$, skewness) y curtosis ($\tau$). Permite ajustar cualquier distribución diferenciable (e.g., Zero-Inflated, Tweedie, Student-t). En este sentido es similar a los modelos de NGBoost.
Multi-parámetro cíclico. El modelo entrena árboles de forma secuencial para cada parámetro, es decir, asume independencia iterativa entre parámetros.
Ventaja: Es el más rápido de los tres y el más flexible. Al aprovechar infraestructuras como XGBoost/LightGBM, hereda soporte nativo para paralelización de GPU, early stopping eficiente y manejo de missing values, permitiendo escalar a millones de registros.
Desventaja: Puede ser difícil de configurar y a veces inestable si los parámetros no están bien balanceados.
Regresión Cuantílica (Quantile Regression)
Implementada comúnmente mediante variaciones de algoritmos como Quantile Regression Forests (QRF) o mediante modelos de Gradient Boosting clásicos (LightGBM, CatBoost) cambiando la función de pérdida.
Fundamento Teórico: En lugar de estimar la media condicional $\mathbb{E}[Y|X]$ o los parámetros de una distribución entera $P(Y|X)$, la regresión cuantílica estima directamente un cuantil específico $Q_\tau(Y|X)$ (por ejemplo, $\tau = 0.9$ para el percentil 90). Es matemáticamente "libre de distribución" (distribution-free), por lo que no asume ninguna forma (ni normal, ni gamma, ni ninguna otra).
Mecanismo de Optimización: Abandona el error cuadrático medio (MSE) o la estimación de máxima verosimilitud en favor de minimizar la Pérdida Pinball (Quantile Loss): $$L_\tau(y, \hat{y}) = \max(\tau(y - \hat{y}), (\tau - 1)(y - \hat{y}))$$ Esta función asimétrica penaliza las subestimaciones y sobreestimaciones de manera diferente dependiendo del cuantil $\tau$ objetivo.
Ventajas: Es extremadamente robusta frente a outliers y heterocedasticidad. No requiere suposiciones paramétricas previas.
Limitaciones: Mientras que NGBoost, BART o GBM-LSS estiman la curva de probabilidad entera (PDF), la regresión cuantílica solo predice puntos específicos predefinidos (cuantiles). Al carecer de la distribución completa, se pierde flexibilidad analítica a posteriori: si en el futuro se requiere conocer la varianza exacta o consultar la probabilidad en un nuevo umbral, será necesario reentrenar el modelo para calcular esos nuevos puntos.
| Atributo | NGBoost | GBM-LSS | BART | Regresión Cuantílica |
|---|---|---|---|---|
| Objetivo | Densidad Completa (PDF) | Densidad Completa (PDF) | Densidad Completa (Posterior) | Puntos de la CDF |
| Aproximación | Paramétrica ($\mu, \sigma$) | Paramétrica ($\mu, \sigma, \nu, \tau$) | Bayesiana (No paramétrica) | Libre de distribución (Empírica) |
| Optimización | Gradiente Natural (MLE/CRPS) | Expansión de Taylor (Newton-Raphson) | Muestreo MCMC | Pinball Loss |
| Salida Predicha | Parámetros distribucionales | Parámetros distribucionales | Promedio de cadenas de Markov | Intervalos directos (ej. $y_{10}$ a $y_{90}$) |
| Problemas Típicos | Lento de entrenar | Complejo de estabilizar / ajustar | Escasa escalabilidad a Big Data | Quantile Crossing |
Información de sesión¶
import session_info
session_info.show(html=False)
----- catboost 1.2.8 matplotlib 3.10.8 numpy 2.2.6 pandas 2.3.3 seaborn 0.13.2 session_info v1.0.1 sklearn 1.7.2 statsmodels 0.14.6 ----- IPython 9.8.0 jupyter_client 8.8.0 jupyter_core 5.9.1 jupyterlab 4.5.3 ----- Python 3.13.11 | packaged by Anaconda, Inc. | (main, Dec 10 2025, 21:28:48) [GCC 14.3.0] Linux-6.17.0-14-generic-x86_64-with-glibc2.39 ----- Session information updated at 2026-03-02 19:28
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Regresión cuantílica con Python por Joaquín Amat Rodrigo, disponible bajo una licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://www.cienciadedatos.net/documentos/py68-regresion-cuantilica-python.html
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊



Este documento creado por Joaquín Amat Rodrigo tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.