More about forecasting in cienciadedatos.net
- ARIMA and SARIMAX models with python
- Time series forecasting with machine learning
- Forecasting time series with gradient boosting: XGBoost, LightGBM and CatBoost
- Forecasting time series with XGBoost
- Global Forecasting Models: Multi-series forecasting
- Global Forecasting Models: Comparative Analysis of Single and Multi-Series Forecasting Modeling
- Probabilistic forecasting
- Forecasting with deep learning
- Forecasting energy demand with machine learning
- Forecasting web traffic with machine learning
- Intermittent demand forecasting
- Modelling time series trend with tree-based models
- Bitcoin price prediction with Python
- Stacking ensemble of machine learning models to improve forecasting
- Interpretable forecasting models
- Mitigating the Impact of Covid on forecasting Models
- Forecasting time series with missing values

Introduction¶
A time series is a succession of chronologically ordered data spaced at equal or unequal intervals. The forecasting process consists of predicting the future value of a time series, either by modeling the series solely based on its past behavior (autoregressive) or by using other external variables. This document describes how to use machine learning in order to forecast the number of users who visit a website.
✏️ Note
Two other great examples of how to use machine learning for time series forecasting are:
Use case¶
The history of daily visits to the website cienciadedatos.net is available since 07/01/2020. The goal is to generate a forecasting model capable of predicting the web traffic during the next 7 days. The user wants to be able to run the model every Monday and obtain daily traffic predictions for the rest of the week.
To evaluate the performance of the model according to its intended use, it is advisable not to predict only the last 7 days of the time series, but to simulate the whole process. Backtesting is a special type of cross-validation applied to the previous period(s) and can be used with different configurations:
Backtesting with refit and increasing training size (fixed origin)
The model is trained each time before making predictions. With this configuration, the model uses all the data available so far. It is a variation of the standard cross-validation but, instead of making a random distribution of the observations, the training set increases sequentially, maintaining the temporal order of the data.
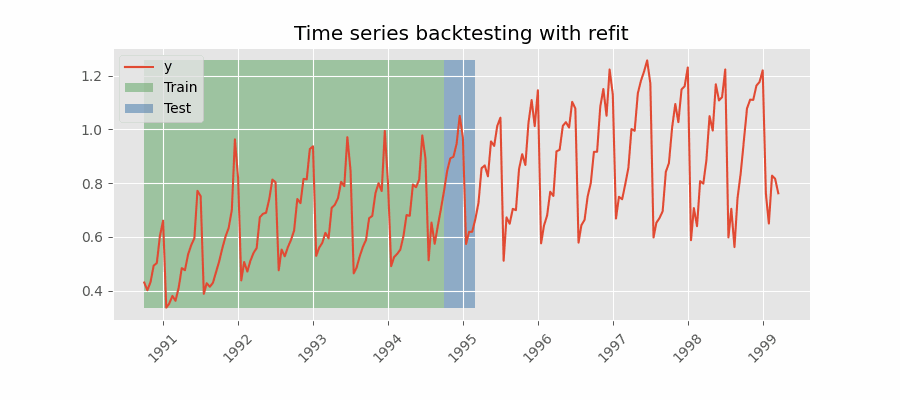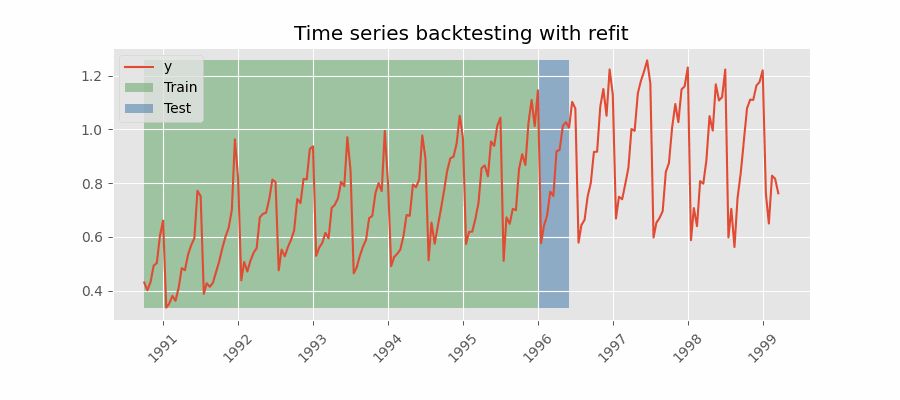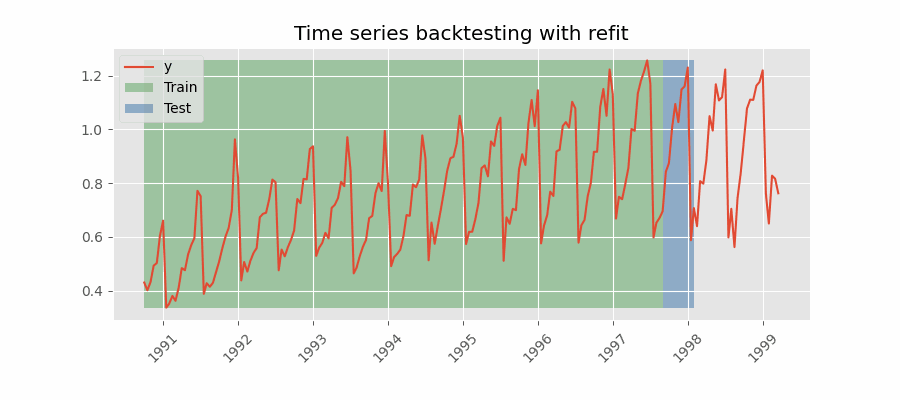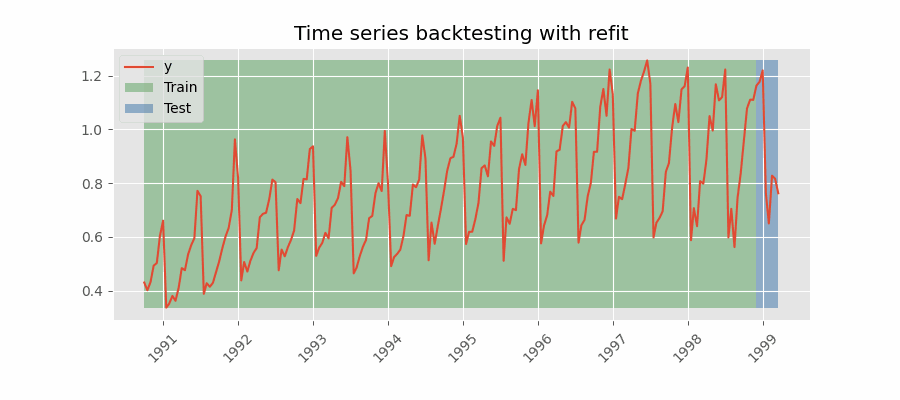
Backtesting with refit and fixed training size (rolling origin)
A technique similar to the previous one but, in this case, the forecast origin rolls forward, therefore, the size of training remains constant. This is also known as time series cross-validation or walk-forward validation.
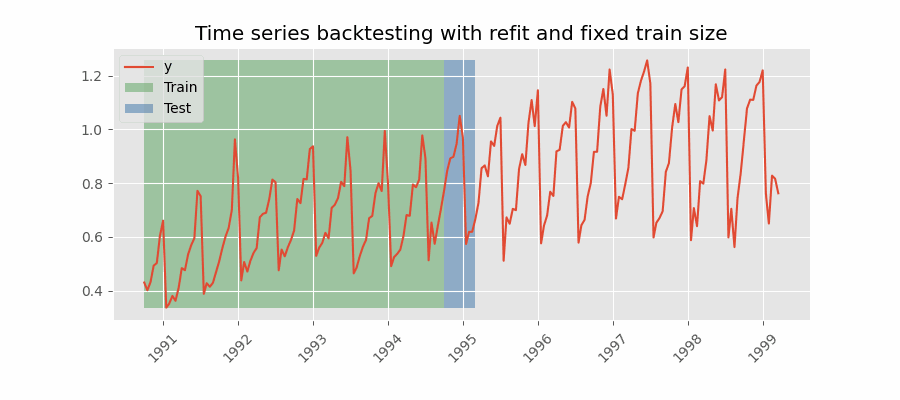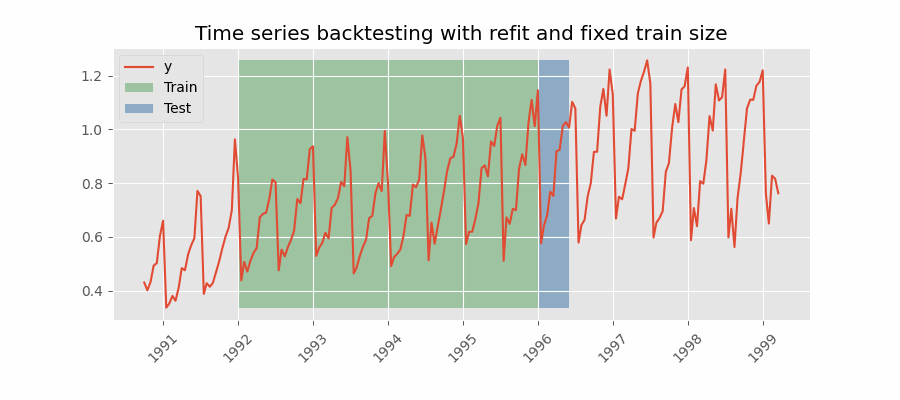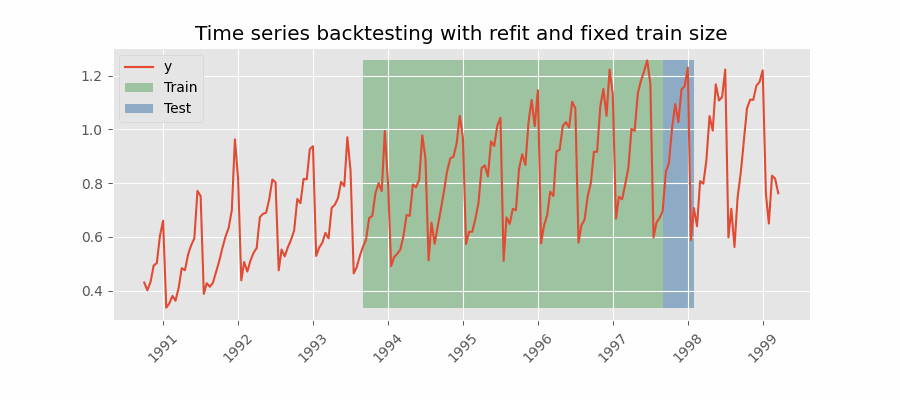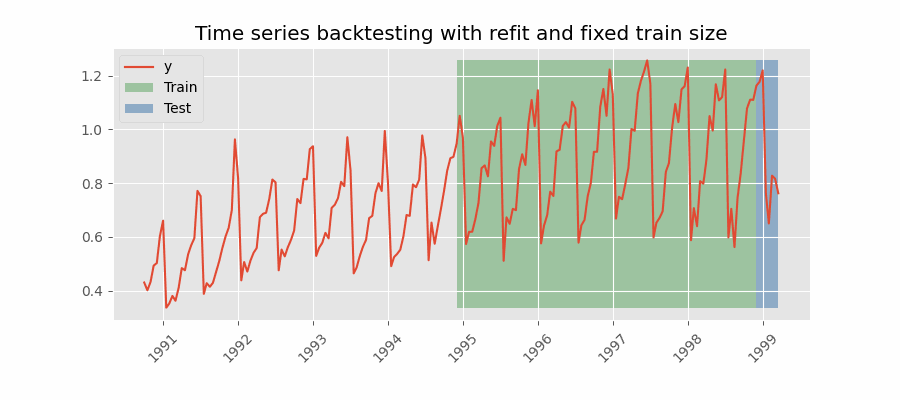
Backtesting with intermittent refit
The model is retrained every $n$ iterations of predictions.
💡 Tip
This strategy usually achieves a good balance between the computational cost of retraining and avoiding model degradation.
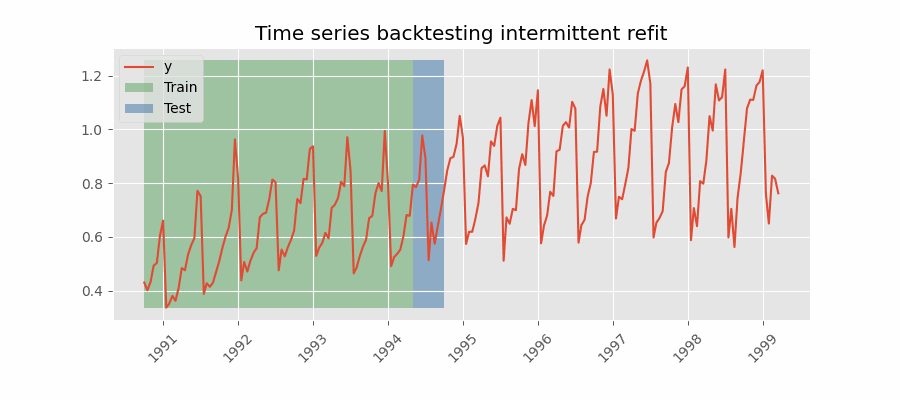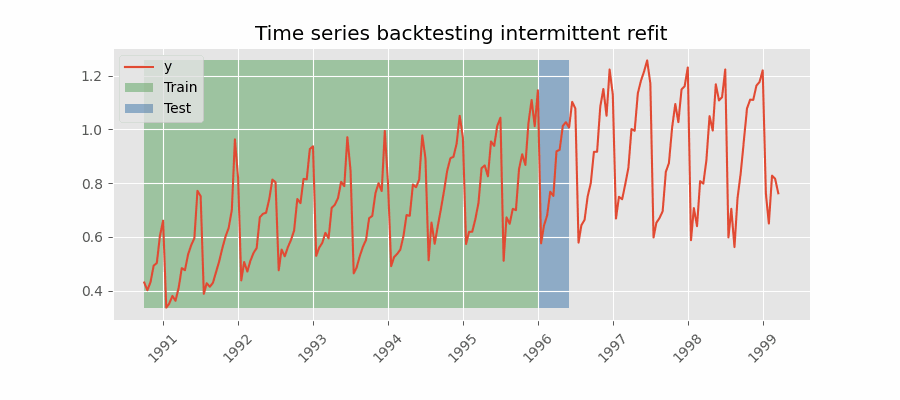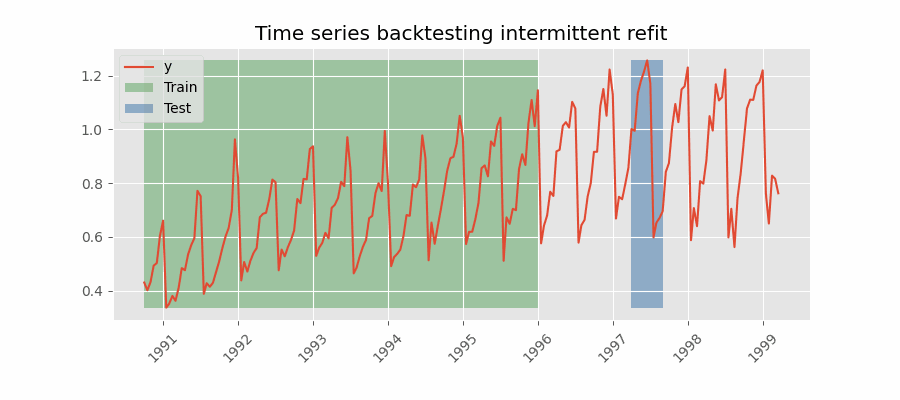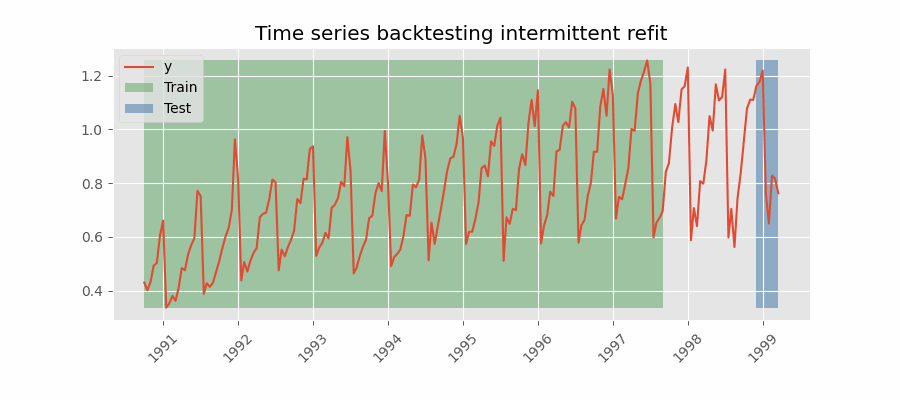
Backtesting without refit
After an initial train, the model is used sequentially without updating it and following the temporal order of the data. This strategy has the advantage of being much faster since the model is trained only once. However, the model does not incorporate the latest data available, so it may lose predictive capacity over time.
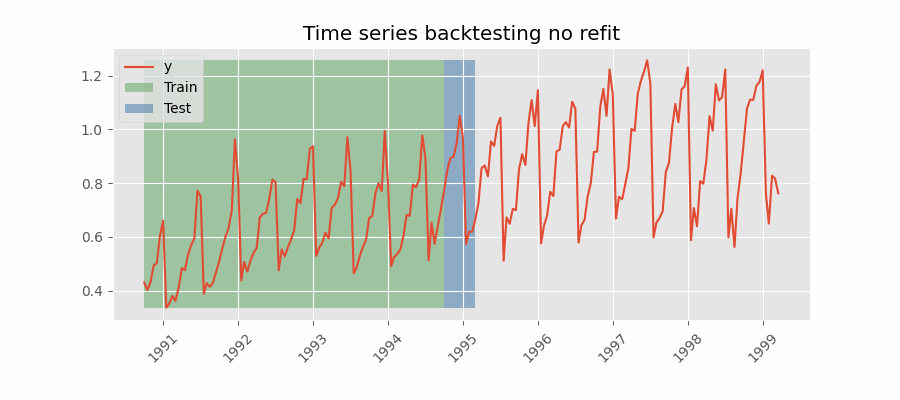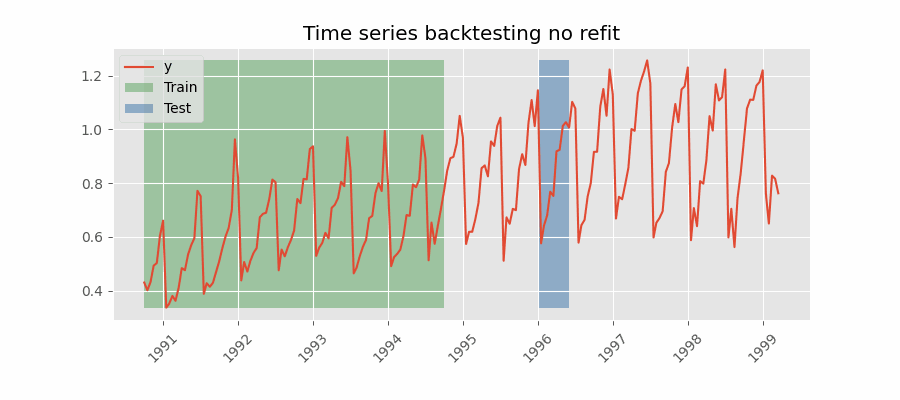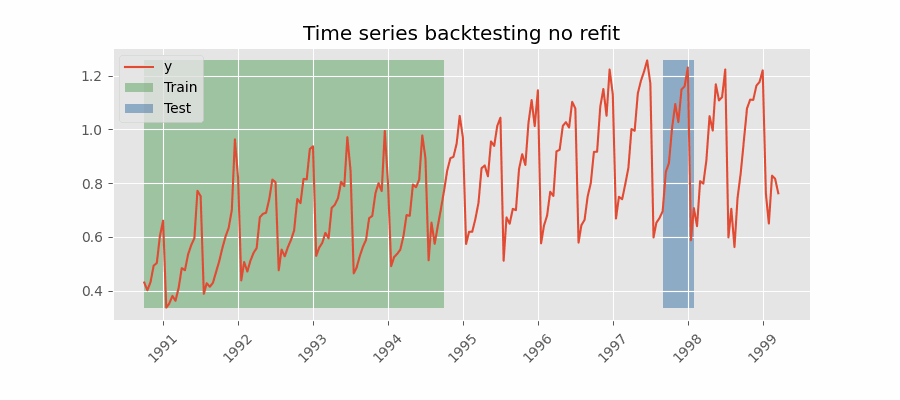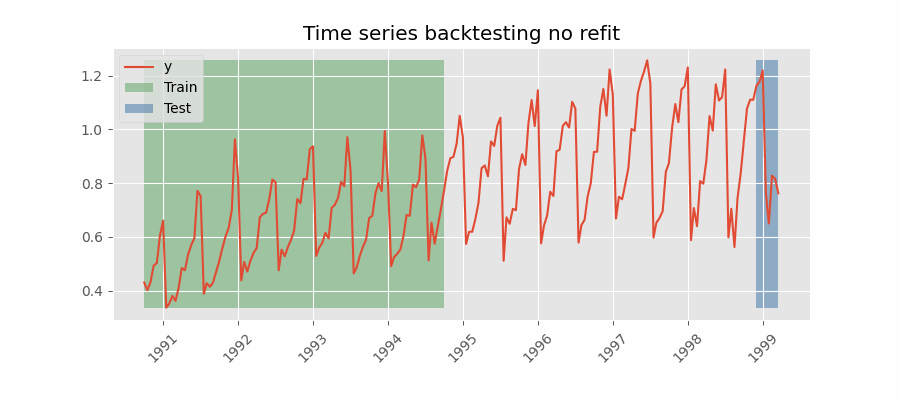
The most appropriate validation method will depend on the strategy to be used in production, whether the model will be periodically retrained or not before the prediction process. Regardless of the strategy used, it is important not to include test data in the search process to avoid overfitting problems.
For this example, a Backtesting with Refit and Increasing Training Size (Fixed Origin) strategy is followed. Internally, the process that the function applies is as follows:
In the first iteration, the model is trained with the observations selected for the initial training. Then, the next 7 observations (1 week) are predicted.
In the second iteration, the model is retrained by adding 7 observations to the initial training set, and then the next 7 observations (1 week) are predicted.
This process is repeated until all available observations are used. Following this strategy, the training set is increased in each iteration by as many observations as steps are predicted.
Libraries¶
Libraries used in this document are:
# Data processing
# ==============================================================================
import numpy as np
import pandas as pd
from skforecast.datasets import fetch_dataset
# Plots
# ==============================================================================
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import plotly.graph_objects as go
import plotly.io as pio
import plotly.offline as poff
pio.templates.default = "seaborn"
poff.init_notebook_mode(connected=True)
plt.style.use('seaborn-v0_8-darkgrid')
# Modelling and forecasting
# ==============================================================================
import skforecast
import sklearn
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from skforecast.recursive import ForecasterRecursive, ForecasterEquivalentDate
from skforecast.model_selection import TimeSeriesFold, grid_search_forecaster, backtesting_forecaster
from skforecast.stats import calculate_lag_autocorrelation
import shap
# Warnings config
# ==============================================================================
import warnings
warnings.filterwarnings('once')
color = '\033[1m\033[38;5;208m'
print(f"{color}Version skforecast: {skforecast.__version__}")
print(f"{color}Version scikit-learn: {sklearn.__version__}")
print(f"{color}Version pandas: {pd.__version__}")
print(f"{color}Version numpy: {np.__version__}")
Version skforecast: 0.23.0 Version scikit-learn: 1.7.2 Version pandas: 2.3.3 Version numpy: 2.4.6
Data¶
# Data downloading
# ==============================================================================
data = fetch_dataset(name="website_visits", raw=True)
╭───────────────────────────── website_visits ──────────────────────────────╮ │ Description: │ │ Daily visits to the cienciadedatos.net website registered with the google │ │ analytics service. │ │ │ │ Source: │ │ Amat Rodrigo, J. (2021). cienciadedatos.net (1.0.0). Zenodo. │ │ https://doi.org/10.5281/zenodo.10006330 │ │ │ │ URL: │ │ https://raw.githubusercontent.com/skforecast/skforecast- │ │ datasets/main/data/visitas_por_dia_web_cienciadedatos.csv │ │ │ │ Shape: 421 rows x 2 columns │ ╰───────────────────────────────────────────────────────────────────────────╯
Column date is stored as object. It is converted to datetime type using pd.to_datetime () function. Furthermore, it is set as an index to take advantage of pandas functionalities and finally, its frequency is set to 1 day.
# Data preprocessing
# ==============================================================================
data['date'] = pd.to_datetime(data['date'], format='%d/%m/%y')
data = data.set_index('date')
data = data.asfreq('1D')
data = data.sort_index()
data.head(3)
| users | |
|---|---|
| date | |
| 2020-07-01 | 2324 |
| 2020-07-02 | 2201 |
| 2020-07-03 | 2146 |
# Check index is complete and there are not missing values
# ==============================================================================
start_date = data.index.min()
end_date = data.index.max()
complete_date_range = pd.date_range(start=start_date, end=end_date, freq=data.index.freq)
is_index_complete = (data.index == complete_date_range).all()
print(f"Index complete: {is_index_complete}")
print(f"Number of rows with missing values: {data.isnull().any(axis=1).mean()}")
Index complete: True Number of rows with missing values: 0.0
The data set (starts on 2020-07-01 and ends on 2021-08-22), is divided into 3 partitions: one for training, one for validation and one for testing.
# Split data: train-validation-test
# ==============================================================================
end_train = '2021-03-30 23:59:00'
end_validation = '2021-06-30 23:59:00'
data_train = data.loc[: end_train, :]
data_val = data.loc[end_train:end_validation, :]
data_test = data.loc[end_validation:, :]
print(f"Training dates : {data_train.index.min()} --- {data_train.index.max()} (n={len(data_train)})")
print(f"Validation dates : {data_val.index.min()} --- {data_val.index.max()} (n={len(data_val)})")
print(f"Test dates : {data_test.index.min()} --- {data_test.index.max()} (n={len(data_test)})")
Training dates : 2020-07-01 00:00:00 --- 2021-03-30 00:00:00 (n=273) Validation dates : 2021-03-31 00:00:00 --- 2021-06-30 00:00:00 (n=92) Test dates : 2021-07-01 00:00:00 --- 2021-08-25 00:00:00 (n=56)
Graphical exploration¶
When working with time series, it is important to represent their values. This allows patterns such as trends and seasonality to be identified.
Time series
# Interactive plot of time series
# ==============================================================================
fig = go.Figure()
fig.add_trace(go.Scatter(x=data_train.index, y=data_train['users'], mode='lines', name='Train'))
fig.add_trace(go.Scatter(x=data_val.index, y=data_val['users'], mode='lines', name='Validation'))
fig.add_trace(go.Scatter(x=data_test.index, y=data_test['users'], mode='lines', name='Test'))
fig.update_layout(
title = 'Daily visitors',
xaxis_title="Time",
yaxis_title="Users",
width=750,
height=350,
margin=dict(l=20, r=20, t=35, b=20),
legend=dict(orientation="h", yanchor="top", y=1.12, xanchor="left", x=0.001)
)
fig.show()
Seasonality
fig, axs = plt.subplot_mosaic(
"""
AB
CC
""",
sharey=True
)
# Users distribution by month
data['month'] = data.index.month
data.boxplot(column='users', by='month', ax=axs['A'])
data.groupby('month')['users'].median().plot(style='o-', linewidth=0.8, ax=axs['A'])
axs['A'].set_ylabel('Users')
axs['A'].set_title('Users distribution by month', fontsize=9)
# Users distribution by week day
data['week_day'] = data.index.day_of_week + 1
data.boxplot(column='users', by='week_day', ax=axs['B'])
data.groupby('week_day')['users'].median().plot(style='o-', linewidth=0.8, ax=axs['B'])
axs['B'].set_ylabel('Users')
axs['B'].set_title('Users distribution by week day', fontsize=9)
# Users distribution by month day
data['month_day'] = data.index.day
data.boxplot(column='users', by='month_day', ax=axs['C'])
data.groupby('month_day')['users'].median().plot(style='o-', linewidth=0.8, ax=axs['C'])
axs['C'].set_ylabel('Users')
axs['C'].set_title('Users distribution by month day', fontsize=9)
fig.suptitle("Seasonality plots", fontsize=12)
fig.tight_layout()

It cannot be determined if there is an annual seasonality since the data does not span two years. However, there is a weekly seasonality, with a reduction in web traffic on weekends.
Autocorrelation plots
Auto-correlation plots are a useful tool for identifying the order of an autoregressive model. The autocorrelation function (ACF) is a measure of the correlation between the time series and a lagged version of itself. The partial autocorrelation function (PACF) is a measure of the correlation between the time series and a lagged version of itself, controlling for the values of the time series at all shorter lags. These plots are useful for identifying the lags to be included in the autoregressive model.
# Autocorrelation plot
# ==============================================================================
fig, ax = plt.subplots(figsize=(5, 2))
plot_acf(data['users'], ax=ax, lags=50, fft=True)
plt.show()

# Partial autocorrelation plot
# ==============================================================================
fig, ax = plt.subplots(figsize=(5, 2))
plot_pacf(data['users'], ax=ax, lags=50, method='burg')
plt.show()

# Top 10 lags with the highest absolute partial autocorrelation
# ==============================================================================
calculate_lag_autocorrelation(
data = data['users'],
n_lags = 60,
sort_by = "partial_autocorrelation_abs"
).head(10)
| lag | partial_autocorrelation_abs | partial_autocorrelation | autocorrelation_abs | autocorrelation | |
|---|---|---|---|---|---|
| 0 | 1 | 0.865897 | 0.865897 | 0.865897 | 0.865897 |
| 1 | 8 | 0.660998 | -0.660998 | 0.739243 | 0.739243 |
| 2 | 6 | 0.558165 | 0.558165 | 0.782706 | 0.782706 |
| 3 | 5 | 0.376389 | 0.376389 | 0.636391 | 0.636391 |
| 4 | 3 | 0.325238 | 0.325238 | 0.598038 | 0.598038 |
| 5 | 15 | 0.275001 | -0.275001 | 0.577816 | 0.577816 |
| 6 | 2 | 0.259590 | -0.259590 | 0.684822 | 0.684822 |
| 7 | 22 | 0.168378 | -0.168378 | 0.392733 | 0.392733 |
| 8 | 23 | 0.154417 | 0.154417 | 0.221251 | 0.221251 |
| 9 | 7 | 0.152392 | 0.152392 | 0.874265 | 0.874265 |
Autocorrelation and partial autocorrelation plots show a clear association between the number of users on a day and the previous days. This is an indication that autoregressive models may achive good predictions.
Baseline¶
When faced with a forecasting problem, it is important to establish a baseline model. This is usually a very simple model that can be used as a reference to assess whether more complex models are worth implementing.
Skforecast allows you to easily create a baseline with its class ForecasterEquivalentDate. This model, also known as Seasonal Naive Forecasting, simply returns the value observed in the same period of the previous season (e.g., the same working day from the previous week, the same hour from the previous day, etc.).
Based on the exploratory analysis performed, the baseline model will be the one that predicts each hour using the value of the same hour on the previous day.
# Create baseline: value of the previous day
# ==============================================================================
forecaster = ForecasterEquivalentDate(
offset = pd.DateOffset(days=1),
n_offsets = 1
)
# Train forecaster
# ==============================================================================
forecaster.fit(y=data.loc[:end_validation, 'users'])
forecaster
ForecasterEquivalentDate
General Information
- Estimator: NoneType
- Offset:
- Number of offsets: 1
- Aggregation function: mean
- Window size: 1
- Creation date: 2026-07-13 22:19:01
- Last fit date: 2026-07-13 22:19:01
- Skforecast version: 0.23.0
- Python version: 3.13.14
- Forecaster id: None
Training Information
- Training range: [Timestamp('2020-07-01 00:00:00'), Timestamp('2021-06-30 00:00:00')]
- Training index type: DatetimeIndex
- Training index frequency: D
# Backtesting
# ==============================================================================
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(data.loc[:end_validation]),
refit = False,
)
metric_baseline, predictions = backtesting_forecaster(
forecaster = forecaster,
y = data['users'],
cv = cv,
metric = 'mean_absolute_error'
)
metric_baseline
| mean_absolute_error | |
|---|---|
| 0 | 513.035714 |
Autoregressive model¶
An autoregressive model (ForecasterRecursive) is trained using a linear model with ridge regularization.
Ridge models require the data to be standardized. To this end, the transformer_y argument is used to incorporate a StandarScaler in the forecaster. For more on the use of transformers see Forecasting with scikit-learn and transformers pipelines.
Forecaster¶
# Create forecaster
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = Ridge(random_state=123),
lags = 14,
transformer_y = StandardScaler(),
forecaster_id = 'web_traffic'
)
Tuning the hyper-parameters¶
To identify the best combination of lags and hyperparameters, a grid search is used. This process consists of training a model with each combination of hyperparameters-lags, and evaluating its predictive capacity using backtesting. It is important to evaluate the models using only the validation data and not include the test data.
# Grid search of hyper-parameters
# ==============================================================================
# Estimator's hyper-parameters
param_grid = {'alpha': np.logspace(-3, 3, 10)}
# Lags used as predictors
lags_grid = [7, 14, 21, [7, 14, 21]]
# Folds
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(data_train),
refit = False,
)
results_search = grid_search_forecaster(
forecaster = forecaster,
y = data.loc[:end_validation, 'users'],
param_grid = param_grid,
lags_grid = lags_grid,
cv = cv,
metric = 'mean_absolute_error'
)
best_params = results_search['params'].iat[0]
results_search.head()
| lags | lags_label | params | mean_absolute_error | alpha | |
|---|---|---|---|---|---|
| 0 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 2.154434690031882} | 214.791677 | 2.154435 |
| 1 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.46415888336127775} | 216.551409 | 0.464159 |
| 2 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.1} | 217.770757 | 0.100000 |
| 3 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.021544346900318832} | 218.127429 | 0.021544 |
| 4 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.004641588833612777} | 218.206475 | 0.004642 |
The best results are obtained using lags [1 2 3 4 5 6 7 8 9 10 11 12 13 14] and a configuration of Ridge {'alpha': 2.154}. By indicating return_best = True in the grid_search_forecaster() function, at the end of the process, the forecaster object is automatically retrained with the best configuration and the whole data set.
forecaster
ForecasterRecursive
General Information
- Estimator: Ridge
- Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
- Window features: None
- Calendar features: None
- Window size: 14
- Series name: users
- Exogenous included: False
- Categorical features: auto
- Weight function included: False
- Differentiation order: None
- Drop NaN from series: False
- Creation date: 2026-07-13 22:19:02
- Last fit date: 2026-07-13 22:19:03
- Skforecast version: 0.23.0
- Python version: 3.13.14
- Forecaster id: web_traffic
Exogenous Variables
None
Data Transformations
- Transformer for y: StandardScaler()
- Transformer for exog: None
Training Information
- Training range: [Timestamp('2020-07-01 00:00:00'), Timestamp('2021-06-30 00:00:00')]
- Training index type: DatetimeIndex
- Training index frequency: D
Estimator Parameters
-
{'alpha': np.float64(2.154434690031882), 'copy_X': True, 'fit_intercept': True, 'max_iter': None, 'positive': False, 'random_state': 123, 'solver': 'auto', 'tol': 0.0001}
Fit Kwargs
-
{}
Backtesting¶
Once the best model has been identified and trained (using both, the training and the validation set), its prediction error is calculated with the test set.
# Backtest final model using test data
# ==============================================================================
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(data.loc[:end_validation]),
refit = True,
fixed_train_size = False,
)
metric, predictions = backtesting_forecaster(
forecaster = forecaster,
y = data.users,
cv = cv,
metric = 'mean_absolute_error',
verbose = True,
)
metric
Information of folds
--------------------
Number of observations used for initial training: 365
Number of observations used for backtesting: 56
Number of folds: 8
Number skipped folds: 0
Number of steps per fold: 7
Number of steps to exclude between last observed data (last window) and predictions (gap): 0
Fold: 0
Training: 2020-07-01 00:00:00 -- 2021-06-30 00:00:00 (n=365)
Validation: 2021-07-01 00:00:00 -- 2021-07-07 00:00:00 (n=7)
Fold: 1
Training: 2020-07-01 00:00:00 -- 2021-07-07 00:00:00 (n=372)
Validation: 2021-07-08 00:00:00 -- 2021-07-14 00:00:00 (n=7)
Fold: 2
Training: 2020-07-01 00:00:00 -- 2021-07-14 00:00:00 (n=379)
Validation: 2021-07-15 00:00:00 -- 2021-07-21 00:00:00 (n=7)
Fold: 3
Training: 2020-07-01 00:00:00 -- 2021-07-21 00:00:00 (n=386)
Validation: 2021-07-22 00:00:00 -- 2021-07-28 00:00:00 (n=7)
Fold: 4
Training: 2020-07-01 00:00:00 -- 2021-07-28 00:00:00 (n=393)
Validation: 2021-07-29 00:00:00 -- 2021-08-04 00:00:00 (n=7)
Fold: 5
Training: 2020-07-01 00:00:00 -- 2021-08-04 00:00:00 (n=400)
Validation: 2021-08-05 00:00:00 -- 2021-08-11 00:00:00 (n=7)
Fold: 6
Training: 2020-07-01 00:00:00 -- 2021-08-11 00:00:00 (n=407)
Validation: 2021-08-12 00:00:00 -- 2021-08-18 00:00:00 (n=7)
Fold: 7
Training: 2020-07-01 00:00:00 -- 2021-08-18 00:00:00 (n=414)
Validation: 2021-08-19 00:00:00 -- 2021-08-25 00:00:00 (n=7)
| mean_absolute_error | |
|---|---|
| 0 | 211.974974 |
Exogenous features¶
In the previous example, only lags of the target variable itself were used as predictors. In certain situations, it is possible to have information on other variables whose future value is known, which can be used as additional predictors in the model. Some typical examples are:
Holidays (local, national...)
Month of the year
Day of the week
Time of day
In this use case, the graphical analysis showed evidence that the number of visits to the website decreases at weekends. The day of the week that each date corresponds to can be known in advance, so it can be used as an exogenous variable. See how it affects the models when this information is included as a predictor.
# Features based on calendar
# ==============================================================================
data['month'] = data.index.month
data['month_day'] = data.index.day
data['week_day'] = data.index.day_of_week
data.head()
| users | month | week_day | month_day | |
|---|---|---|---|---|
| date | ||||
| 2020-07-01 | 2324 | 7 | 2 | 1 |
| 2020-07-02 | 2201 | 7 | 3 | 2 |
| 2020-07-03 | 2146 | 7 | 4 | 3 |
| 2020-07-04 | 1666 | 7 | 5 | 4 |
| 2020-07-05 | 1433 | 7 | 6 | 5 |
# One hot encoding transformer
# ==============================================================================
one_hot_encoder = make_column_transformer(
(
OneHotEncoder(sparse_output=False, drop='if_binary'),
['month', 'week_day', 'month_day'],
),
remainder="passthrough",
verbose_feature_names_out=False,
).set_output(transform="pandas")
data = one_hot_encoder.fit_transform(data)
data.head()
| month_1 | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | ... | month_day_23 | month_day_24 | month_day_25 | month_day_26 | month_day_27 | month_day_28 | month_day_29 | month_day_30 | month_day_31 | users | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2020-07-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2324 |
| 2020-07-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2201 |
| 2020-07-03 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2146 |
| 2020-07-04 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1666 |
| 2020-07-05 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1433 |
5 rows × 51 columns
# Split data train-val-test
# ==============================================================================
data_train = data.loc[: end_train, :]
data_val = data.loc[end_train:end_validation, :]
data_test = data.loc[end_validation:, :]
exog_features = [col for col in data.columns if col.startswith(('month_', 'week_day_', 'month_day_'))]
# Create forecaster
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = Ridge(**best_params, random_state=123),
lags = 14,
transformer_y = StandardScaler(),
forecaster_id = 'web_traffic'
)
# Backtest forecaster with exogenous features
# ==============================================================================
metric, predictions = backtesting_forecaster(
forecaster = forecaster,
y = data.users,
exog = data[exog_features],
cv = cv,
metric = 'mean_absolute_error'
)
display(metric)
predictions.head(5)
| mean_absolute_error | |
|---|---|
| 0 | 149.058991 |
| fold | pred | |
|---|---|---|
| 2021-07-01 | 0 | 3109.259189 |
| 2021-07-02 | 0 | 2914.336919 |
| 2021-07-03 | 0 | 2318.810952 |
| 2021-07-04 | 0 | 1957.766737 |
| 2021-07-05 | 0 | 3002.216742 |
# Plot predictions vs real value
# ======================================================================================
fig = go.Figure()
trace1 = go.Scatter(x=data_test.index, y=data_test['users'], name="test", mode="lines")
trace2 = go.Scatter(x=predictions.index, y=predictions['pred'], name="prediction", mode="lines")
fig.add_trace(trace1)
fig.add_trace(trace2)
fig.update_layout(
title="Real value vs predicted in test data",
xaxis_title="Date time",
yaxis_title="Users",
width=750,
height=350,
margin=dict(l=20, r=20, t=35, b=20),
legend=dict(orientation="h", yanchor="top", y=1.1, xanchor="left", x=0.001)
)
fig.show()
Finally, the model is trained using the best parameters, lags, and all available data.
# Create and train forecaster with the best hyperparameters and lags found
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = Ridge(**best_params, random_state=123),
lags = 14,
transformer_y = StandardScaler(),
forecaster_id = 'web_traffic'
)
forecaster.fit(y=data['users'], exog=data[exog_features], store_in_sample_residuals=True)
Feature importance¶
Skforecast is compatible with some of the most popular model explainability methods: model-specific feature importances, SHAP values, and partial dependence plots.
Model-specific feature importance
# Extract feature importance
# ==============================================================================
importance = forecaster.get_feature_importances()
importance.head(10)
| feature | importance | |
|---|---|---|
| 0 | lag_1 | 0.753168 |
| 26 | week_day_0 | 0.411202 |
| 5 | lag_6 | 0.230151 |
| 24 | month_11 | 0.195164 |
| 6 | lag_7 | 0.166955 |
| 30 | week_day_4 | 0.096308 |
| 2 | lag_3 | 0.092973 |
| 55 | month_day_23 | 0.091812 |
| 35 | month_day_3 | 0.090239 |
| 23 | month_10 | 0.086671 |
⚠️ Warning
The get_feature_importances() method will only return values if the forecaster's estimator has either the coef_ or feature_importances_ attribute, which is the default in scikit-learn.
Shap values
SHAP (SHapley Additive exPlanations) values are a popular method for explaining machine learning models, as they help to understand how variables and values influence predictions visually and quantitatively.
It is possible to generate SHAP-values explanations from skforecast models with just two essential elements:
The internal estimator of the forecaster.
The training matrices created from the time series and used to fit the forecaster.
By leveraging these two components, users can create insightful and interpretable explanations for their skforecast models. These explanations can be used to verify the reliability of the model, identify the most significant factors that contribute to model predictions, and gain a deeper understanding of the underlying relationship between the input variables and the target variable.
# Training matrices used by the forecaster to fit the internal estimator
# ==============================================================================
X_train, y_train = forecaster.create_train_X_y(
y = data_train['users'],
exog = data_train[exog_features]
)
# Create SHAP explainer (for linear models)
# ==============================================================================
explainer = shap.LinearExplainer(forecaster.estimator, X_train)
shap_values = explainer.shap_values(X_train)
# Shap summary plot (top 10)
# ==============================================================================
shap.initjs()
shap.summary_plot(shap_values, X_train, max_display=10, show=False)
fig, ax = plt.gcf(), plt.gca()
ax.set_title("SHAP Summary plot")
ax.tick_params(labelsize=8)
fig.set_size_inches(6, 3.5)


Probabilistic forecasting: Prediction intervals¶
A prediction interval defines the interval within which the true value of the target variable can be expected to be found with a given probability. Skforecast implements several methods for probabilistic forecasting:
The function backtesting_forecaster and allow obtaining their intervals in addition to the predictions.
# Backtest with prediction intervals
# ==============================================================================
metric, predictions = backtesting_forecaster(
forecaster = forecaster,
y = data.users,
exog = data[exog_features],
cv = cv,
metric = 'mean_absolute_error',
interval = [0.1, 0.9],
n_boot = 250
)
display(metric)
predictions.head(5)
| mean_absolute_error | |
|---|---|
| 0 | 149.058991 |
| fold | pred | lower_bound | upper_bound | |
|---|---|---|---|---|
| 2021-07-01 | 0 | 3109.259189 | 3004.224962 | 3310.050325 |
| 2021-07-02 | 0 | 2914.336919 | 2664.338306 | 3208.135842 |
| 2021-07-03 | 0 | 2318.810952 | 2004.743839 | 2578.830978 |
| 2021-07-04 | 0 | 1957.766737 | 1657.452071 | 2174.728528 |
| 2021-07-05 | 0 | 3002.216742 | 2608.296170 | 3294.607486 |
# Plot prediction intervals vs real value
# ==============================================================================
fig = go.Figure([
go.Scatter(
name='Prediction',
x=predictions.index,
y=predictions['pred'],
mode='lines',
),
go.Scatter(
name='Real value',
x=data_test.index,
y=data_test.loc[:, 'users'],
mode='lines',
),
go.Scatter(
name='Upper Bound',
x=predictions.index,
y=predictions['upper_bound'],
mode='lines',
marker=dict(color="#444"),
line=dict(width=0),
showlegend=False
),
go.Scatter(
name='Lower Bound',
x=predictions.index,
y=predictions['lower_bound'],
marker=dict(color="#444"),
line=dict(width=0),
mode='lines',
fillcolor='rgba(68, 68, 68, 0.3)',
fill='tonexty',
showlegend=False
)
])
fig.update_layout(
title="Forecasting intervals",
xaxis_title="Date time",
yaxis_title="users",
width=750,
height=350,
margin=dict(l=20, r=20, t=35, b=20),
hovermode="x",
legend=dict(orientation="h", yanchor="top", y=1.1, xanchor="left", x=0.001)
)
fig.show()
✏️ Note
For a detailed explanation of the probabilistic forecasting features available in skforecast, visit: Probabilistic forecasting with machine learning
Conclusion¶
The autorregresive model based on a linear estimator with ridge regularization has been able to predict the number of daily visits to the website with an MAE of 149 users. The model has been trained using the best configuration of lags and hyperparameters, and has been evaluated using backtesting. The inclusion of the exogenous variables based on calendar dates has improved the model's performance.
| Model | Exogenous features | MAE backtest |
|---|---|---|
| BaseLine | False | 513.04 |
| Autoregressive-ridge | False | 211.98 |
| Autoregressive-ridge | True | 149.06 |
How to further improve the model:
Adding as exogenous feature vacation days.
Using non linear regressors such as random forest or gradient boosting Forecasting time series with gradient boosting: Skforecast, XGBoost, LightGBM and CatBoost.
Using a direct multi-step forecaster.
Session information¶
import session_info
session_info.show(html=False)
----- matplotlib 3.11.0 numpy 2.4.6 pandas 2.3.3 plotly 6.9.0 session_info v1.0.1 shap 0.52.0 skforecast 0.23.0 sklearn 1.7.2 statsmodels 0.14.6 ----- IPython 9.15.0 jupyter_client 8.9.1 jupyter_core 5.9.1 ----- Python 3.13.14 | packaged by conda-forge | (main, Jun 12 2026, 09:50:25) [GCC 14.3.0] Linux-7.0.0-1008-aws-x86_64-with-glibc2.43 ----- Session information updated at 2026-07-13 22:19
Citation¶
How to cite this document
If you use this document or any part of it, please acknowledge the source, thank you!
Forecasting web traffic with machine learning by Joaquín Amat Rodrigo and Javier Escobar Ortiz, available under Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) at https://cienciadedatos.net/documentos/py37-forecasting-visitas-web-machine-learning.html
How to cite skforecast
If you use skforecast for a publication, we would appreciate it if you cite the published software.
Zenodo:
Amat Rodrigo, Joaquin, & Escobar Ortiz, Javier. (2024). skforecast (v0.23.0). Zenodo. https://doi.org/10.5281/zenodo.8382788
APA:
Amat Rodrigo, J., & Escobar Ortiz, J. (2024). skforecast (Version 0.23.0) [Computer software]. https://doi.org/10.5281/zenodo.8382788
BibTeX:
@software{skforecast, author = {Amat Rodrigo, Joaquin and Escobar Ortiz, Javier}, title = {skforecast}, version = {0.23.0}, month = {07}, year = {2026}, license = {BSD-3-Clause}, url = {https://skforecast.org/}, doi = {10.5281/zenodo.8382788} }
Did you like the article? Your support is important
Your contribution will help me to continue generating free educational content. Many thanks! 😊




This work by Joaquín Amat Rodrigo and Javier Escobar Ortiz is licensed under a Attribution-NonCommercial-ShareAlike 4.0 International.
Allowed:
-
Share: copy and redistribute the material in any medium or format.
-
Adapt: remix, transform, and build upon the material.
Under the following terms:
-
Attribution: You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
-
NonCommercial: You may not use the material for commercial purposes.
-
ShareAlike: If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.