More about forecasting in cienciadedatos.net
- ARIMA and SARIMAX models with python
- Time series forecasting with machine learning
- Forecasting time series with gradient boosting: XGBoost, LightGBM and CatBoost
- Forecasting time series with XGBoost
- Global Forecasting Models: Multi-series forecasting
- Global Forecasting Models: Comparative Analysis of Single and Multi-Series Forecasting Modeling
- Probabilistic forecasting
- Forecasting with deep learning
- Forecasting energy demand with machine learning
- Forecasting web traffic with machine learning
- Intermittent demand forecasting
- Modelling time series trend with tree-based models
- Bitcoin price prediction with Python
- Stacking ensemble of machine learning models to improve forecasting
- Interpretable forecasting models
- Mitigating the Impact of Covid on Forecasting Models
- Forecasting time series with missing values

Introduction¶
The M5 Accuracy competition dataset involves the unit sales of 3,049 products, classified in 3 product categories (Hobbies, Foods, and Household), and 7 product departments in which the above-mentioned categories are disaggregated. The products are sold across 10 stores, located in 3 States (CA, TX, and WI). The competition’s objective was to produce the most accurate point forecasts for 42,840 time series that represent the hierarchical unit sales of the largest retail company in the world, Walmart.
The following are some of the main characteristics of the M5 Accuracy competition dataset:
M5 consisted of grouped, highly correlated series, organized in a hierarchical, cross-sectional structure, thus representing the forecasting set-up of a typical retail company.
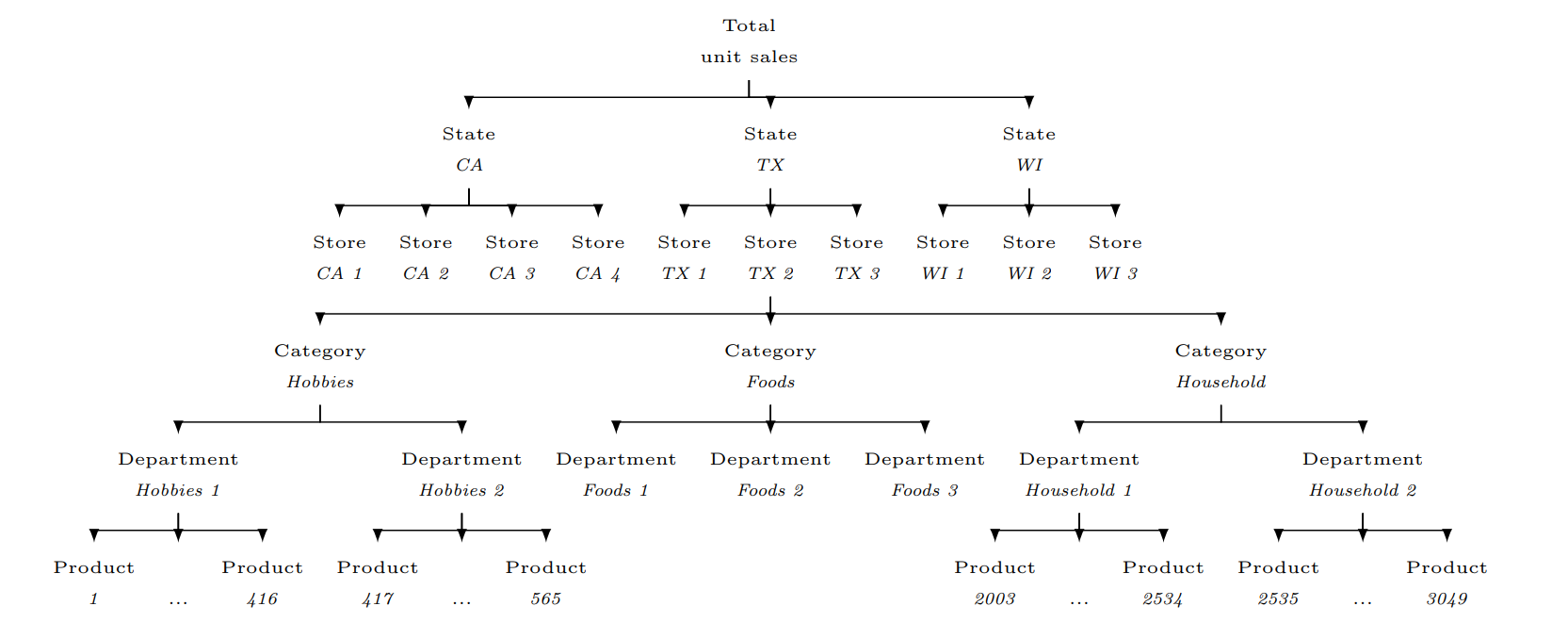
Time series hierarchy
The competition involved series that display intermittency, i.e., sporadic demand including many zeros.
The data is daily and covers the period from 2011-01-29 to 2016-06-19 (1,969 days or approximately 5.4 years). The first 1,913 days of data (2011-01-29 to 2016-04-24) were initially provided to the participating teams as a train set, days 1,914 to 1941 (2016-04-25 to 2016-05-22) served as a validation set, while the remaining 28 days, i.e., 1,942 to 1,969 (2016-05-23 to 2016-06-19), were used as a test set.
Special events and holidays (e.g. Super Bowl, Valentine’s Day, and Orthodox Easter) are organized into four classes: Sporting, Cultural, National, and Religious.
Selling prices are provided on a week-store level (average across seven days). If not available, this means that the product was not available during the week examined. Although prices are constant on a weekly basis, they may change with time. Note: The absence of a selling price means the product was not available for sale. However, there may be instances where a selling price is recorded (indicating availability) even if no sales occurred during that period.
SNAP 8 activities that serve as promotions. This is a binary variable (0 or 1) indicating whether the stores of CA, TX or WI allow SNAP purchases on the date examined. 1 indicates that SNAP purchases are allowed. The United States federal government provides a nutrition assistance benefit called the Supplement Nutrition Assistance Program (SNAP). SNAP provides low income families and individuals with an Electronic Benefits Transfer debit card to purchase food products. In many states, the monetary benefits are dispersed to people across 10 days of the month and on each of these days 1/10 of the people will receive the benefit on their card.
M5 Accuracy competition utilized a variant of the MASE originally proposed by Hyndman & Koehler (2006), to be called Root Mean Squared Scaled Error (RMSSE). The measure is defined as follows:
$$ \text{RMSSE} = \sqrt{ \frac{\frac{1}{h} \sum_{t=n+1}^{n+h} (y_t - \hat{y}_t)^2}{\frac{1}{n-1} \sum_{t=2}^{n} (y_t - y_{t-1})^2}} $$
where $(y_t)$ is the actual value of the series at time $(t)$, $(\hat{y}_t)$ is the forecasted value of the series at time $(t)$, $(n)$ is the length of the training set, and $(h)$ is the forecast horizon. Note that the denominator of RMSSE (in-sample, one-step-ahead mean squared error of the Naive method) is computed only for the periods during which the examined product(s) are actively sold, i.e., the periods following the first non-zero demand observed for the series under evaluation. This is done since many of the products included in the dataset started being sold later than the first available date. Like MASE, RMSSE is independent of the scale of the data, has a predictable behavior, i.e., becomes infinite or undefined only when all the errors of the Naive method are equal to zero, has a defined mean and a finite variance, and is symmetric in the sense that it penalizes positive and negative forecast errors, as well as errors in large and small forecasts, equally.
After estimating RMSSE for all the 42,840 time series of the competition (average accuracy reported for each series across the complete forecasting horizon), the overall accuracy of the forecasting method is computed by averaging the RMSSE scores across all the series of the dataset using appropriate weights. The measure, to be called Weighted RMSSE (WRMSSE), is defined as follows:
$$ \text{WRMSSE} = \sum_{i=1}^{42,840} \frac{w_i \times \text{RMSSE}_i}{\sum_{i=1}^{42,840} w_i} $$
where $(w_i)$ is the weight of the $(i)$-th series. The weights are computed based on the last 28 observations of the training sample of the dataset, specifically based on the cumulative actual dollar sales that each series displayed in that particular period (sum of units sold multiplied by their respective price). Lower WRMSSE scores indicate more accurate forecasts. In other words, we expect the “best” performing forecasting methods to derive lower forecasting errors for the series that are more valuable to the company.
The performance of the top 25 teams of the M5 Accuracy competition in terms of WRMSSE. The results are presented both per aggregation level and overall. Overall percentage improvements are also reported in comparison to the top-performing benchmark (ES bu)
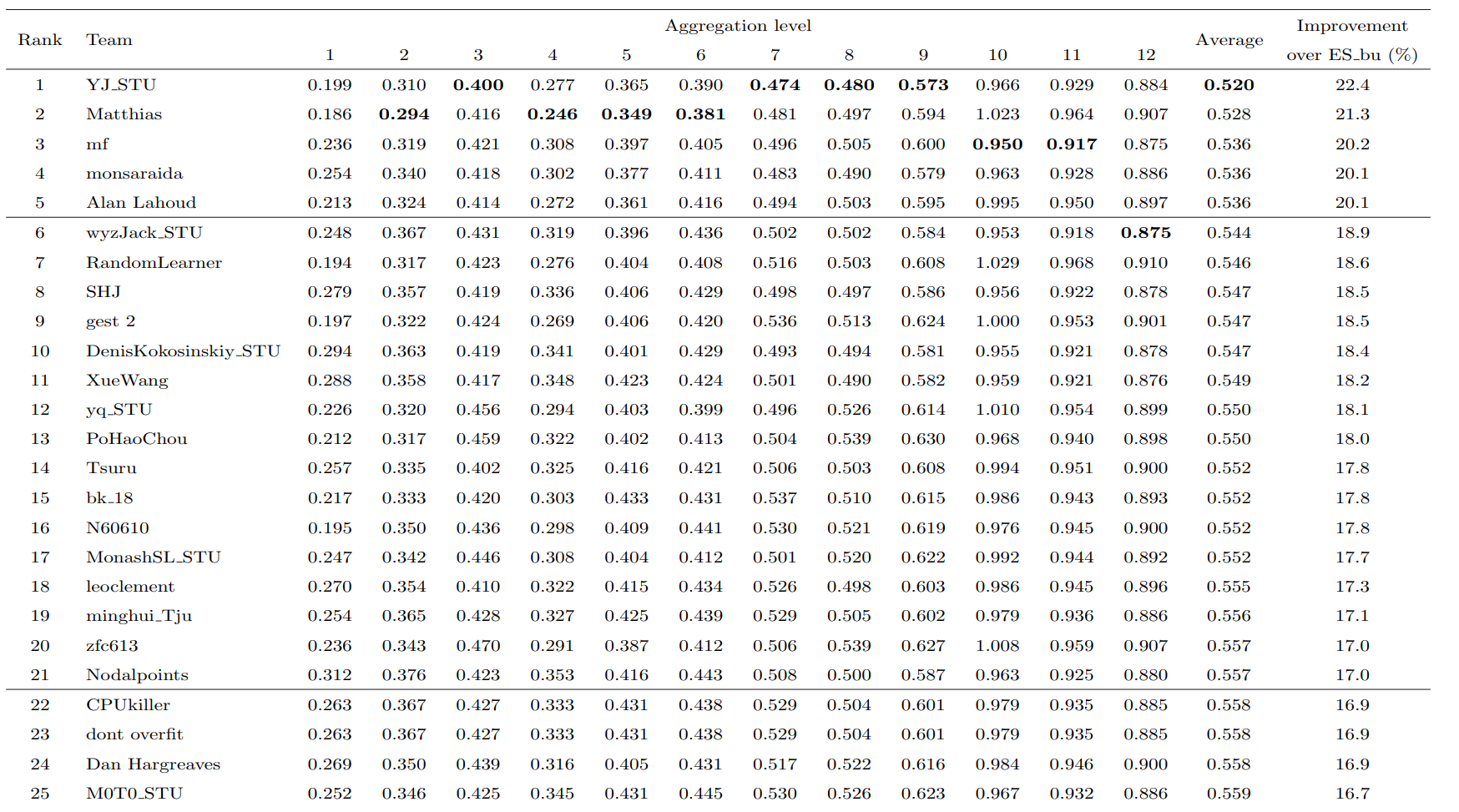
The performance of the top 25 teams
The winner of the competition, considered an equal weighted combination (arithmetic mean) of various LightGBM models that were trained to produce forecasts for the product-store series using data per store (10 models), store-category (30 models), and store-department (70 models). Two variations were considered for each type of model, the first applying a recursive and the second a non-recursive forecasting approach (Bontempi et al., 2013). The models were optimized without considering early stopping and by maximizing the negative log-likelihood of the Tweedie distribution (Zhou et al., 2020), which is considered an effective approach when dealing with data with a probability mass of zero and nonnegative, highly right-skewed distribution.
Most of the top-performing teams employed global forecasting approaches with machine learning methods like gradient boosting (e.g., LightGBM), proving the effectiveness of such approach in handling the complexity of modeling thousands of time series.
Sources:
For more details about the M5 Accuracy competition, you can refer to the following sources:
Makridakis, Spyros & Spiliotis, Evangelos & Assimakopoulos, Vassilis. (2020). The M5 Accuracy competition: Results, findings and conclusions. https://statmodeling.stat.columbia.edu/wp-content/uploads/2021/10/M5_accuracy_competition.pdf
WRMSSE and the M5 Dataset https://www.pmorgan.com.au/tutorials/wrmsse-for-the-m5-dataset/
✎ Note
This document serves as an introduction to the M5 dataset and the application of global models for forecasting thousands of time series simultaneously. To achieve metrics comparable to those of the top participants, users will need to delve deeper and apply additional efforts, such as: hyperparameters tuning, feature selection, using an ensemble of models and incorporating additional features.⚠ Warning
Modelling all the series of the M5 dataset simultaneously is computationally expensive, user will require a powerful machine with at least 100GB of RAM. When not having access to such resources, users can consider working with a subset of the data as shown in section Select a subset of the data.Libraries¶
The libraries used in this document are:
# Data processing
# ==============================================================================
import pandas as pd
import numpy as np
from skforecast.datasets import fetch_dataset
# Plots
# ==============================================================================
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.io as pio
import plotly.offline as poff
pio.templates.default = "seaborn"
poff.init_notebook_mode(connected=True)
plt.style.use('seaborn-v0_8-darkgrid')
# Modelling and Forecasting
# ==============================================================================
import sklearn
import skforecast
import lightgbm
from lightgbm import LGBMRegressor
from skforecast.recursive import ForecasterRecursiveMultiSeries
from skforecast.model_selection import TimeSeriesFold
from skforecast.model_selection import backtesting_forecaster_multiseries
from skforecast.preprocessing import RollingFeatures, reshape_series_long_to_dict, reshape_exog_long_to_dict
from feature_engine.creation import CyclicalFeatures
from m5_wrmsse import wrmsse # To calculate the metric without the need of submitting to Kaggle
# Warnings configuration
# ==============================================================================
import warnings
warnings.filterwarnings('once')
print(f"Skforecast version: {skforecast.__version__}")
print(f"Scikit-learn version: {sklearn.__version__}")
print(f"LightGBM version: {lightgbm.__version__}")
Skforecast version: 0.22.0 Scikit-learn version: 1.7.2 LightGBM version: 4.6.0
Data¶
# Download data
# ==============================================================================
data = fetch_dataset("m5")
print(f"Data shape: {data.shape}")
data.head(3)
╭─────────────────────────────────────── m5 ───────────────────────────────────────╮ │ Description: │ │ Daily sales data from the M5 competition with product metadata and calendar │ │ data. │ │ │ │ Source: │ │ Addison Howard, inversion, Spyros Makridakis, and vangelis. M5 Forecasting - │ │ Accuracy. https://kaggle.com/competitions/m5-forecasting-accuracy, 2020. Kaggle. │ │ │ │ URL: │ │ https://huggingface.co/datasets/skforecast/m5_daily/resolve/main/m5_daily.parque │ │ t │ │ │ │ Shape: 59181090 rows x 16 columns │ ╰──────────────────────────────────────────────────────────────────────────────────╯
Data shape: (59181090, 16)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | event_name_1 | event_type_1 | event_name_2 | event_type_2 | snap_CA | snap_TX | snap_WI | sell_price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | HOUSEHOLD_1_291_WI_1_evaluation | 2013-09-24 | HOUSEHOLD_1_291 | HOUSEHOLD_1 | HOUSEHOLD | WI_1 | WI | 4 | None | None | None | None | 0 | 0 | 0 | 3.76 |
| 1 | HOUSEHOLD_1_291_WI_1_evaluation | 2013-09-25 | HOUSEHOLD_1_291 | HOUSEHOLD_1 | HOUSEHOLD | WI_1 | WI | 0 | None | None | None | None | 0 | 0 | 0 | 3.76 |
| 2 | HOUSEHOLD_1_291_WI_1_evaluation | 2013-09-26 | HOUSEHOLD_1_291 | HOUSEHOLD_1 | HOUSEHOLD | WI_1 | WI | 1 | None | None | None | None | 0 | 0 | 0 | 3.76 |
Se unifican las columnas de eventos (event_name_1, event_name_2) en una única columna binaria. Se unifican también las columnas con el tipo de evento (event_type_1, event_type_2) en una única columna.
# Unificar columns
# ==============================================================================
data['is_event'] = (data['event_name_1'].notnull() | data['event_name_2'].notnull()).astype(int)
data['event_type_1_2'] = data['event_type_1'].fillna('') + data['event_type_2'].fillna('')
data['event_type_1_2'] = data['event_type_1_2'].replace('', 'no_event')
data = data.drop(columns=['event_name_1', 'event_type_1', 'event_name_2', 'event_type_2'])
print(f"Data shape: {data.shape}")
data.head(3)
Data shape: (59181090, 14)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | snap_CA | snap_TX | snap_WI | sell_price | is_event | event_type_1_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | HOUSEHOLD_1_291_WI_1_evaluation | 2013-09-24 | HOUSEHOLD_1_291 | HOUSEHOLD_1 | HOUSEHOLD | WI_1 | WI | 4 | 0 | 0 | 0 | 3.76 | 0 | no_event |
| 1 | HOUSEHOLD_1_291_WI_1_evaluation | 2013-09-25 | HOUSEHOLD_1_291 | HOUSEHOLD_1 | HOUSEHOLD | WI_1 | WI | 0 | 0 | 0 | 0 | 3.76 | 0 | no_event |
| 2 | HOUSEHOLD_1_291_WI_1_evaluation | 2013-09-26 | HOUSEHOLD_1_291 | HOUSEHOLD_1 | HOUSEHOLD | WI_1 | WI | 1 | 0 | 0 | 0 | 3.76 | 0 | no_event |
Intermittent sales¶
Some series exhibit intermittent sales, characterized by frequent zero values. This pattern can arise for various reasons. For example, a product might only be sold during specific seasons or exclusively during promotional periods. Forecasting such series can be challenging, making it essential to identify and handle them appropriately.
In this dataset, there are two distinct scenarios where sales are recorded as zero:
Sales are 0, but a selling price is available: This indicates that the product was available for purchase, but no sales occurred.
Sales are 0, and no selling price is available: This implies that the product was not available for purchase during that period.
Skforecast supports modeling time series of varying lengths. To avoid misleading the model, dates when a product was unavailable for purchase are excluded from the historical data. The following preprocessing steps are applied for each product:
Remove leading missing values in the selling price: This eliminates historical dates before the product was introduced to the market.
Remove trailing missing values in the selling price: This excludes historical dates after the product was retired from the market.
Handle intermediate missing values in selling price: For gaps within the data where the product is not available (missing selling price) but the product was previously available, a new variable,
is_available, is added with a value of0to indicate unavailability.
# Remove dates when the product was not available
# ==============================================================================
def clean_no_sales(df):
"""
Remove head and tail rows from a df where column 'sell_price' is NaN.
"""
non_missing_indices = df['sell_price'].notna()
first_non_zero = np.argmax(non_missing_indices)
last_non_zero = len(df) - np.argmax(non_missing_indices[::-1])
trimmed_df = df.iloc[first_non_zero:last_non_zero]
return trimmed_df
data = (
data
.groupby('id', observed=True)
.apply(clean_no_sales, include_groups=False)
.reset_index(drop=False)
.drop(columns='level_1')
)
data['is_available'] = data['sell_price'].notna().astype(float)
print(f"Data shape: {data.shape}")
data.head(3)
Data shape: (46882944, 15)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | snap_CA | snap_TX | snap_WI | sell_price | is_event | event_type_1_2 | is_available | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001_CA_1_evaluation | 2011-01-29 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 3 | 0 | 0 | 0 | 2.0 | 0 | no_event | 1.0 |
| 1 | FOODS_1_001_CA_1_evaluation | 2011-01-30 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | 0 | 2.0 | 0 | no_event | 1.0 |
| 2 | FOODS_1_001_CA_1_evaluation | 2011-01-31 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | 0 | 2.0 | 0 | no_event | 1.0 |
# Number of series with high, low and non intermittent sales
# ==============================================================================
pct_zero_sales = data.groupby('id', observed=True)['sales'].apply(lambda x: (x == 0).mean()).mul(100).round(2)
pct_zero_sales = pct_zero_sales.to_frame(name='pct_zero_sales').sort_values('pct_zero_sales', ascending=False)
high_intermittent = pct_zero_sales[pct_zero_sales['pct_zero_sales'] > 80].shape[0]
medium_intermittent = pct_zero_sales[(pct_zero_sales['pct_zero_sales'] >= 50) & (pct_zero_sales['pct_zero_sales'] < 80)].shape[0]
low_intermittent = pct_zero_sales[(pct_zero_sales['pct_zero_sales'] >= 5) & (pct_zero_sales['pct_zero_sales'] < 50)].shape[0]
# All series have at least few zero sales due to the festive days
non_intermittent = pct_zero_sales[pct_zero_sales['pct_zero_sales'] < 5].shape[0]
print(f"High intermittent sales: {high_intermittent}")
print(f"Medium intermittent sales: {medium_intermittent}")
print(f"Low intermittent sales: {low_intermittent}")
print(f"Non intermittent sales (<5% days): {non_intermittent}")
High intermittent sales: 7411 Medium intermittent sales: 13119 Low intermittent sales: 9692 Non intermittent sales (<5% days): 258
# Example of high, low and non intermittent series
# ==============================================================================
ids = [
"FOODS_1_090_CA_3_evaluation",
"FOODS_3_778_CA_2_evaluation",
"FOODS_3_555_CA_3_evaluation",
]
sample = data.query("id.isin(@ids)")
fig = px.line(sample, x="datetime", y="sales", facet_row="id", color="id")
fig.update_yaxes(matches=None)
fig.for_each_annotation(lambda a: a.update(text=''))
fig.update_layout(
title="Sales of some intermittent series",
xaxis_title="",
yaxis_title="sales",
width=800,
height=450,
margin=dict(l=20, r=20, t=35, b=20),
legend=dict(orientation="h", yanchor="top")
)
fig.show()
Select a subset of the data¶
# Select only the series with low or non intermittent sales
# ==============================================================================
# ids = pct_zero_sales[pct_zero_sales['pct_zero_sales'] < 50].index
# data = data[data['id'].isin(ids)].reset_index(drop=True)
# print(f"Data shape: {data.shape}")
# print(f"Number of selected series: {data['id'].nunique()}")
# data.head(3)
Feature engineering¶
In adition to the provided exogenous variables, new ones are created:
Calendar features: Day of the week, month, year, etc.
Event related features: is next day an event, was last day an event, etc.
Price features: Average price of the product in the last 7, 14, 30, 60, and 180 days.
⚠ Warning
When creating new features in a multi-series dataset, it is important to avoid avoid mixing information of different series. It is recommended to use thegroupby and apply methods to create these features.
# Calendar features
# ==============================================================================
data['month'] = data['datetime'].dt.month
data['quarter'] = data['datetime'].dt.quarter
data['week'] = data['datetime'].dt.isocalendar().week
data['day_of_week'] = data['datetime'].dt.dayofweek
data['day_of_month'] = data['datetime'].dt.day
data['day_of_year'] = data['datetime'].dt.dayofyear
data['weekend'] = data['day_of_week'].isin([5, 6]).astype(int)
print(f"Data shape: {data.shape}")
data.head(3)
Data shape: (46882944, 22)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | snap_CA | snap_TX | ... | is_event | event_type_1_2 | is_available | month | quarter | week | day_of_week | day_of_month | day_of_year | weekend | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001_CA_1_evaluation | 2011-01-29 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 3 | 0 | 0 | ... | 0 | no_event | 1.0 | 1 | 1 | 4 | 5 | 29 | 29 | 1 |
| 1 | FOODS_1_001_CA_1_evaluation | 2011-01-30 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | ... | 0 | no_event | 1.0 | 1 | 1 | 4 | 6 | 30 | 30 | 1 |
| 2 | FOODS_1_001_CA_1_evaluation | 2011-01-31 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | ... | 0 | no_event | 1.0 | 1 | 1 | 5 | 0 | 31 | 31 | 0 |
3 rows × 22 columns
# Cyclical encoding of calendar features
# ==============================================================================
features_to_encode = [
"month",
"quarter",
"week",
"day_of_week",
"day_of_month",
"day_of_year",
]
max_values = {
"month": 12,
"quarter": 4,
"week": 54,
"day_of_week": 6,
"day_of_month": 31,
"day_of_year": 365,
}
cyclical_encoder = CyclicalFeatures(
variables = features_to_encode,
max_values = max_values,
drop_original = True
)
data = cyclical_encoder.fit_transform(data)
# Cast padas types Float64 to numpy float64
# ==============================================================================
data['week_sin'] = data['week_sin'].astype(np.float64)
data['week_cos'] = data['week_cos'].astype(np.float64)
print(f"Data shape: {data.shape}")
data.head(3)
Data shape: (46882944, 28)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | snap_CA | snap_TX | ... | quarter_sin | quarter_cos | week_sin | week_cos | day_of_week_sin | day_of_week_cos | day_of_month_sin | day_of_month_cos | day_of_year_sin | day_of_year_cos | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001_CA_1_evaluation | 2011-01-29 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 3 | 0 | 0 | ... | 1.0 | 6.123234e-17 | 0.448799 | 0.893633 | -8.660254e-01 | 0.5 | -3.943559e-01 | 0.918958 | 0.478734 | 0.877960 |
| 1 | FOODS_1_001_CA_1_evaluation | 2011-01-30 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | ... | 1.0 | 6.123234e-17 | 0.448799 | 0.893633 | -2.449294e-16 | 1.0 | -2.012985e-01 | 0.979530 | 0.493776 | 0.869589 |
| 2 | FOODS_1_001_CA_1_evaluation | 2011-01-31 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | ... | 1.0 | 6.123234e-17 | 0.549509 | 0.835488 | 0.000000e+00 | 1.0 | -2.449294e-16 | 1.000000 | 0.508671 | 0.860961 |
3 rows × 28 columns
# Event features
# ==============================================================================
def create_event_features(df):
"""
Create additional features based on events. Since the frequency of the series
is daily, shift 1 is the previous and shift -1 is the next day.
"""
df['is_event_lag_1'] = df['is_event'].shift(1)
df['is_event_lag_2'] = df['is_event'].shift(2)
df['is_event_next_1'] = df['is_event'].shift(-1)
df['is_event_next_2'] = df['is_event'].shift(-2)
# Drop rows with NaNs introduced by the shift
df = df.iloc[2:-2]
return df
data = (
data
.groupby('id', observed=True)
.apply(create_event_features, include_groups=False)
.reset_index(drop=False)
.drop(columns='level_1')
)
print(f"Data shape: {data.shape}")
data.head(3)
Data shape: (46760984, 32)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | snap_CA | snap_TX | ... | day_of_week_sin | day_of_week_cos | day_of_month_sin | day_of_month_cos | day_of_year_sin | day_of_year_cos | is_event_lag_1 | is_event_lag_2 | is_event_next_1 | is_event_next_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001_CA_1_evaluation | 2011-01-31 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | ... | 0.000000 | 1.0 | -2.449294e-16 | 1.000000 | 0.508671 | 0.860961 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | FOODS_1_001_CA_1_evaluation | 2011-02-01 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 1 | 1 | 1 | ... | 0.866025 | 0.5 | 2.012985e-01 | 0.979530 | 0.523416 | 0.852078 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | FOODS_1_001_CA_1_evaluation | 2011-02-02 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 4 | 1 | 0 | ... | 0.866025 | -0.5 | 3.943559e-01 | 0.918958 | 0.538005 | 0.842942 | 0.0 | 0.0 | 0.0 | 0.0 |
3 rows × 32 columns
# Price features
# ==============================================================================
def create_price_features(df):
"""
Create additional features based on price. Price is constant at weekly level,
therefore we can use shift 7 to get the previous week.
"""
df['sell_price_lag_7'] = df['sell_price'].shift(7)
df['sell_price_lag_14'] = df['sell_price'].shift(14)
df['sell_price_lag_21'] = df['sell_price'].shift(21)
df['sell_price_mean_21'] = df['sell_price'].rolling(21, min_periods=1).mean()
df['sell_price_delta_21'] = df['sell_price'] - df['sell_price_lag_21']
# Drop rows with NaNs introduced by the shift
df = df.iloc[21:]
return df
data = (
data
.groupby('id', observed=True)
.apply(create_price_features, include_groups=False)
.reset_index(drop=False)
.drop(columns='level_1')
)
print(f"Data shape: {data.shape}")
data.head(3)
Data shape: (46120694, 37)
| id | datetime | item_id | dept_id | cat_id | store_id | state_id | sales | snap_CA | snap_TX | ... | day_of_year_cos | is_event_lag_1 | is_event_lag_2 | is_event_next_1 | is_event_next_2 | sell_price_lag_7 | sell_price_lag_14 | sell_price_lag_21 | sell_price_mean_21 | sell_price_delta_21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001_CA_1_evaluation | 2011-02-21 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 0 | 0 | 0 | ... | 0.625411 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 |
| 1 | FOODS_1_001_CA_1_evaluation | 2011-02-22 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 2 | 0 | 0 | ... | 0.611886 | 1.0 | 0.0 | 0.0 | 0.0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 |
| 2 | FOODS_1_001_CA_1_evaluation | 2011-02-23 | FOODS_1_001 | FOODS_1 | FOODS | CA_1 | CA | 2 | 0 | 0 | ... | 0.598181 | 0.0 | 1.0 | 0.0 | 0.0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 |
3 rows × 37 columns
Modelling and forecasting¶
ForecasterRecursiveMultiSeries allows modeling time series of different lengths and using different exogenous variables. When series have different lengths, the data must be transformed into a dictionary. The keys of the dictionary are the names of the series and the values are the series themselves. To do this, the series_long_to_dict function is used, which takes the DataFrame in "long format" and returns a dict of pandas Series. Similarly, when the exogenous variables are different (values or variables) for each series, the data must be transformed into a dictionary. The keys of the dictionary are the names of the series and the values are the exogenous variables themselves. The exog_long_to_dict function is used, which takes the DataFrame in "long format" and returns a dict of exogenous variables (pandas Series or pandas DataFrame).
When all series have the same length and the same exogenous variables, it is not necessary to use dictionaries. Series can be passed as unique DataFrame with each series in a column, and exogenous variables can be passed as a DataFrame with the same length as the series.
# Partitions dates: validation and test set is of 28 days each to match the Kaggle competition
# ==============================================================================
max_date = data['datetime'].max()
min_date = data['datetime'].min()
init_train = min_date
end_train = max_date - pd.DateOffset(days=28*2)
end_val = max_date - pd.DateOffset(days=28)
print(f"Training set : {init_train.date()} - {end_train.date()}")
print(f"Validation set : {(end_train + pd.DateOffset(days=1)).date()} - {end_val.date()}")
print(f"Test set : {(end_val + pd.DateOffset(days=1)).date()} - {max_date.date()}")
Training set : 2011-01-29 - 2016-03-27 Validation set : 2016-03-28 - 2016-04-24 Test set : 2016-04-25 - 2016-05-22
# Exogenous features selected for modeling
# ==============================================================================
exog_features = [
"dept_id",
"cat_id",
"store_id",
"state_id",
"snap_CA",
"snap_TX",
"snap_WI",
"sell_price",
"is_event",
"event_type_1_2",
"weekend",
"month_sin",
"month_cos",
"quarter_sin",
"quarter_cos",
"week_sin",
"week_cos",
"day_of_week_sin",
"day_of_week_cos",
"day_of_month_sin",
"day_of_month_cos",
"day_of_year_sin",
"day_of_year_cos",
"is_event_lag_1",
"is_event_lag_2",
"is_event_next_1",
"is_event_next_2",
"sell_price_lag_7",
"sell_price_lag_14",
"sell_price_lag_21",
"sell_price_mean_21",
"sell_price_delta_21",
"is_available"
]
# Transform series and exog to dictionaries
# ==============================================================================
series_dict = reshape_series_long_to_dict(
data = data.reset_index(),
series_id = 'id',
index = 'datetime',
values = 'sales',
freq = 'D'
)
exog_dict = reshape_exog_long_to_dict(
data = data[exog_features + ['id', 'datetime']].reset_index(),
series_id = 'id',
index = 'datetime',
freq = 'D'
)
exog_dict = {k: v[exog_features] for k, v in exog_dict.items()}
╭──────────────────────────────── MissingValuesWarning ────────────────────────────────╮ │ Series 'FOODS_3_150_CA_3_evaluation' is incomplete. NaNs have been introduced after │ │ setting the frequency. │ │ │ │ Category : skforecast.exceptions.MissingValuesWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/preprocessing/preprocessing.py:534 │ │ Suppress : warnings.simplefilter('ignore', category=MissingValuesWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────── MissingValuesWarning ────────────────────────────────╮ │ Series 'HOUSEHOLD_1_291_WI_1_evaluation' is incomplete. NaNs have been introduced │ │ after setting the frequency. │ │ │ │ Category : skforecast.exceptions.MissingValuesWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/preprocessing/preprocessing.py:534 │ │ Suppress : warnings.simplefilter('ignore', category=MissingValuesWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────── MissingValuesWarning ────────────────────────────────╮ │ Exogenous variables for series 'FOODS_3_150_CA_3_evaluation' are incomplete. NaNs │ │ have been introduced after setting the frequency. │ │ │ │ Category : skforecast.exceptions.MissingValuesWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/preprocessing/preprocessing.py:706 │ │ Suppress : warnings.simplefilter('ignore', category=MissingValuesWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────── MissingValuesWarning ────────────────────────────────╮ │ Exogenous variables for series 'HOUSEHOLD_1_291_WI_1_evaluation' are incomplete. │ │ NaNs have been introduced after setting the frequency. │ │ │ │ Category : skforecast.exceptions.MissingValuesWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/preprocessing/preprocessing.py:706 │ │ Suppress : warnings.simplefilter('ignore', category=MissingValuesWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
# Missing values per series
# ==============================================================================
missing_values = {k: v.isna().sum() for k, v in series_dict.items() if v.isna().sum() > 0}
missing_values
{'FOODS_3_150_CA_3_evaluation': np.int64(25),
'HOUSEHOLD_1_291_WI_1_evaluation': np.int64(25)}
Since only two series have missing values and the number of missing entries is minimal, linear interpolation is used to impute them. Although this step is unnecessary when using skforecast—since it accommodates missing values in both the series and exogenous variables—it is performed to minimize warnings and to enable the use of regressors that do not support missing values.
# Fill missing values of the target series with interpolation
# ==============================================================================
series_with_missing = ['FOODS_3_150_CA_3_evaluation', 'HOUSEHOLD_1_291_WI_1_evaluation']
for series in series_with_missing:
series_dict[series] = series_dict[series].interpolate(method='linear', limit_direction='both')
# Fill missing
# ==============================================================================
for series in series_with_missing:
exog_dict[series][['snap_CA', 'snap_TX', 'snap_WI', 'is_event', 'weekend']] = (
exog_dict[series][['snap_CA', 'snap_TX', 'snap_WI', 'is_event', 'weekend']].fillna(0)
)
# Partition data in train and test
# ==============================================================================
data = data.set_index('datetime').sort_index()
series_dict_train = {k: v.loc[v.index <= end_train,] for k, v in series_dict.items()}
series_dict_valid = {k: v.loc[(v.index > end_train) & (v.index <= end_val),] for k, v in series_dict.items()}
series_dict_test = {k: v.loc[v.index > end_val,] for k, v in series_dict.items()}
exog_dict_train = {k: v.loc[v.index <= end_train,] for k, v in exog_dict.items()}
exog_dict_valid = {k: v.loc[(v.index > end_train) & (v.index <= end_val),] for k, v in exog_dict.items()}
exog_dict_test = {k: v.loc[v.index > end_val,] for k, v in exog_dict.items()}
print(
f"Rage of dates available : {data.index.min()} --- {data.index.max()} "
f"(n={(data.index.max() - data.index.min()).days})"
)
print(
f" Dates for training : {data.index[data.index <= end_train,].min()} --- {data.index[data.index <= end_train,].max()} "
f"(n={data.index[data.index <= end_train,].nunique()})"
)
print(
f" Dates for validation : {data.index[(data.index > end_train) & (data.index <= end_val),].min()} --- {data.index[(data.index > end_train) & (data.index <= end_val),].max()} "
f"(n={data.index[(data.index > end_train) & (data.index <= end_val),].nunique()})"
)
print(
f" Dates for test : {data.index[data.index > end_val,].min()} --- {data.index[data.index > end_val,].max()} "
f"(n={data.index[data.index > end_val,].nunique()})"
)
del data
Rage of dates available : 2011-01-29 00:00:00 --- 2016-05-22 00:00:00 (n=1940) Dates for training : 2011-01-29 00:00:00 --- 2016-03-27 00:00:00 (n=1885) Dates for validation : 2016-03-28 00:00:00 --- 2016-04-24 00:00:00 (n=28) Dates for test : 2016-04-25 00:00:00 --- 2016-05-22 00:00:00 (n=28)
# Create forecaster
# ==============================================================================
categorical_features = ['dept_id', 'cat_id', 'store_id', 'state_id', 'event_type_1_2']
window_features = RollingFeatures(stats=['mean', 'min', 'max'], window_sizes=7)
forecaster = ForecasterRecursiveMultiSeries(
estimator = LGBMRegressor(random_state=8520, verbose=-1),
lags = 14,
window_features = window_features,
transformer_series = None,
categorical_features = categorical_features,
encoding = "ordinal",
dropna_from_series = True,
)
forecaster
ForecasterRecursiveMultiSeries
General Information
- Estimator: LGBMRegressor
- Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
- Window features: ['roll_mean_7', 'roll_min_7', 'roll_max_7']
- Window size: 14
- Series encoding: ordinal
- Exogenous included: False
- Categorical features: ['dept_id', 'cat_id', 'store_id', 'state_id', 'event_type_1_2']
- Weight function included: False
- Series weights: None
- Differentiation order: None
- Creation date: 2026-03-31 17:09:17
- Last fit date: None
- Skforecast version: 0.22.0
- Python version: 3.13.12
- Forecaster id: None
Exogenous Variables
-
None
Data Transformations
- Transformer for series: None
- Transformer for exog: None
Training Information
- Series names (levels): None
- Training range: None
- Training index type: Not fitted
- Training index frequency: Not fitted
Estimator Parameters
-
{'boosting_type': 'gbdt', 'class_weight': None, 'colsample_bytree': 1.0, 'importance_type': 'split', 'learning_rate': 0.1, 'max_depth': -1, 'min_child_samples': 20, 'min_child_weight': 0.001, 'min_split_gain': 0.0, 'n_estimators': 100, 'n_jobs': None, 'num_leaves': 31, 'objective': None, 'random_state': 8520, 'reg_alpha': 0.0, 'reg_lambda': 0.0, 'subsample': 1.0, 'subsample_for_bin': 200000, 'subsample_freq': 0, 'verbose': -1}
Fit Kwargs
-
{}
# Backtesting on test set
# ==============================================================================
cv = TimeSeriesFold(
initial_train_size = 1885 + 28, # training + validation
steps = 28,
refit = False
)
metrics, predictions = backtesting_forecaster_multiseries(
forecaster = forecaster,
series = series_dict,
exog = exog_dict,
cv = cv,
metric = ['mean_absolute_error', 'root_mean_squared_scaled_error'],
verbose = True,
show_progress = True,
suppress_warnings = True
)
display(predictions.head())
display(metrics)
Information of folds
--------------------
Number of observations used for initial training: 1913
Number of observations used for backtesting: 28
Number of folds: 1
Number skipped folds: 0
Number of steps per fold: 28
Number of steps to exclude between last observed data (last window) and predictions (gap): 0
Fold: 0
Training: 2011-01-29 00:00:00 -- 2016-04-24 00:00:00 (n=1913)
Validation: 2016-04-25 00:00:00 -- 2016-05-22 00:00:00 (n=28)
0%| | 0/1 [00:00<?, ?it/s]
| level | fold | pred | |
|---|---|---|---|
| 2016-04-25 | FOODS_1_001_CA_1_evaluation | 0 | 0.893275 |
| 2016-04-25 | FOODS_1_001_CA_2_evaluation | 0 | 1.475977 |
| 2016-04-25 | FOODS_1_001_CA_3_evaluation | 0 | 0.478983 |
| 2016-04-25 | FOODS_1_001_CA_4_evaluation | 0 | 0.511459 |
| 2016-04-25 | FOODS_1_001_TX_1_evaluation | 0 | 0.083816 |
| levels | mean_absolute_error | root_mean_squared_scaled_error | |
|---|---|---|---|
| 0 | FOODS_1_001_CA_1_evaluation | 0.980534 | 0.819421 |
| 1 | FOODS_1_001_CA_2_evaluation | 1.229794 | 0.573317 |
| 2 | FOODS_1_001_CA_3_evaluation | 0.936206 | 0.499403 |
| 3 | FOODS_1_001_CA_4_evaluation | 0.594402 | 0.621999 |
| 4 | FOODS_1_001_TX_1_evaluation | 0.692936 | 0.565815 |
| ... | ... | ... | ... |
| 30488 | HOUSEHOLD_2_516_WI_2_evaluation | 0.386423 | 1.581685 |
| 30489 | HOUSEHOLD_2_516_WI_3_evaluation | 0.392329 | 0.821289 |
| 30490 | average | 1.121803 | 0.844118 |
| 30491 | weighted_average | 1.121815 | 0.844119 |
| 30492 | pooling | 1.121815 | 0.719120 |
30493 rows × 3 columns
Metric WRMSSE¶
The python library m5_wrmsse allows to calculate the WRMSSE metric for the M5 dataset whitout the need of submitting the results to Kaggle. It evaluates all 30490 series, so all them must be forecasted.
# Calculate WRMSSE using the library m5_wrmsse
# ==============================================================================
# The wrmsse expect a numpy array of shape (30490, 28), this is 28 days of forecast for each of the 30490 series
df = predictions.drop(columns='fold', errors='ignore')
df = df.reset_index()
date_col = df.columns[0]
predictions_wide = df.pivot(
index='level', # The 30,490 unique series IDs
columns=date_col, # The 28 unique dates
values='pred' # The forecasted values
)
predictions_wide = predictions_wide.sort_index(axis=1)
predictions_wide.columns = [f'F{i+1}' for i in range(28)]
predictions_wide.columns.name = None
predictions_wide.index.name = 'id'
display(predictions_wide.head(3))
# Calculate WRMSSE
metric = wrmsse(predictions_wide.to_numpy())
print(f"WRMSSE: {metric}")
| F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | ... | F19 | F20 | F21 | F22 | F23 | F24 | F25 | F26 | F27 | F28 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| FOODS_1_001_CA_1_evaluation | 0.893275 | 0.743646 | 0.751386 | 0.692962 | 0.811687 | 1.025676 | 1.041086 | 0.948801 | 0.740432 | 0.719003 | ... | 0.835582 | 0.976159 | 0.974331 | 0.760403 | 0.731115 | 0.731115 | 0.731115 | 0.803697 | NaN | NaN |
| FOODS_1_001_CA_2_evaluation | 1.475977 | 1.300276 | 1.354258 | 1.428465 | 1.556432 | 2.049677 | 2.800572 | 1.587932 | 1.552270 | 1.408196 | ... | 1.509004 | 1.953617 | 1.944125 | 1.396411 | 1.260263 | 1.197239 | 1.236734 | 1.299653 | NaN | NaN |
| FOODS_1_001_CA_3_evaluation | 0.478983 | 0.639830 | 0.626090 | 0.797843 | 0.923468 | 0.886387 | 1.354693 | 0.661983 | 0.682811 | 0.697524 | ... | 0.835775 | 0.970833 | 0.969005 | 0.767146 | 0.737858 | 0.737858 | 0.737858 | 0.803889 | NaN | NaN |
3 rows × 28 columns
WRMSSE: 3.3268933023016523
Next steps¶
The pressented example is a simple approach to the M5 dataset. To achieve better results, users can consider the following steps:
Use a different loss function: Optimize the models using a different loss function.
Session information¶
import session_info
session_info.show(html=False)
----- feature_engine 1.9.4 lightgbm 4.6.0 m5_wrmsse NA matplotlib 3.10.8 numpy 2.3.5 pandas 2.3.3 plotly 6.6.0 session_info v1.0.1 skforecast 0.22.0 sklearn 1.7.2 ----- IPython 9.11.0 jupyter_client 8.8.0 jupyter_core 5.9.1 ----- Python 3.13.12 | packaged by Anaconda, Inc. | (main, Feb 24 2026, 16:13:31) [GCC 14.3.0] Linux-5.15.0-1084-aws-x86_64-with-glibc2.31 ----- Session information updated at 2026-03-31 17:36
Citation¶
How to cite this document
If you use this document or any part of it, please acknowledge the source, thank you!
The M5 Accuracy competition: the success of global forecasting models by Joaquín Amat Rodrigo and Javier Escobar Ortiz, available under Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) at https://cienciadedatos.net/documentos/py61-m5-forecasting-competition.html
How to cite skforecast
If you use skforecast for a publication, we would appreciate it if you cite the published software.
Zenodo:
Amat Rodrigo, Joaquin, & Escobar Ortiz, Javier. (2024). skforecast (v0.23.0). Zenodo. https://doi.org/10.5281/zenodo.8382788
APA:
Amat Rodrigo, J., & Escobar Ortiz, J. (2024). skforecast (Version 0.23.0) [Computer software]. https://doi.org/10.5281/zenodo.8382788
BibTeX:
@software{skforecast, author = {Amat Rodrigo, Joaquin and Escobar Ortiz, Javier}, title = {skforecast}, version = {0.23.0}, month = {07}, year = {2026}, license = {BSD-3-Clause}, url = {https://skforecast.org/}, doi = {10.5281/zenodo.8382788} }
Did you like the article? Your support is important
Your contribution will help me to continue generating free educational content. Many thanks! 😊




This work by Joaquín Amat Rodrigo and Javier Escobar Ortiz is licensed under a Attribution-NonCommercial-ShareAlike 4.0 International.
Allowed:
-
Share: copy and redistribute the material in any medium or format.
-
Adapt: remix, transform, and build upon the material.
Under the following terms:
-
Attribution: You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
-
NonCommercial: You may not use the material for commercial purposes.
-
ShareAlike: If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.