Más sobre ciencia de datos en: cienciadedatos.net
- Regresión lineal con Python
- Regresión lineal múltiple con Python
- Regresión logística con Python
- Regularización Ridge, Lasso y Elastic Net con Python
- Machine learning con Python y Scikitlearn
- Árboles de decisión con Python: regresión y clasificación
- Random Forest con Python y Scikit-learn
- Gradient Boosting con Python y Scikit-learn
- Gradient Boosting probabilístico con Python
- Máquinas de Vector Soporte (SVM)
- Redes neuronales con Python
- Análisis de componentes principales PCA
- Clustering
- Detección de anomalías con PCA
- Detección de anomalías con autoencoders
- Detección de anomalías con Gaussian Mixture Models
- Detección de anomalías con Isolation Forest
- Análisis de texto (text mining) con Python
- Reglas de asociación
- Análisis Tweets con Python
Introducción¶
Máquinas de Vector Soporte (Support Vector Machines, SVMs) es un algoritmo de clasificación y regresión desarrollado en la década de los 90, dentro del campo de la ciencia computacional. Aunque inicialmente se desarrolló como un método de clasificación binaria, su aplicación se ha extendido a problemas de clasificación múltiple y regresión. SVMs ha resultado ser uno de los mejores clasificadores para un amplio abanico de situaciones, por lo que se considera uno de los referentes dentro del ámbito de aprendizaje estadístico y machine learning.
Las Máquinas de Vector Soporte se fundamentan en el Maximal Margin Classifier, que a su vez, se basa en el concepto de hiperplano. A lo largo de este documento se introducen por orden cada uno de estos conceptos. Comprender los fundamentos de las SVMs requiere de conocimientos sólidos en álgebra lineal y optimización. En este documento no se profundiza en el aspecto matemático, pero puede encontrarse una descripción detallada en el libro Support Vector Machines Succinctly by Alexandre Kowalczyk.
La librería Scikit Learn contiene implementaciones en Python de los principales algoritmos de SVM.
Hiperplano y Maximal margin classifier¶
En un espacio p-dimensional, un hiperplano se define como un subespacio plano y afín de dimensiones $p-1$. El término afín significa que el subespacio no tiene por qué pasar por el origen. En un espacio de dos dimensiones, el hiperplano es un subespacio de 1 dimensión, es decir, una recta. En un espacio tridimensional, un hiperplano es un subespacio de dos dimensiones, un plano convencional. Para dimensiones $p>3$ no es intuitivo visualizar un hiperplano, pero el concepto de subespacio con $p-1$ dimensiones se mantiene.
La definición matemática de un hiperplano es bastante simple. En el caso de dos dimensiones, el hiperplano se describe de acuerdo con la ecuación de una recta:
$$\beta_0 + \beta_1x_1 + \beta_2x_2 = 0$$Dados los parámetros $\beta_0$, $\beta_1$ y $\beta_2$, todos los pares de valores $\textbf{x} = (x_1, x_2)$ para los que se cumple la igualdad son puntos del hiperplano. Esta ecuación puede generalizarse para p-dimensiones:
$$\beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_px_p = 0$$y de igual manera, todos los puntos definidos por el vector $\textbf{x} = (x_1, x_2,...,x_p)$ que cumplen la ecuación pertenecen al hiperplano.
Cuando $\textbf{x}$ no satisface la ecuación:
$$\beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_px_p < 0$$o bien
$$\beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_px_p > 0$$el punto $\textbf{x}$ cae a un lado o al otro del hiperplano. Así pues, se puede entender que un hiperplano divide un espacio p-dimensional en dos mitades. Para saber en qué lado del hiperplano se encuentra un determinado punto $\textbf{x}$, solo hay que calcular el signo de la ecuación.
La siguiente imagen muestra el hiperplano de un espacio bidimensional. La ecuación que describe el hiperplano (una recta) es $1 + 2x_1 + 3x_2 = 0$. La región azul representa el espacio en el que se encuentran todos los puntos para los que $1 + 2x_1 + 3x_2 > 0$ y la región roja el de los puntos para los que $1 + 2x_1 + 3x_2 < 0$.

Clasificación binaria empleando un hiperplano¶
Cuando se dispone de $n$ observaciones, cada una con $p$ predictores y cuya variable respuesta tiene dos niveles (de aquí en adelante identificados como $+1$ y $-1$), se pueden emplear hiperplanos para construir un clasificador que permita predecir a qué grupo pertenece una observación en función de sus predictores.
Para facilitar la comprensión, las siguientes explicaciones se basan en un espacio de dos dimensiones, donde un hiperplano es una recta. Sin embargo, los mismos conceptos son aplicables a dimensiones superiores.
CASOS PERFECTAMENTE SEPARABLES LINEALMENTE
Si la distribución de las observaciones es tal que se pueden separar linealmente de forma perfecta en las dos clases ($+1$ y $-1$), entonces, un hiperplano de separación cumple que:
$$\beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_px_p > 0, \ si \ y_i=1$$$$\beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_px_p < 0, \ si \ y_i=-1$$Bajo este escenario, el clasificador más sencillo consiste en asignar cada observación a una clase dependiendo del lado del hiperplano en el que se encuentre. Es decir, la observación $\textbf{x}^*$ se clasifica de acuerdo con el signo de la función $f(\textbf{x}^*) = \beta_0 + \beta_1x^*_1 + \beta_2x^*_2 + ... + \beta_px^*_p$. Si $f(\textbf{x}^*)$ es positiva, la observación se asigna a la clase $+1$, si es negativa, a la clase $-1$. Además, la magnitud de $f(\textbf{x}^*)$ permite saber cómo de lejos está la observación del hiperplano y con ello la confianza de la clasificación (no confundir esto con un valor de probabilidad).
La definición de hiperplano para casos perfectamente separables linealmente resulta en un número infinito de posibles hiperplanos, lo que hace necesario un método que permita seleccionar uno de ellos como clasificador óptimo.
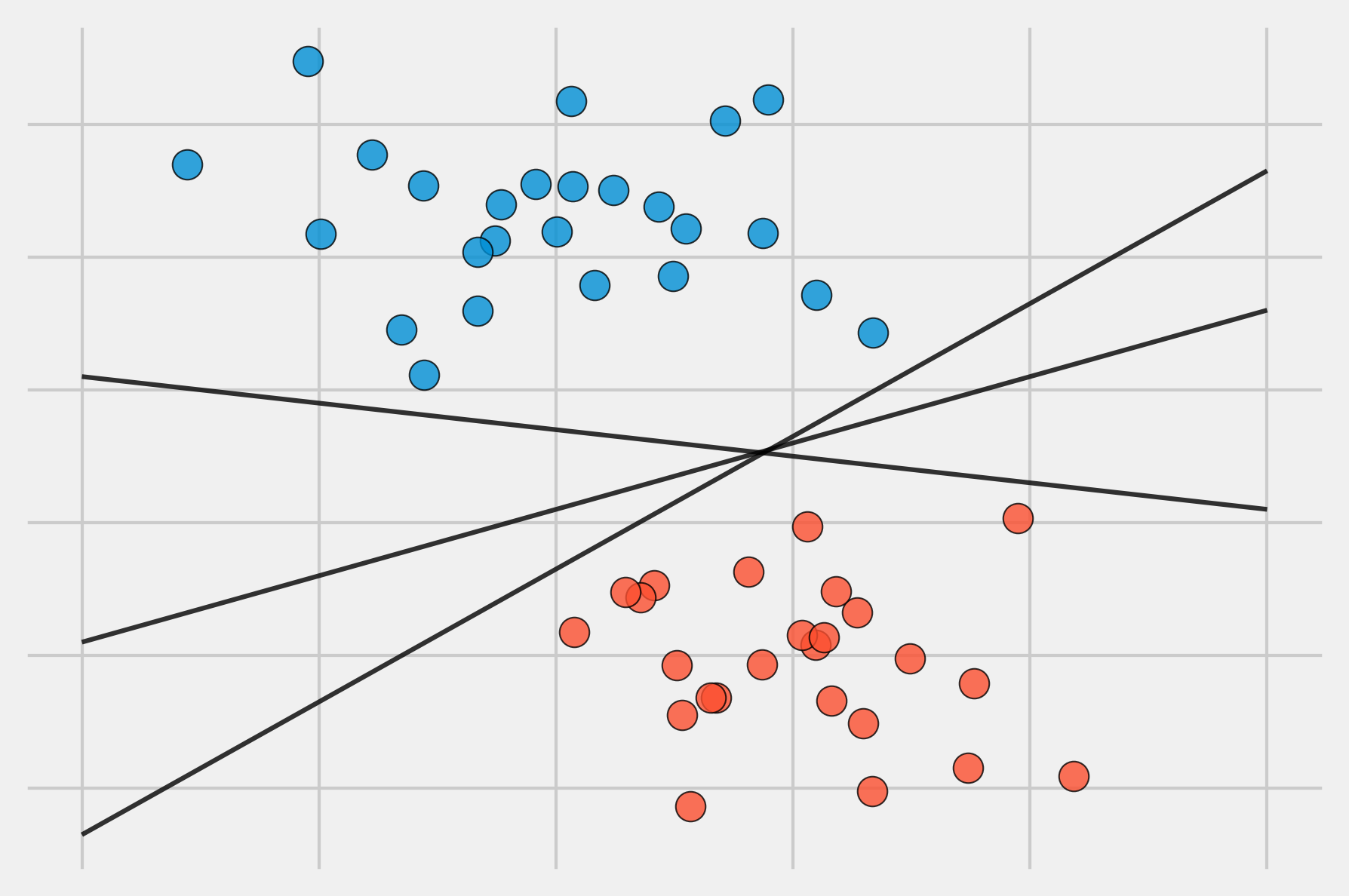
La solución a este problema consiste en seleccionar como clasificador óptimo el hiperplano que se encuentra más alejado de todas las observaciones de entrenamiento. A este se le conoce como maximal margin hyperplane o hiperplano óptimo de separación. Para identificarlo, se tiene que calcular la distancia perpendicular de cada observación a un determinado hiperplano. La menor de estas distancias (conocida como margen) determina cuán alejado está el hiperplano de las observaciones de entrenamiento. Así pues, el maximal margin hyperplane se define como el hiperplano que consigue un mayor margen, es decir, que la distancia mínima entre el hiperplano y las observaciones es lo más grande posible. Aunque esta idea suena razonable, no es posible aplicarla, ya que habría infinitos hiperplanos contra los que medir las distancias. En su lugar, se recurre a métodos de optimización dual.
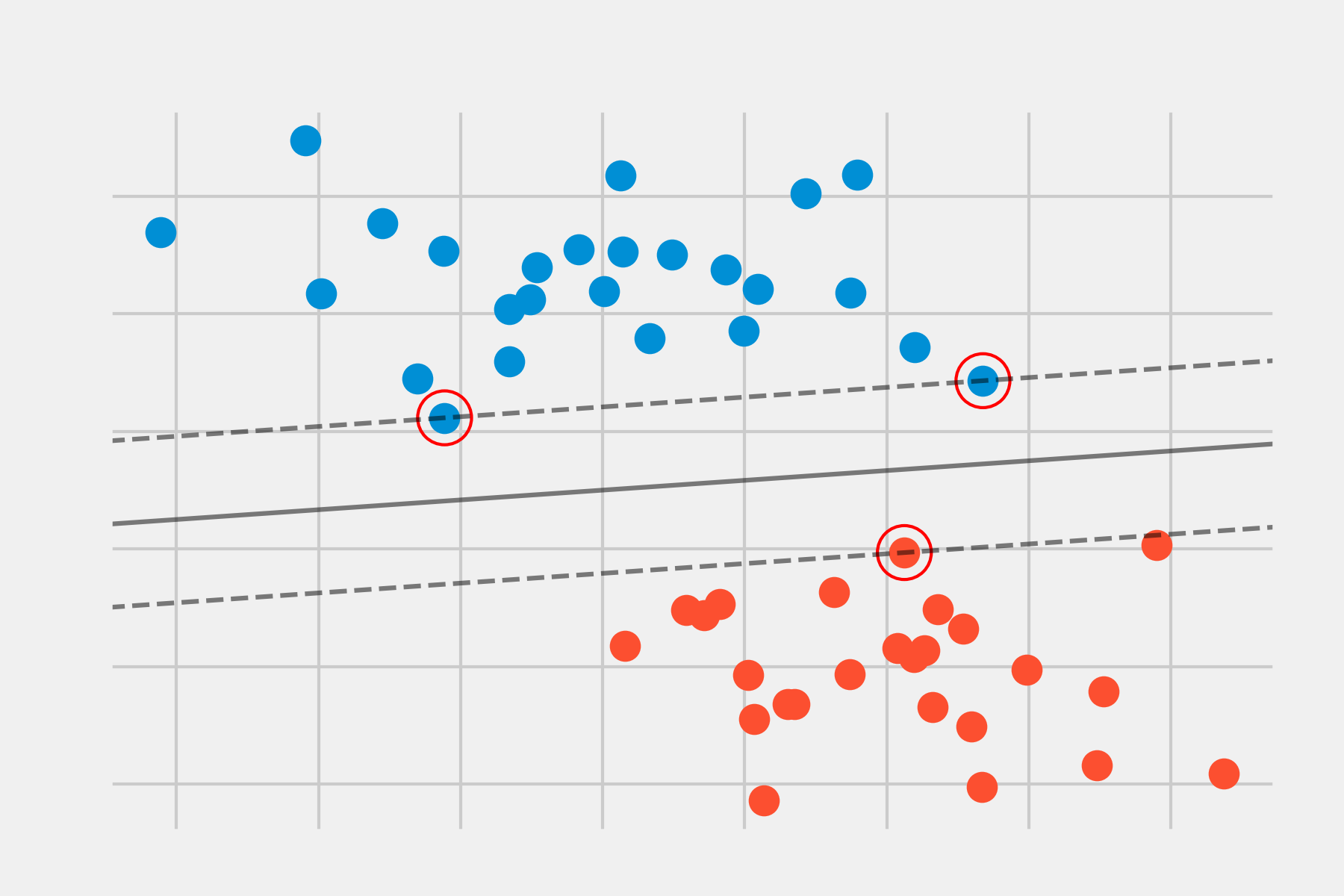
La imagen anterior muestra el maximal margin hyperplane, formado por el hiperplano (línea negra continua) y su margen (las dos líneas discontinuas). Las tres observaciones equidistantes respecto al maximal margin hyperplane que se encuentran a lo largo de las líneas discontinuas se les conoce como vectores soporte, ya que son vectores en un espacio p-dimensional y soportan (definen) el maximal margin hyperplane. Cualquier modificación en estas observaciones (vectores soporte) conlleva cambios en el maximal margin hyperplane. Sin embargo, modificaciones en observaciones que no son vector soporte no tienen impacto alguno en el hiperplano.
CASOS CUASI-SEPARABLES LINEALMENTE
El maximal margin hyperplane descrito en el apartado anterior es una forma muy simple y natural de clasificación siempre y cuando exista un hiperplano de separación. En la gran mayoría de casos reales, los datos no se pueden separar linealmente de forma perfecta, por lo que no existe un hiperplano de separación y no puede obtenerse un maximal margin hyperplane.
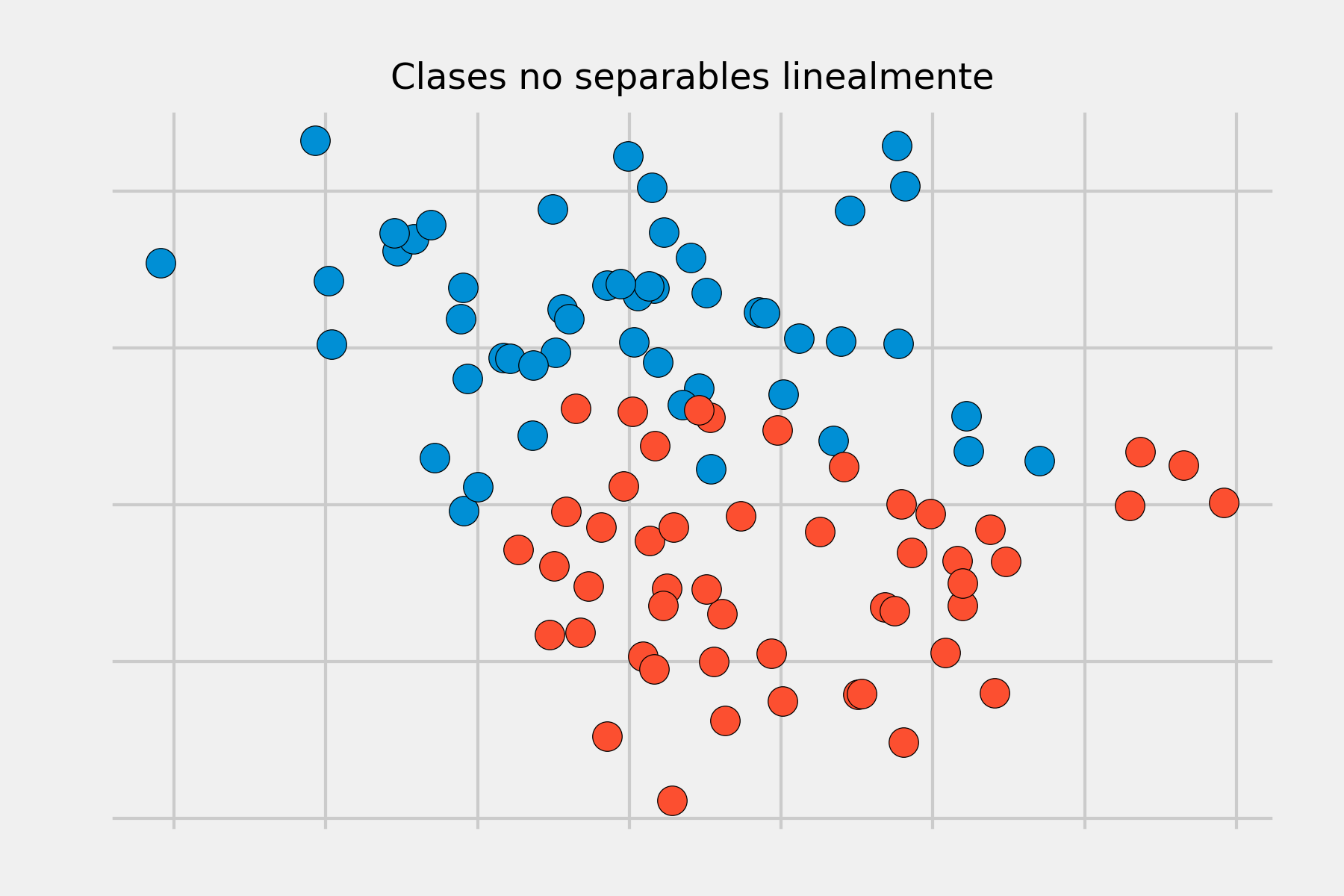
Para solucionar estas situaciones, se puede extender el concepto de maximal margin hyperplane para obtener un hiperplano que "casi" separe las clases, pero permitiendo que se cometan unos pocos errores. A este tipo de hiperplano se le conoce como Support Vector Classifier o Soft Margin.
Support Vector Classifier o Soft Margin SVM¶
El Maximal Margin Classifier descrito en la sección anterior tiene poca aplicación práctica, ya que rara vez se encuentran casos en los que las clases sean perfectamente y linealmente separables. De hecho, incluso cumpliéndose estas condiciones ideales, en las que exista un hiperplano capaz de separar perfectamente las observaciones en dos clases, esta aproximación sigue presentando dos inconvenientes:
Dado que el hiperplano tiene que separar perfectamente las observaciones, es muy sensible a variaciones en los datos. Incluir una nueva observación puede suponer cambios muy grandes en el hiperplano de separación (poca robustez).
Que el maximal margin hyperplane se ajuste perfectamente a las observaciones de entrenamiento para separarlas todas correctamente suele conllevar problemas de overfitting.
Por estas razones, es preferible crear un clasificador basado en un hiperplano que, aunque no separe perfectamente las dos clases, sea más robusto y tenga mayor capacidad predictiva al aplicarlo a nuevas observaciones (menos problemas de overfitting). Esto es exactamente lo que consiguen los clasificadores de vector soporte, también conocidos como soft margin classifiers o Support Vector Classifiers. Para lograrlo, en lugar de buscar el margen de clasificación más ancho posible que consigue que las observaciones estén en el lado correcto del margen; se permite que ciertas observaciones estén en el lado incorrecto del margen o incluso del hiperplano.
La siguiente imagen muestra un clasificador de vector soporte ajustado a un pequeño set de observaciones. La línea continua representa el hiperplano y las líneas discontinuas el margen a cada lado. Las observaciones 2, 3, 4, 5, 6, 7, 9 y 10 se encuentran en el lado correcto del margen (también del hiperplano) por lo que están bien clasificadas. Las observaciones 1 y 8, a pesar de que se encuentran dentro del margen, están en el lado correcto del hiperplano, por lo que también están bien clasificadas. Las observaciones 11 y 12, se encuentran en el lado erróneo del hiperplano, su clasificación es incorrecta. Todas aquellas observaciones que, estando dentro o fuera del margen, se encuentren en el lado incorrecto del hiperplano, se corresponden con observaciones de entrenamiento mal clasificadas.
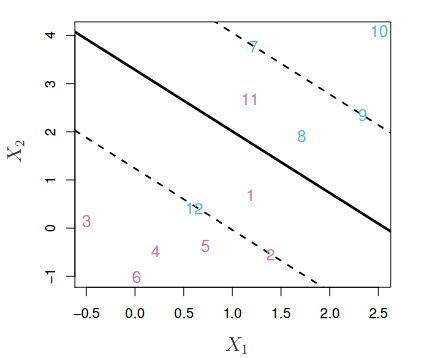
La identificación del hiperplano que clasifique correctamente la mayoría de las observaciones a excepción de unas pocas, es un problema de optimización convexa. Si bien la demostración matemática queda fuera del objetivo de esta introducción, es importante mencionar que el proceso incluye un hiperparámetro llamado $C$. $C$ controla el número y severidad de las violaciones del margen (y del hiperplano) que se toleran en el proceso de ajuste. Si $C= \infty$, no se permite ninguna violación del margen y por lo tanto, el resultado es equivalente al Maximal Margin Classifier (teniendo en cuenta que esta solución solo es posible si las clases son perfectamente separables). Cuanto más se aproxima $C$ a cero, menos se penalizan los errores y más observaciones pueden estar en el lado incorrecto del margen o incluso del hiperplano. $C$ es a fin de cuentas el hiperparámetro encargado de controlar el balance entre bias y varianza del modelo. En la práctica, su valor óptimo se identifica mediante validación cruzada.
El proceso de optimización tiene la peculiaridad de que solo las observaciones que se encuentran justo en el margen o que lo violan influyen sobre el hiperplano. A estas observaciones se les conoce como vectores soporte y son las que definen el clasificador obtenido. Esta es la razón por la que el parámetro $C$ controla el balance entre bias y varianza. Cuando el valor de $C$ es pequeño, el margen es más ancho, y más observaciones violan el margen, convirtiéndose en vectores soporte. El hiperplano está, por lo tanto, sustentado por más observaciones, lo que aumenta el bias pero reduce la varianza. Cuanto mayor es el valor de $C$, menor el margen, menos observaciones son vectores soporte y el clasificador resultante tiene menor bias pero mayor varianza.
Otra propiedad importante que deriva de que el hiperplano dependa únicamente de una pequeña proporción de observaciones (vectores soporte), es su robustez frente a observaciones muy alejadas del hiperplano. Esto hace al método de clasificación vector soporte distinto a otros métodos tales como Linear Discriminant Analysis (LDA), donde la regla de clasificación depende de la media de todas las observaciones.
Nota: en el libro Introduction to Statistical Learning se emplea un término $C$ que equivale a la inversa del descrito en este documento.
Máquinas de Vector Soporte¶
El Support Vector Classifier descrito en los apartados anteriores consigue buenos resultados cuando el límite de separación entre clases es aproximadamente lineal. Si no lo es, su capacidad decae drásticamente. Una estrategia para enfrentarse a escenarios en los que la separación de los grupos es de tipo no lineal consiste en expandir las dimensiones del espacio original.
El hecho de que los grupos no sean linealmente separables en el espacio original no significa que no lo sean en un espacio de mayores dimensiones. Las imágenes siguientes muestran dos grupos cuya separación en dos dimensiones no es lineal, pero sí lo es al añadir una tercera dimensión.
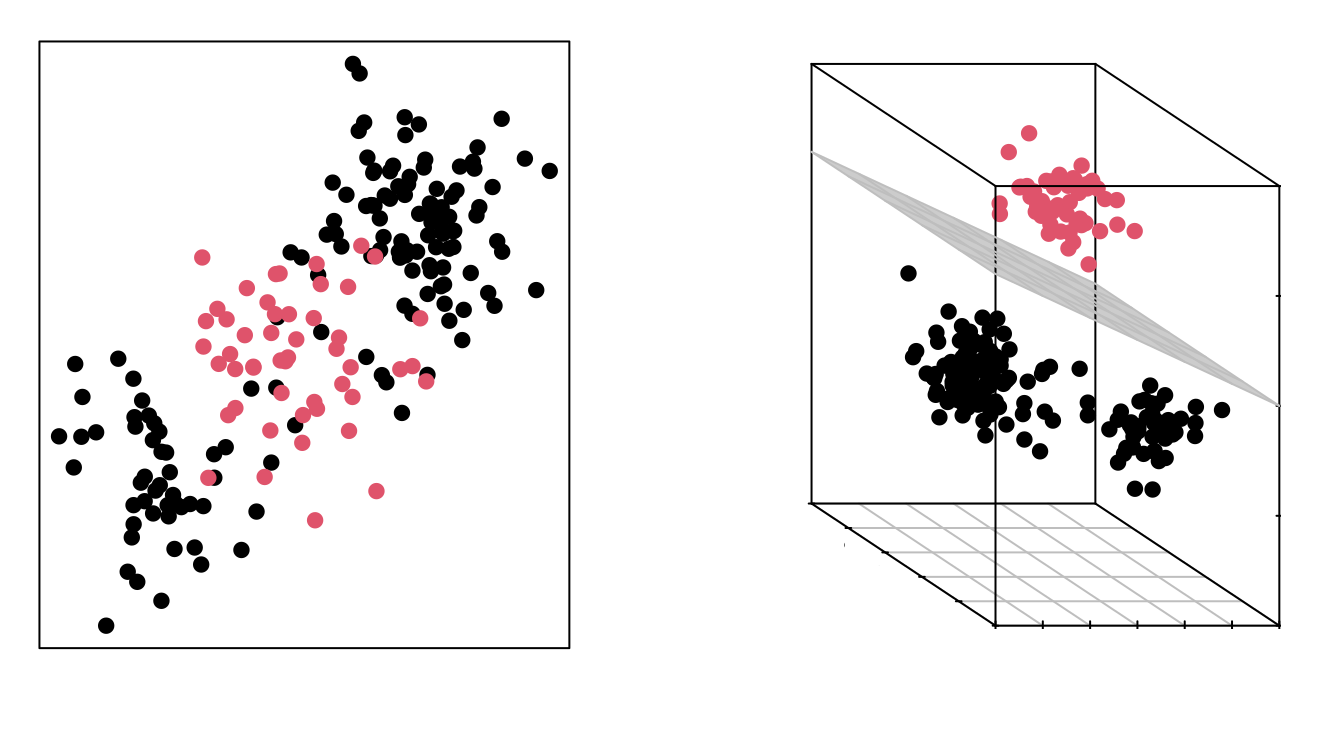
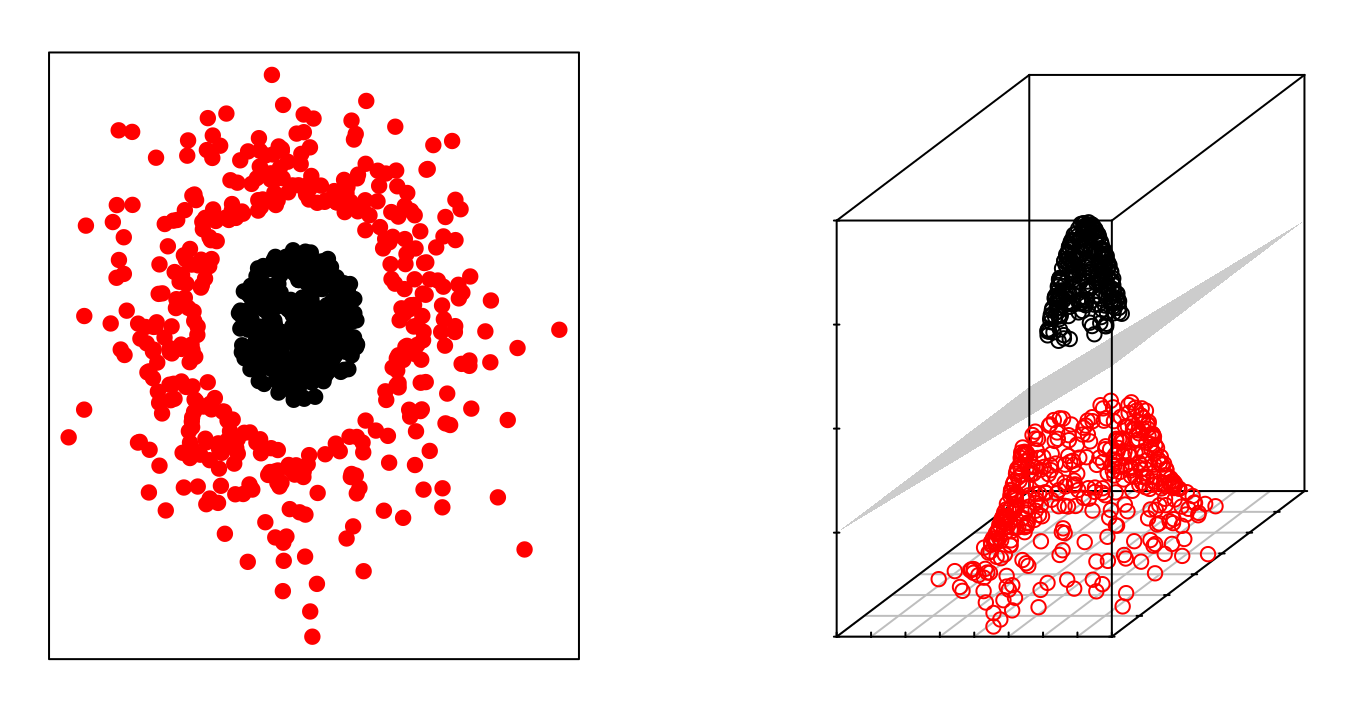
El método de Máquinas Vector Soporte (SVM) se puede considerar como una extensión del Support Vector Classifier obtenida al aumentar la dimensión de los datos. Los límites de separación lineales generados en el espacio aumentado se convierten en límites de separación no lineales al proyectarlos en el espacio original.
Aumento de la dimensión: kernels¶
Una vez definido que las Máquinas de Vector Soporte siguen la misma estrategia que el Support Vector Classifier, pero aumentando la dimensión de los datos antes de aplicar el algoritmo, la pregunta inmediata es ¿Cómo se aumenta la dimensión y qué dimensión es la correcta?
La dimensión de un conjunto de datos puede transformarse combinando o modificando cualquiera de sus dimensiones. Por ejemplo, se puede transformar un espacio de dos dimensiones en uno de tres aplicando la siguiente función:
$$f(x_1,x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2) $$Esta es solo una de las infinitas transformaciones posibles, ¿Cómo saber cuál es la adecuada? Es aquí donde el concepto de kernel entra en juego. Un kernel (K) es una función que devuelve el resultado del producto escalar entre dos vectores realizado en un nuevo espacio dimensional distinto al espacio original en el que se encuentran los vectores. Aunque no se ha entrado en detalle en las fórmulas matemáticas empleadas para resolver el problema de optimización, esta contiene un producto escalar. Si se sustituye este producto escalar por un kernel, se obtienen directamente los vectores soporte (y el hiperplano) en la dimensión correspondiente al kernel. A esto se le suele conocer como kernel trick porque, con solo una ligera modificación del problema original, se puede obtener el resultado para cualquier dimensión. Existen multitud de kernels distintos, algunos de los más utilizados son:
Kernel lineal
$$K(\textbf{x}, \textbf{x'}) = \textbf{x} \cdot \textbf{x'}$$Si se emplea un Kernel lineal, el clasificador Support Vector Machine obtenido es equivalente al Support Vector Classifier.
Kernel polinómico
$$K(\textbf{x}, \textbf{x'}) = (\textbf{x} \cdot \textbf{x'} + c) ^ d$$Cuando se emplea $d = 1$ y $c=0$, el resultado es el mismo que el de un kernel lineal. Si $d>1$, se generan límites de decisión no lineales, aumentando la no linealidad a medida que aumenta $d$. No suele ser recomendable emplear valores de $d$ mayores de 5 por problemas de overfitting.
Gaussian Kernel (RBF)
$$K(\textbf{x}, \textbf{x'}) = exp(- \gamma ||\textbf{x} - \textbf{x'}||^2)$$El valor de $\gamma$ controla el comportamiento del kernel, cuando es muy pequeño, el modelo final es equivalente al obtenido con un kernel lineal, a medida que aumenta su valor, también lo hace la flexibilidad del modelo.
Los kernels descritos son solo unos pocos de los muchos que existen. Cada uno tiene una serie de hiperparámetros cuyo valor óptimo puede encontrarse mediante validación cruzada. No puede decirse que haya un kernel que supere al resto, depende en gran medida de la naturaleza del problema que se esté tratando. Ahora bien, tal como indican los autores de A Practical Guide to Support Vector Classification, es muy recomendable probar el kernel RBF. Este kernel tiene dos ventajas: que solo tiene dos hiperparámetros que optimizar ($\gamma$ y la penalización $C$ común a todos los SVM) y que su flexibilidad puede ir desde un clasificador lineal a uno muy complejo.
Clasificación multi-clase¶
El concepto de hiperplano de separación en el que se basan los SVMs no se generaliza de forma natural para más de dos clases. Se han desarrollado numerosas estrategias con el fin de aplicar este algoritmo a problemas multiclase, de entre ellos, los más empleados son: one-versus-one, one-versus-all y DAGSVM.
One-versus-one¶
Supóngase un escenario en el que hay K > 2 clases y que se quiere aplicar el método de clasificación basado en SVMs. La estrategia de one-versus-one consiste en generar un total de K(K-1)/2 SVMs, comparando todos los posibles pares de clases. Para generar una predicción, se emplean cada uno de los K(K-1)/2 clasificadores, registrando el número de veces que la observación es asignada a cada una de las clases. Finalmente, se considera que la observación pertenece a la clase a la que ha sido asignada con más frecuencia. La principal desventaja de esta estrategia es que el número de modelos necesarios se dispara a medida que aumenta el número de clases, por lo que no es aplicable en todos los escenarios.
One-versus-all¶
Esta estrategia consiste en ajustar K SVMs distintos, cada uno comparando una de las K clases frente a las restantes K-1 clases. Como resultado, se obtiene un hiperplano de clasificación para cada clase. Para obtener una predicción, se emplean cada uno de los K clasificadores y se asigna la observación a la clase para la que la predicción resulte positiva. Esta aproximación, aunque sencilla, puede causar inconsistencias, ya que puede ocurrir que más de un clasificador resulte positivo, asignando así una misma observación a diferentes clases. Otro inconveniente adicional es que cada clasificador se entrena de forma no balanceada. Por ejemplo, si el set de datos contiene 100 clases con 10 observaciones por clase, cada clasificador se ajusta con 10 observaciones positivas y 990 negativas.
DAGSVM¶
DAGSVM (Directed Acyclic Graph SVM) es una mejora del método one-versus-one. La estrategia seguida es la misma, pero consiguen reducir su tiempo de ejecución eliminando comparaciones innecesarias gracias al empleo de una directed acyclic graph (DAG). Supóngase un set de datos con cuatro clases (A, B, C, D) y 6 clasificadores entrenados con cada posible par de clases (A-B, A-C, A-D, B-C, B-D, C-D). Se inician las comparaciones con el clasificador (A-D) y se obtiene como resultado que la observación pertenece a la clase A, o lo que es equivalente, que no pertenece a la clase D. Con esta información se pueden excluir todas las comparaciones que contengan la clase D, puesto que se sabe que no pertenece a este grupo. En la siguiente comparación se emplea el clasificador (A-C) y se predice que es A. Con esta nueva información se excluyen todas las comparaciones que contengan C. Finalmente solo queda emplear el clasificador (A-B) y asignar la observación al resultado devuelto. Siguiendo esta estrategia, en lugar de emplear los 6 clasificadores, solo ha sido necesario emplear 3. DAGSVM tiene las mismas ventajas que el método one-versus-one pero mejorando mucho el rendimiento.
Coste computacional¶
Debido a la utilización de kernels, en el ajuste de un SVM participa una matriz n x n, donde n es el número de observaciones de entrenamiento. Por esta razón, lo que más influye en el tiempo de computación necesario para entrenar un SVM es el número de observaciones, no el de predictores.
Ejemplo¶
Para el siguiente ejemplo se emplea un set de datos publicado en el libro Elements of Statistical Learning que contiene observaciones simuladas con una función no lineal en un espacio de dos dimensiones (2 predictores). El objetivo es entrenar un modelo SVM capaz de clasificar las observaciones.
Librerías¶
Las librerías utilizadas en este ejemplo son:
# Tratamiento de datos
# ==============================================================================
import pandas as pd
import numpy as np
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib.patches import Patch
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['font.size'] = 8
# Preprocesado y modelado
# ==============================================================================
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.inspection import DecisionBoundaryDisplay
# Configuración warnings
# ==============================================================================
import warnings
warnings.filterwarnings('once')
Datos¶
# Datos
# ==============================================================================
url = (
'https://raw.githubusercontent.com/JoaquinAmatRodrigo/'
'Estadistica-machine-learning-python/master/data/ESL.mixture.csv'
)
datos = pd.read_csv(url)
datos.head(3)
| X1 | X2 | y | |
|---|---|---|---|
| 0 | 2.526093 | 0.321050 | 0 |
| 1 | 0.366954 | 0.031462 | 0 |
| 2 | 0.768219 | 0.717486 | 0 |
fig, ax = plt.subplots(figsize=(6, 4))
# Obtener los dos primeros colores del estilo fivethirtyeight
colores_fivethirtyeight = plt.rcParams['axes.prop_cycle'].by_key()['color']
cmap_personalizado = ListedColormap(colores_fivethirtyeight[:2])
ax.scatter(
x = datos['X1'],
y = datos['X2'],
c = datos['y'],
s = 90,
cmap = cmap_personalizado,
alpha = 0.8,
edgecolors = 'black',
)
legend_elements = [
Patch(facecolor=colores_fivethirtyeight[0], edgecolor='black', label='Clase 0'),
Patch(facecolor=colores_fivethirtyeight[1], edgecolor='black', label='Clase 1')
]
ax.legend(handles=legend_elements, title='Clase', loc='best')
ax.set_title("Datos ESL.mixture");

SVM lineal¶
En Scikit Learn pueden encontrarse tres implementaciones distintas del algoritmo Support Vector Machine:
Las clases
sklearn.svm.SVCysklearn.svm.NuSVCpermiten crear modelos SVM de clasificación empleando kernel lineal, polinomial, radial o sigmoide. La diferencia es queSVCcontrola la regularización a través del hiperparámetroC, mientras queNuSVClo hace con el número máximo de vectores soporte permitidos.La clase
sklearn.svm.LinearSVCpermite ajustar modelos SVM con kernel lineal. Es similar aSVCcuando el parámetrokernel='linear', pero utiliza un algoritmo más rápido.
Las mismas implementaciones están disponibles para regresión en las clases: sklearn.svm.SVR, sklearn.svm.NuSVR y sklearn.svm.LinearSVR.
Se ajusta primero un modelo SVM con kernel lineal y después uno con kernel radial, y se compara la capacidad de cada uno para clasificar correctamente las observaciones.
# División de los datos en train y test
# ==============================================================================
X = datos.drop(columns = 'y')
y = datos['y']
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size = 0.8,
random_state = 1234,
shuffle = True
)
# Creación del modelo SVM lineal
# ==============================================================================
modelo = SVC(C=100, kernel='linear', random_state=123)
modelo.fit(X_train, y_train)
SVC(C=100, kernel='linear', random_state=123)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| C | 100 | |
| kernel | 'linear' | |
| degree | 3 | |
| gamma | 'scale' | |
| coef0 | 0.0 | |
| shrinking | True | |
| probability | False | |
| tol | 0.001 | |
| cache_size | 200 | |
| class_weight | None | |
| verbose | False | |
| max_iter | -1 | |
| decision_function_shape | 'ovr' | |
| break_ties | False | |
| random_state | 123 |
Al tratarse de un problema de dos dimensiones, se puede representar las regiones de clasificación.
# Representación gráfica de los límites de clasificación
# ==============================================================================
# Grid de valores
x = np.linspace(np.min(X_train.X1), np.max(X_train.X1), 50)
y = np.linspace(np.min(X_train.X2), np.max(X_train.X2), 50)
Y, X = np.meshgrid(y, x)
grid = pd.DataFrame(
np.vstack([X.ravel(), Y.ravel()]).T,
columns=['X1', 'X2']
)
# Predicción valores grid
pred_grid = modelo.predict(grid)
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(grid['X1'], grid['X2'], c=pred_grid, cmap=cmap_personalizado, alpha=0.2)
ax.scatter(X_train['X1'], X_train['X2'], c=y_train, cmap=cmap_personalizado, alpha=1)
# Vectores soporte
ax.scatter(
x = modelo.support_vectors_[:, 0],
y = modelo.support_vectors_[:, 1],
s = 200,
linewidth = 1,
facecolors = 'none',
edgecolors = 'black'
)
# Hiperplano de separación
ax.contour(
X,
Y,
modelo.decision_function(grid).reshape(X.shape),
colors = 'k',
levels = [-1, 0, 1],
alpha = 0.5,
linestyles = ['--', '-', '--']
)
ax.set_title("Resultados clasificación SVM lineal");

Se calcula el porcentaje de aciertos que tiene el modelo al predecir las observaciones de test (accuracy).
# Predicciones test
# ==============================================================================
predicciones = modelo.predict(X_test)
predicciones
array([1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0,
1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0])
# Accuracy de test del modelo
# ==============================================================================
accuracy = accuracy_score(
y_true = y_test,
y_pred = predicciones,
normalize = True
)
print("")
print(f"El accuracy de test es: {100*accuracy}%")
El accuracy de test es: 70.0%
SVM radial¶
Se repite el ajuste del modelo, esta vez empleando un kernel radial y utilizando validación cruzada para identificar el valor óptimo de penalización C.
# Grid de hiperparámetros
# ==============================================================================
param_grid = {'C': np.logspace(-5, 7, 20)}
# Búsqueda por validación cruzada
# ==============================================================================
grid = GridSearchCV(
estimator = SVC(kernel= "rbf", gamma='scale'),
param_grid = param_grid,
scoring = 'accuracy',
n_jobs = -1,
cv = 3,
verbose = 0,
return_train_score = True
)
# Se asigna el resultado a _ para que no se imprima por pantalla
_ = grid.fit(X=X_train, y=y_train)
# Resultados del grid
# ==============================================================================
resultados = pd.DataFrame(grid.cv_results_)
(
resultados.filter(regex = '(param.*|mean_t|std_t)')
.drop(columns = 'params')
.sort_values('mean_test_score', ascending = False)
.head(5)
)
| param_C | mean_test_score | std_test_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|
| 8 | 1.128838 | 0.762520 | 0.023223 | 0.790778 | 0.035372 |
| 12 | 379.269019 | 0.750641 | 0.076068 | 0.868777 | 0.007168 |
| 7 | 0.263665 | 0.750175 | 0.030408 | 0.778228 | 0.026049 |
| 9 | 4.832930 | 0.744118 | 0.044428 | 0.815729 | 0.026199 |
| 11 | 88.586679 | 0.738062 | 0.064044 | 0.859431 | 0.019840 |
# Mejores hiperparámetros por validación cruzada
# ==============================================================================
print("----------------------------------------")
print("Mejores hiperparámetros encontrados (cv)")
print("----------------------------------------")
print(grid.best_params_, ":", grid.best_score_, grid.scoring)
modelo = grid.best_estimator_
----------------------------------------
Mejores hiperparámetros encontrados (cv)
----------------------------------------
{'C': np.float64(1.1288378916846884)} : 0.7625203820172374 accuracy
# Representación gráfica de los límites de clasificación
# ==============================================================================
# Grid de valores
x = np.linspace(np.min(X_train.X1), np.max(X_train.X1), 50)
y = np.linspace(np.min(X_train.X2), np.max(X_train.X2), 50)
Y, X = np.meshgrid(y, x)
grid = pd.DataFrame(np.vstack([X.ravel(), Y.ravel()]).T, columns=['X1', 'X2'])
# Predicción valores grid
pred_grid = modelo.predict(grid)
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(grid['X1'], grid['X2'], c=pred_grid, alpha=0.2, cmap=cmap_personalizado)
ax.scatter(X_train['X1'], X_train['X2'], c=y_train, alpha=1, cmap=cmap_personalizado)
# Vectores soporte
ax.scatter(
modelo.support_vectors_[:, 0],
modelo.support_vectors_[:, 1],
s=200,
linewidth=1,
facecolors='none',
edgecolors='black'
)
# Hiperplano de separación
ax.contour(
X,
Y,
modelo.decision_function(grid).reshape(X.shape),
colors='k',
levels=[0],
alpha=0.5,
linestyles='-'
)
ax.set_title("Resultados clasificación SVM radial");

# Representación gráfica utilizando DecisionBoundaryDisplay de sklearn
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 4))
DecisionBoundaryDisplay.from_estimator(
modelo,
X_train,
cmap=cmap_personalizado,
alpha=0.3,
ax=ax,
response_method='predict'
)
# Añadir los puntos de entrenamiento
ax.scatter(
X_train['X1'],
X_train['X2'],
c=y_train,
cmap=cmap_personalizado,
edgecolors='black',
s=90
)
ax.set_title("Resultados clasificación SVM radial");

# Predicciones test
# ==============================================================================
predicciones = modelo.predict(X_test)
# Accuracy de test del modelo
# ==============================================================================
accuracy = accuracy_score(
y_true = y_test,
y_pred = predicciones,
normalize = True
)
print("")
print(f"El accuracy de test es: {100*accuracy}%")
El accuracy de test es: 80.0%
# Matriz de confusión de las predicciones de test
# ==============================================================================
confusion_matrix = pd.crosstab(
y_test,
predicciones,
rownames=['Real'],
colnames=['Predicción']
)
confusion_matrix
| Predicción | 0 | 1 |
|---|---|---|
| Real | ||
| 0 | 14 | 3 |
| 1 | 5 | 18 |
Conclusión¶
Con un modelo SVM de kernel radial se consigue clasificar correctamente el 80% de las observaciones de test. Se podría intentar mejorar aún más el modelo optimizando el valor del hiperparámetro gamma o utilizando otro tipo de kernel.
Información de sesión¶
import session_info
session_info.show(html=False)
----- matplotlib 3.10.8 numpy 2.2.6 pandas 2.3.3 session_info v1.0.1 sklearn 1.7.2 ----- IPython 9.8.0 jupyter_client 8.7.0 jupyter_core 5.9.1 ----- Python 3.13.11 | packaged by Anaconda, Inc. | (main, Dec 10 2025, 21:28:48) [GCC 14.3.0] Linux-6.14.0-37-generic-x86_64-with-glibc2.39 ----- Session information updated at 2026-01-07 23:02
Bibliografía¶
Introduction to Machine Learning with Python: A Guide for Data Scientists
Python Data Science Handbook by Jake VanderPlas
Support Vector Machines Succinctly by Alexandre Kowalczyk libro
An Introduction to Statistical Learning: with Applications in R (Springer Texts in Statistics)
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Máquinas de Vector Soporte (SVM) con Python por Joaquín Amat Rodrigo, disponible bajo una licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://www.cienciadedatos.net/documentos/py24-svm-python.html
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊



Este documento creado por Joaquín Amat Rodrigo tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.