Introducción a Polars
Más sobre ciencia de datos: cienciadedatos.net
¿Qué es Polars?¶
Polars es una librería diseñada para trabajar con datos tabulares (DataFrames). Tiene como principal característica la capacidad de procesar grandes volúmenes de datos de forma rápida y eficiente, gracias a que maximiza el uso de todos los cores disponibles en un ordenador. Su mayor capacidad para procesar datos frente a otras librerías, por ejemplo Pandas, se debe a que está desarrollada en Rust, lo que le permite disponer de la paralelización de tareas desde su raíz. Además, utiliza Arrow arrays, una estructura de datos especialmente optimizada para realizar operaciones columnares. Actualmente, Polars dispone de APIs en Python y Rust.
Es una librería que ha ganando mucha popularidad a lo largo de los últimos años y puede ser buena alternativa frente a otros frameworks de procesamiento de datos en Python.
En este artículo se utiliza la API de Python y tiene como objetivo hacer una pequeña introducción a la sintaxis de Polars y algunas de sus principales funcionalidades.
Librerías¶
Estas son las librerías utilizadas en este documento (entorno Python):
# Librerías
# ======================================================================================
import polars as pl
from datetime import datetime
Datos¶
En este artículo de introducción, vamos a utilizar datos públicos del sistema nacional de salud de Inglaterra (NHS: National Health Service). El archivo de tipo csv contiene una muestra de datos de prescripciones médicas realizadas en Reino Unido (Deciembre 2014) y pueden descargarse desde el siguiente link. En este enlace se puede obtener más información sobre este dataset: link
Polars puede trabajar con distintos formatos de datos (csv, parquet, json, DBs, etc.).
# Lectura de datos (csv)
# ==============================================================================
file_url = (
"https://raw.githubusercontent.com/JoaquinAmatRodrigo/"
"Estadistica-machine-learning-python/master/data/sample_epd_201412.csv"
)
nhs_raw_df = pl.read_csv(file_url, sep=";")
print(f"Tipo de objeto: {type(nhs_raw_df)}")
print(f"Dimensiones de los datos: {nhs_raw_df.shape}")
display(nhs_raw_df.head())
- La primera cosa que podemos notar es que, la función de lectura csv, es muy similar a la syntax de Pandas
.read_csv()y que también nos permite pasar argumentos comosep, columns, skip_rows, etc(API Doc)
- El objeto devuelto es de tipo
polars.internals.dataframe.frame.DataFrame, contiene 50000 filas y 26 columnas.
- Al igual que en Pandas, los
polars.DataFrametiene atributos capaces de informarnos delshape,schema,columnsydtypes. (API Doc)
- Los
polars.DataFrametambién poseen atributos y métodos que permiten explorar y visualizar los datos de forma rápida. En el código anterior hemos llamado al método.head()que devuelve por defecto las 5 primeras líneas del DataFrame. Otros métodos para una rápida exploración son.tail()y.sample().
- Es interesante destacar que, cuando hacemos un display del DataFrame, se muestra debajo del nombre de cada columna el tipo de datos.
- A diferencia de los DataFrame de Pandas,los
polars.DataFrameno tiene un index asociado a las filas.
Para conocer más detalles sobre los distintos tipos y métodos de ingesta de datos disponibles podemos acceder directamente a su documentación.
Atributos de un DataFrame¶
En esta sección vamos a explorar algunos de los atributos que tiene un polars.DataFrame
n_chars = 50
# df.columns
# ==============================================================================
print("="*n_chars)
print("df.columns: listado de columnas de un DataFrame")
print(nhs_raw_df.columns)
print("")
# df.types
# ==============================================================================
print("="*n_chars)
print("df.types: tipos de datos de las columnas de un DataFrame")
print(nhs_raw_df.dtypes)
print(f"Tipos de datos únicos: {set(nhs_raw_df.dtypes)}")
print("")
# df.schema
# ==============================================================================
print("="*n_chars)
print("df.schema: Diccionario con las columnas y sus tipos de datos")
print(nhs_raw_df.schema)
print("")
# df.shape
# ==============================================================================
print("="*n_chars)
print("df.shape : filas x columnas de un DataFrame")
print(nhs_raw_df.shape)
print("")
# df.height
# ==============================================================================
print("="*n_chars)
print("df.height : número de filas de un DataFrame")
print(nhs_raw_df.height)
print("")
# df.width
# ==============================================================================
print("="*n_chars)
print("df.width : número de columnas de un DataFrame")
print(nhs_raw_df.width)
print("")
Cómo podemos observar, Polars ha inferido tres tipos de datos distintos para nuestro dataset:
Float64: Numeric (64-bit floating point type)
Int64: Numeric (64-bit signed integer type)
Utf8: String (UTF-8 encoded string type)
Más información sobre los tipos de datos disponibles en Polars aquí
Métricas y valores descriptivos¶
Los polars.DataFrame tienen distintos métodos capaces de generar métricas descriptivas de los datos. Entre ellos destaca .describe() que nos devuelve los principales estadísticos descriptivos de cada columna. Por defecto, las métricas numéricas como mean, std, etc no están disponibles para las columnas de tipo string.
# df.describe()
# ==============================================================================
print("df.describe(): Summary Stats")
display(nhs_raw_df.describe())
Valores Nulos¶
El método .null_count() devuelve un DataFrame con el total de valores nulos por columna. Más adelante en este artículo, también vamos a ver cómo encontrar y manipular estos valores.
# df.null_count()
# ==============================================================================
print("df.null_count(): Devuelve un DataFrame con el total de valores nulos por columna")
display(nhs_raw_df.null_count())
Polars expressions¶
Las Expressions son funciones/métodos utilizados a la hora de realizar operaciones con datos en Polars (e.g., selección, creación y manipulación de columnas, aplicación de filtros, entre otros). Tienen como entrada una serie y como salida otra serie, y són, por definición, un mapeo entre séries, lo que nos permite encadenarlas. Además, Polars es capaz de automatizar la ejecución de las expressions en paralelo siempre que sea posible (cuando se trabaja con múltiples columnas, por ejemplo) lo que hace de las Expressions algo muy potente.
Selección de columnas¶
Vamos ahora ver un ejemplo de cómo seleccionar columna(s) utilizando a Polars Expressions:
# .select(): Método utilizado para seleccionar una o más columnas
# ==============================================================================
nhs_raw_df.select(pl.col("REGIONAL_OFFICE_NAME"))
type(nhs_raw_df.select(pl.col("REGIONAL_OFFICE_NAME")))
Cómo podemos observar en este ejemplo, hemos utilizado el método .select() para seleccionar una columna específica de nuestro DataFrame ("REGIONAL_OFFICE_NAME"). Por defecto, este método nos retorna un otro DataFrame (polars.internals.dataframe.frame.DataFrame)
Para seleccionar columnas podemos pasar una lista con las columnas deseadas:
nhs_raw_df.select(
[
pl.col("REGIONAL_OFFICE_NAME"),
pl.col("REGIONAL_OFFICE_CODE"),
]
)
Para la selección de columnas, también se puede pasar un string o una lista de strings directamente al método .select() (ejemplo abajo). Sin embargo, en general, la utilización de la expression pl.col() para seleccionar columnas es más indicada ya que tiene la ventaja de permitir encadenar y paralelizar la ejecución de otras tareas.
# Selección de una única columna
# ==============================================================================
display(nhs_raw_df.select("REGIONAL_OFFICE_NAME").head())
# Selección de múltiples columnas
# ==============================================================================
display(nhs_raw_df.select(["REGIONAL_OFFICE_NAME","REGIONAL_OFFICE_CODE"]).head())
Creando una secuencia de tareas¶
En esta sección vamos a entender de manera muy sencilla cómo podemos crear una secuencia de pasos para manipular nuestros datos.
Estos serán los pasos que vamos a implementar:
Seleccionar y renombrar columnas
Crear una nueva columna
Aplicar un filtro a una determinada columna
Realizar una ordenación
# 1. Seleccionar y renombrar columnas: "REGIONAL_OFFICE_NAME", "AREA_TEAM_NAME", "BNF_DESCRIPTION", "TOTAL_QUANTITY", "NIC"
# ==============================================================================
processed_df = (
nhs_raw_df
.select(
[
pl.col("REGIONAL_OFFICE_NAME").alias("region_name"),
pl.col("AREA_TEAM_NAME").alias("area_name"),
pl.col("BNF_DESCRIPTION").alias("drug_name"),
pl.col("TOTAL_QUANTITY").alias("total_qt"),
pl.col("NIC").alias("net_ingredient_cost"),
]
)
)
processed_df.head()
Cómo podemos ver, una manera de renombrar las columnas es a través de la expresión alias() que puede ser encadenada a cada una de las columnas dentro del select().
# 2. Creación de nuevas columnas: unit_cost, execution_date
# ==============================================================================
processed_df = (
processed_df
.with_columns([
(pl.col("net_ingredient_cost")/pl.col("total_qt")).alias("unit_cost"),
(pl.lit(datetime.now().date()).alias("execution_date")),
])
)
processed_df.head()
Para crear columnas utilizamos la expresión with_columns() donde podemos crear varias columnas a la vez. pl.lit() se utiliza cuando queremos propagar una constante para todo el DataFrame. En este ejemplo hemos creado una fecha de ejecución que ha sido propagada en todo el DataFrame en la nueva columna execution_date que fue automáticamente inferida cómo tipo date por Polars.
# 3. Filtrar filas: region_name = 'LONDON' or 'SOUTH OF ENGLAND'
# ==============================================================================
processed_df = (
processed_df
.filter(
(pl.col("region_name") == "LONDON") | (pl.col("region_name") == "SOUTH OF ENGLAND")
)
)
processed_df.head()
# 4. Ordenar resultados: net_ingredient_cost desc
# ==============================================================================
processed_df = (
processed_df
.sort("net_ingredient_cost", reverse=True)
)
processed_df.head()
Para ordenar todo un DataFrame se utiliza la expresión .sort() que permite ordenar datos a partir de varias columnas de manera ascendente o descendente.
La principal ventaja de trabajar con las Polars Expressions es poder concatenarlas dentro de un solo bloque de código. Abajo, vamos a crear una función de preprocesado para ejemplificar esta secuencia de tareas:
# Función de preprocesado
# ==============================================================================
def preprocess_raw_data(raw_data):
df = (
raw_data
.select(
[
pl.col("REGIONAL_OFFICE_NAME").alias("region_name"),
pl.col("AREA_TEAM_NAME").alias("area_name"),
pl.col("BNF_DESCRIPTION").alias("drug_name"),
pl.col("TOTAL_QUANTITY").alias("total_qt"),
pl.col("NIC").alias("net_ingredient_cost"),
]
)
.with_columns([
(pl.col("net_ingredient_cost")/pl.col("total_qt")).alias("unit_cost"),
(pl.lit(datetime.now().date()).alias("execution_date")),
])
.filter(
(pl.col("region_name") == "LONDON") | (pl.col("region_name") == "SOUTH OF ENGLAND")
)
.sort("net_ingredient_cost", reverse=True)
)
return df
nhs_processed_df = preprocess_raw_data(raw_data=nhs_raw_df)
print(nhs_processed_df.shape)
display(nhs_processed_df.head())
Lazy evaluation¶
Hasta el momento, todo lo que hemos ejecutado en nuestro DataFrame (nhs_raw_df:polars.DataFrame) se ejecutó en modo Eager, es decir, de manera instantánea de acuerdo con lo que hemos definido en las celdas, tal cómo ocurriría si fuera un DataFrame de Pandas.
Sin embargo, Polars también tiene una forma Lazy para evaluar/ejecutar las instrucciones de código. Esta forma Lazy permite a Polars evaluar la sintaxis de nuestro código/expresión, optimizarla y finalmente ejecutarla dentro de su engine. Esto permite, en general, mejorar aún más el rendimiento y optimizar el uso de la memoria. En modo Lazy, Polars crea y realiza un seguimiento de nuestro código en un plan lógico donde es capaz de optimizar y reordenar cada tarea antes de ejecutarlo. Vamos ahora a explorar un poco el universo de las Lazy Evaluations.
lazy_nhs_raw_df = nhs_raw_df.lazy()
print(f"Object type: {type(lazy_nhs_raw_df)}")
print(lazy_nhs_raw_df.shape)
print(lazy_nhs_raw_df)
En primer lugar hemos creado un polars.LazyFrame a partir de nuestro polars.DataFrame inicial a través del método .lazy().
Un
LazyFramees un objeto sobre el cual Polars es capaz de crear un plan de ejecución y optimizar queries, volviendo así más eficiente el proceso de transformación y manipulación de los datos.Existen también maneras de realizar una lectura de datos en modo
Lazydirectamente, como por ejemplo:pl.scan_csv,pl.scan_parquet, etc.
Al intentar mostrar el shape de nuestro lazy dataframe se obtiene un error porque no todos los métodos disponibles para los polars.DataFrame están disponibles también para polars.LazyFrame, entre ellos el .shape()
Al llamar a nuestro polars.LazyFrame directamente, lo que nos devuelve es el plan de ejecución de datos. En este caso, no está haciendo nada en especial ya que solamente estamos cargando los datos. Pero es importante entender que, a medida que vamos trabajando con este DataFrame, el plan de ejecución también va cambiando y cuando necesitemos ejecutarlo, Polars es capaz de optimizarlo y paralelizar la ejecución de las tareas siempre que sea posible.
Vamos ahora llamar a la misma función de preprocesado pero utilizando nuestro polars.LazyFrame:
lazy_nhs_processed_df = preprocess_raw_data(raw_data=lazy_nhs_raw_df)
lazy_nhs_processed_df
lazy_nhs_processed_df.show_graph(optimized=True)
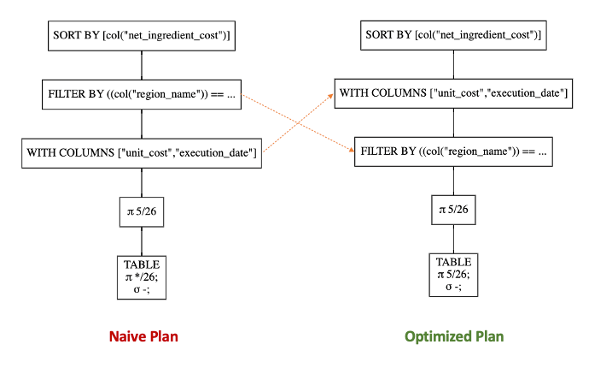
Nuestra función se ha ejecutado sin problemas y nos ha devuelto un otro objeto LazyFrame. Al intentar visualizar este objeto, cómo ya sabemos, nos salta su plan de ejecución no optimizado (NAIVE QUERY PLAN). Podemos visualizar los planes de ejecución (NAIVE QUERY PLAN/OPTIMIZED QUERY PLAN) de nuestro DataFrame a través del método: lazy_nhs_processed_df.show_graph(optimized_graph:bool)
Si comparamos el plan optimizado con el naive podemos notar que la optimizador de queries de Polars ha sido capaz de cambiar el orden de las transformaciones, poniendo la operación de filtrado de la columna "region_name" (FILTER BY) antes de la creación de las nuevas columnas (WITH COLUMNS).
Nota: Para poder visualizar los planos de ejecución puede ser necesario tener instalado graphviz en el sistema (link).
collect() y fetch()¶
Si en algún momento de nuestro +pipeline+ necesitamos realmente visualizar el pl.LazyDataFrame con sus datos, podemos utilizar métodos como collect() y fetch() que nos van a retornar un pl.DataFrame. El método fetch() es muy indicado para hacer debugging ya que es una operación rápida y que limita el número final de filas devueltas.
# .fetch(): devuelve un número limitado de líneas para hacer debugging
# ==============================================================================
print(type(lazy_nhs_processed_df.fetch(20)))
lazy_nhs_processed_df.fetch(20)
# .collect(): devuelve todo el DataFrame
# ==============================================================================
print(type(lazy_nhs_processed_df.collect()))
lazy_nhs_processed_df.collect()
Agrupación de Datos - GroupBy¶
En esta sección, vamos a explorar un ejemplo sencillo de cómo hacer un GroupBy en Polars. Básicamente, vamos a agrupar nuestros datos preprocesados a nivel del "region_name" y calcular la cantidad total de prescripciones médicas y la media de unidades solicitadas (total_sales y avg_qt).
# Group by Operation
# ==============================================================================
agg_df = (
lazy_nhs_processed_df
.groupby(["region_name"])
.agg(
[
pl.col("net_ingredient_cost").sum().alias("total_sales"),
pl.col("total_qt").mean().alias("avg_qt"),
]
)
.sort("total_sales", reverse=True)
).collect()
agg_df
En este ejemplo hemos utilizado las funciones .sum() y .mean() para agrupar los datos. En este enlace se puede obtener más información sobre otras funciones disponibles: link
Conclusiones¶
En conclusión, como hemos visto en este artículo de introducción, Polars es una librería capaz de procesar datos tabulares de forma rápida y eficiente, a través de sus características avanzadas como la capacidad de paralelizar tareas y su modo de Lazy Evaluation. También por tener una API amigable, una syntax muy intuitiva y una robusta documentación, se convierte en una excelente opción para procesar datos en Python.
Información de sesión¶
import session_info
session_info.show(html=False)
Bibliografía¶
Polars User Guide: https://pola-rs.github.io/polars-book/user-guide/introduction.html
Polars API Reference: https://pola-rs.github.io/polars/py-polars/html/reference/
¿Cómo citar este documento?
Introducción a Polars by Roberto Kramer Pinto, available under a CC BY-NC-SA 4.0 at https://www.cienciadedatos.net/documentos/pyml01-intro_polars_es.html ![]()
¿Te ha gustado el artículo? Tu ayuda es importante
Mantener un sitio web tiene unos costes elevados, tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊

This work by Roberto Kramer Pinto is licensed under a Creative Commons Attribution 4.0 International License.