Más sobre ciencia de datos: cienciadedatos.net
- Regresión lineal con Python
- Regularización Ridge, Lasso y Elastic Net con Python
- Machine learning con Python y Scikit-learn
- Random Forest con Python
- Gradient Boosting con Python
Introducción¶
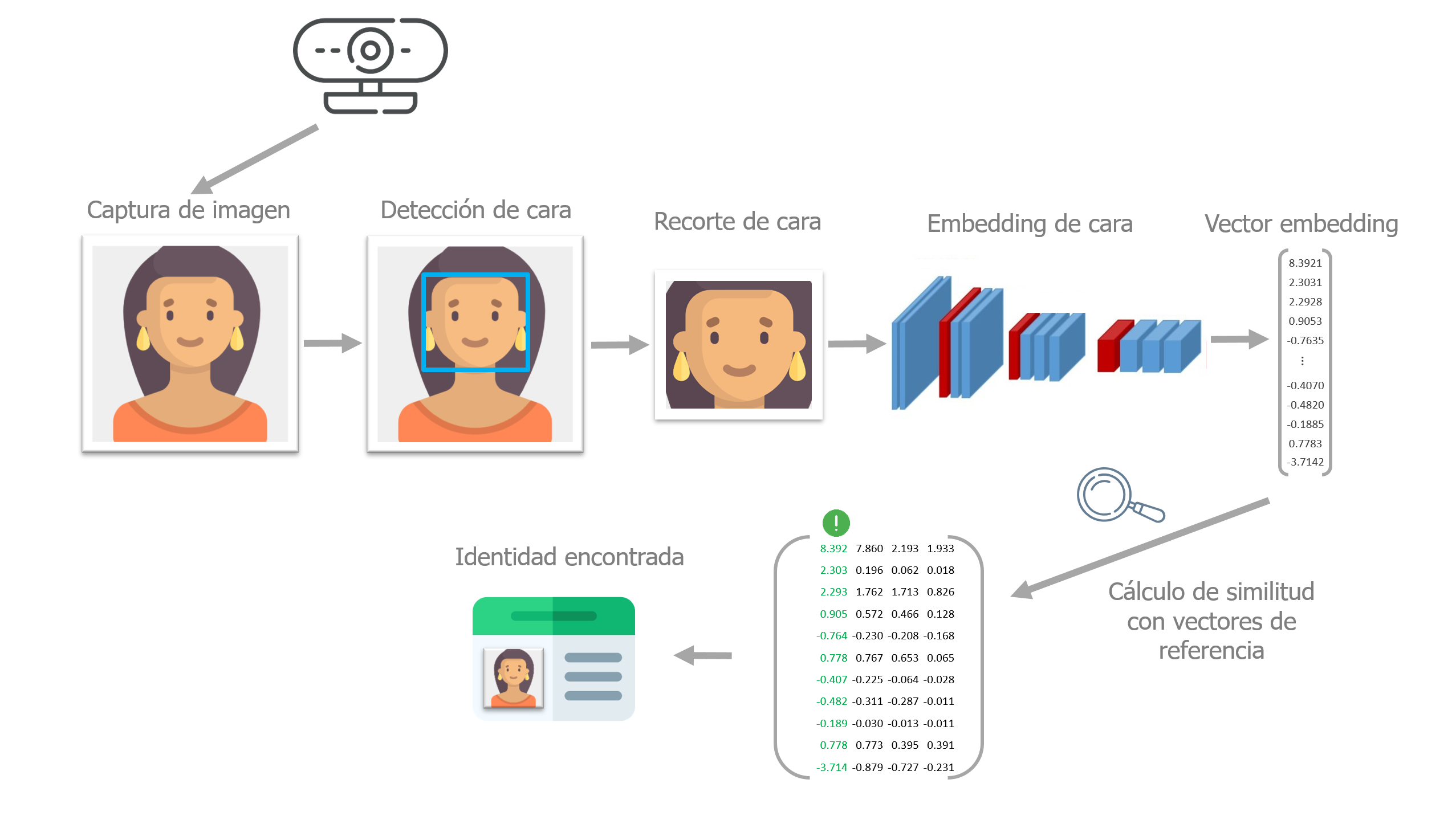
Los modelos de deep learning se han convertido en el estándar de referencia en muchos campos, siendo uno de ellos la visión por computación, también conocida como visión artificial. Una aplicación en plena expansión de esta tecnología es el reconocimiento facial, es decir, la identificación automatizada de personas que aparecen en una imagen o vídeo.
De forma similar a como lo hacemos los humanos, para que un sistema informático sea capaz de identificar a las personas que aparecen en una imagen, se requieren varias etapas:
Detectar los rostros en la imagen.
Utilizar una red neuronal capaz de mapear las características de un rostro humano en una representación numérica. Este paso se conoce como embedding o encoding.
Medir la similitud entre la representación numérica de los rostros detectados y las representaciones de referencia disponibles en una base de datos.
Determinar si son lo suficientemente similares como para ser considerados la misma persona y asignar la identidad correspondiente.
A lo largo de este documento, cada uno de estos pasos se describe y aplica utilizando OpenFaceKit, un paquete de Python desarrollado por el autor de este documento que proporciona herramientas para la detección y el reconocimiento facial utilizando deep learning.
Librerías y datos¶
# Manipulación de archivos y datos
# ==============================================================================
import os
import urllib
import zipfile
import numpy as np
from urllib.request import urlretrieve
# Procesamiento de imágenes
# ==============================================================================
from PIL import Image
import cv2
import matplotlib.pyplot as plt
# Modelos de Deep Learning y reconocimiento facial
# ==============================================================================
import torch
from scipy.spatial.distance import euclidean
from openfacekit import (
FaceRecognizer,
convert_to_matplotlib_rgb,
ReferenceEmbeddings,
)
Para los ejemplos de este documento, se utilizan imágenes de los actores de la magnífica serie Modern Family. Como primer paso, se descargan las imágenes en una carpeta local. Esto se puede hacer fácilmente en Python utilizando la función urlretrieve de la librería urllib.
# Descarga de imágenes de ejemplo
# ==============================================================================
if not os.path.exists('images'):
os.makedirs('images')
# Imagen con un solo rostro
url = ('https://github.com/JoaquinAmatRodrigo/Estadistica-machine-learning-python/' +
'raw/master/images/phil_dunphy.jpg')
urlretrieve(url=url, filename='images/image_1.jpg')
# Imagen con múltiples rostros
url = ('https://github.com/JoaquinAmatRodrigo/Estadistica-machine-learning-python/'
'raw/master/images/modernfamily.jpg')
urlretrieve(url=url, filename='images/image_2.png');
Existen múltiples librerías en Python que permiten el procesamiento de imágenes (lectura, escritura, redimensionado, recorte, etc.). Tres de las más utilizadas son OpenCV (cv2), PIL y matplotlib. Es importante tener en cuenta que OpenCV utiliza el formato de color BGR, mientras que PIL y matplotlib utilizan RGB. Afortunadamente, es sencillo cambiar entre estos formatos utilizando las funciones cv2.cvtColor(image, cv2.COLOR_BGR2RGB) y cv2.cvtColor(image, cv2.COLOR_RGB2BGR).
# Lectura de imágenes
# ==============================================================================
image_1 = Image.open('./images/image_1.jpg')
image_2 = Image.open('./images/image_2.png')
# image_1 = cv2.imread('images/image_1.jpg')
# image_2 = cv2.imread('images/image_2.png')
# Mostrado de imágenes
# ==============================================================================
plt.figure(figsize=(4, 3))
plt.imshow(image_1)
plt.axis('off')
plt.figure(figsize=(8, 5))
plt.imshow(image_2)
plt.axis('off');


Detección de caras¶
El primer paso en el proceso de reconocimiento facial es detectar dónde se encuentran las caras dentro de una imagen. Desde las primeras investigaciones en este campo, se han desarrollado múltiples estrategias y métodos de detección, siendo dos de los más destacados:
MultiTask Cascaded Convolutional Neural Network (MTCNN): Este detector combina tres modelos de redes neuronales que refinan las detecciones de forma secuencial. Existen varias implementaciones de detectores MTCNN para Python. Una de las más eficientes utiliza PyTorch y es accesible a través de la librería facenet-pytorch.
YuNet: un detector de caras basado en Convolutional Neural Network (CNN) desarrollado por Shiqi Yu en 2018 y de código abierto en 2019. Está optimizado para aplicaciones en tiempo real y se incluye en OpenCV desde la versión 4.5.1.
DeepFaceRecognition incluye implementaciones de ambos detectores, lo que permite a los usuarios elegir el que mejor se adapte a sus necesidades. from deep_face_recognition import FaceDetector
✏️ Note
Para utilizar el detector YuNet, primero es necesario descargar los pesos. Estos se pueden obtener del repositorio opencv/face_detection_yunet en Hugging Face. El archivo a descargar se llama `face_detection_yunet_2023mar.onnx`. Una vez descargado, debe colocarse en una carpeta local y su ruta debe proporcionarse al inicializar el FaceRecognizer utilizando el argumento opencv_yunet_model_path.
Los usuarios también pueden descargar los pesos automáticamente utilizando la función download_opencv_yunet_model() de la librería openfacekit.
# Inicialización del detector
# ==============================================================================
face_detector = FaceRecognizer(
detector = "MTCNN", #"OpenCV_Yunet",
encoder = None,
min_face_size = 20,
thresholds = [0.6, 0.7, 0.7],
min_confidence_detector = 0.5,
similarity_threshold = 0.5,
similarity_metric = "cosine",
keep_all = True,
verbose = True
)
face_detector
-------------- FaceRecognizer -------------- Detector type: MTCNN Encoder type: InceptionResnetV1 Device: cpu Number of reference identities: 0 Similarity metric: cosine Similarity threshold: 0.5 Minimum confidence detector: 0.5
Bounding boxes¶
El método detect_bboxes de la clase FaceDetector se utiliza para detectar las cajas delimitadoras (bounding boxes) de las caras presentes en una imagen. Este método devuelve las coordenadas de las cajas delimitadoras y sus probabilidades asociadas.
# Detección de bounding boxes
# ==============================================================================
boxes, probs = face_detector.detect_bboxes(
image = image_2,
fix_bbox = True
)
boxes
---------------- Scanned image ---------------- Detected faces: 12 Detected faces with minimum confidence: 12 Bounding box correction applied: True Bounding box coordinates: [[293, 64, 402, 194], [505, 89, 605, 224], [108, 95, 210, 227], [427, 207, 529, 333], [47, 235, 145, 361], [1069, 134, 1165, 262], [682, 126, 778, 248], [659, 291, 750, 402], [886, 128, 968, 250], [239, 245, 326, 355], [931, 496, 1012, 613], [816, 663, 889, 751]] Bounding box confidence: [0.9999438524246216, 0.9982789754867554, 0.999267041683197, 0.9998809099197388, 0.9999357461929321, 0.9999068975448608, 0.9999818801879883, 0.9996474981307983, 0.9995021820068359, 0.9993504881858826, 0.9991905093193054, 0.9989155530929565]
array([[ 293, 64, 402, 194],
[ 505, 89, 605, 224],
[ 108, 95, 210, 227],
[ 427, 207, 529, 333],
[ 47, 235, 145, 361],
[1069, 134, 1165, 262],
[ 682, 126, 778, 248],
[ 659, 291, 750, 402],
[ 886, 128, 968, 250],
[ 239, 245, 326, 355],
[ 931, 496, 1012, 613],
[ 816, 663, 889, 751]])
Para detectar y mostrar las cajas delimitadoras en una imagen, se puede utilizar el método detect_faces de la clase FaceDetector. Este método no solo detecta las cajas delimitadoras, sino que también dibuja rectángulos alrededor de las caras detectadas en la imagen y muestra las probabilidades de detección.
# Representación de las bounding boxes detectadas sobre la imagen
# ==============================================================================
face_detector.detect_faces(
image = image_2,
fix_bbox = True
)
---------------- Scanned image ---------------- Detected faces: 12 Detected faces with minimum confidence: 12 Bounding box correction applied: True Bounding box coordinates: [[293, 64, 402, 194], [505, 89, 605, 224], [108, 95, 210, 227], [427, 207, 529, 333], [47, 235, 145, 361], [1069, 134, 1165, 262], [682, 126, 778, 248], [659, 291, 750, 402], [886, 128, 968, 250], [239, 245, 326, 355], [931, 496, 1012, 613], [816, 663, 889, 751]] Bounding box confidence: [0.9999438524246216, 0.9982789754867554, 0.999267041683197, 0.9998809099197388, 0.9999357461929321, 0.9999068975448608, 0.9999818801879883, 0.9996474981307983, 0.9995021820068359, 0.9993504881858826, 0.9991905093193054, 0.9989155530929565]

Extracción de caras detectadas¶
El método extract_faces de la clase FaceDetector se utiliza para extraer las porciones de la imagen que contienen caras. El objeto devuelto es un tensor con los valores de píxeles de las caras recortadas (3 canales de color x image_size x image_size). Si se detecta más de una cara, entonces se devuelve un tensor de dimensiones (número de caras x 3 canales de color x image_size x image_size).
# Extracción de caras detectadas
# ==============================================================================
faces, probs = face_detector.extract_faces(image=image_2)
print(f"Shape: {faces.shape}")
Shape: torch.Size([12, 3, 160, 160])
Las caras extraídas se pueden visualizar utilizando la librería matplotlib. Dado que la imagen devuelta por el detector es un tensor con dimensiones [3, 160, 160], es necesario mover los canales de color a la última posición [160, 160, 3].
# Plot extracted faces with matplotlib
# ==============================================================================
fig, axs = plt.subplots(nrows=2, ncols=int(np.ceil(len(faces)/2)), figsize=(8, 4))
axs = axs.flatten()
for i in range(faces.shape[0]):
face = convert_to_matplotlib_rgb(faces[i])
# add a title with the probability
axs[i].set_title(f'Prob: {probs[i]:.4f}')
axs[i].imshow(face)
axs[i].axis('off')
fig.tight_layout()
print(faces[0])
tensor([[[ 0.9414, 0.9336, 0.9336, ..., 0.9102, 0.9258, 0.9570],
[ 0.9492, 0.9414, 0.9414, ..., 0.9180, 0.9180, 0.9258],
[ 0.9570, 0.9570, 0.9570, ..., 0.9492, 0.9258, 0.9023],
...,
[-0.2617, -0.2227, -0.1914, ..., -0.2305, -0.2539, -0.2852],
[-0.2539, -0.2148, -0.1914, ..., -0.1914, -0.2148, -0.2539],
[-0.2695, -0.2383, -0.2227, ..., -0.1602, -0.1758, -0.1992]],
[[ 0.9727, 0.9648, 0.9648, ..., 0.9102, 0.9258, 0.9570],
[ 0.9805, 0.9727, 0.9648, ..., 0.9180, 0.9180, 0.9258],
[ 0.9883, 0.9805, 0.9727, ..., 0.9336, 0.9180, 0.9023],
...,
[-0.4023, -0.3633, -0.3398, ..., -0.5117, -0.5273, -0.5586],
[-0.4023, -0.3633, -0.3477, ..., -0.4961, -0.5273, -0.5664],
[-0.4180, -0.3945, -0.3867, ..., -0.4883, -0.5039, -0.5273]],
[[ 0.9961, 0.9883, 0.9883, ..., 0.8867, 0.9180, 0.9570],
[ 0.9961, 0.9961, 0.9961, ..., 0.8945, 0.9102, 0.9258],
[ 0.9961, 0.9961, 0.9961, ..., 0.9102, 0.9102, 0.9023],
...,
[-0.5273, -0.4961, -0.4727, ..., -0.6445, -0.6602, -0.6914],
[-0.5195, -0.4961, -0.4805, ..., -0.6289, -0.6602, -0.6992],
[-0.5508, -0.5273, -0.5195, ..., -0.6211, -0.6289, -0.6523]]])

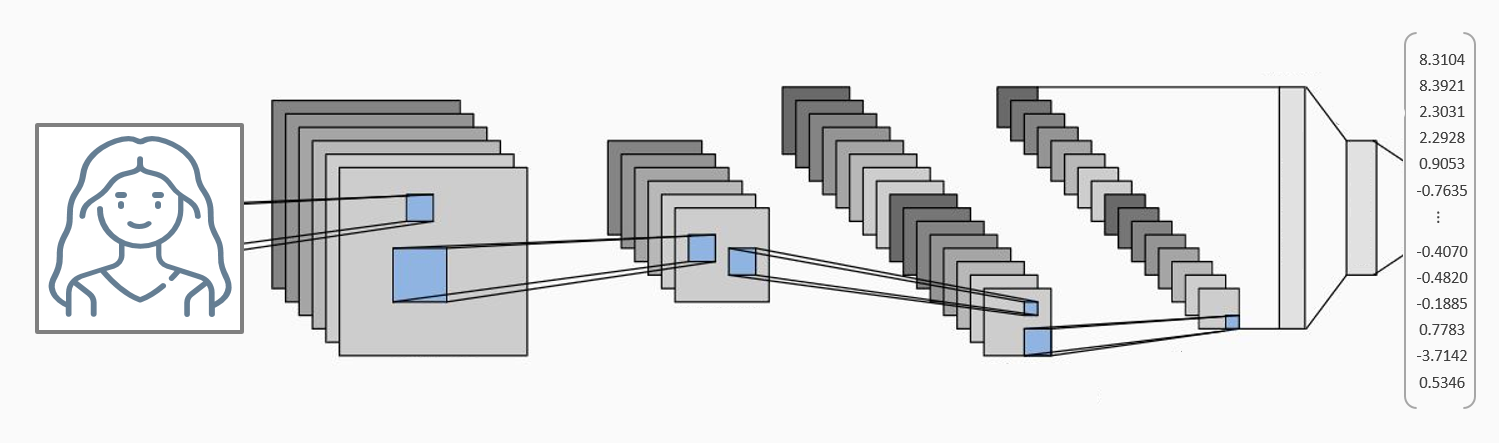
Embedding de caras¶
Una vez que se han identificado las caras en la imagen, el siguiente paso es obtener una transformación numérica que represente las características únicas de cada rostro. El vector numérico resultante se conoce como embedding o encoding.
Los modelos de deep learning (redes neuronales convolucionales) capaces de generar embeddings faciales no son fáciles de entrenar. Afortunadamente, existen varios modelos preentrenados disponibles en Python. Dos de los más comunes son:
face_recognition_model_v1 de la biblioteca dlib. Este modelo genera un embedding de 128 dimensiones.
InceptionResnetV1 de la biblioteca facenet-pytorch. Este modelo genera un embedding de 512 dimensiones.
Para construir este tipo de modelo, primero se entrena una red de clasificación en un conjunto de datos que contiene muchas personas. Una vez entrenada la red, se elimina la capa final softmax para que la salida del modelo sea un vector numérico.
En este documento, el modelo utilizado es InceptionResnetV1, específicamente la versión entrenada en el conjunto de datos VGGFace2. Para más detalles sobre este tipo de modelo, consulte el artículo de VGGFace2.
# Embeding de caras
# ==============================================================================
embeddings = face_detector.calculate_embeddings(face_images=faces)
print(f"Shape: {embeddings.shape}")
embeddings
Shape: torch.Size([12, 512])
tensor([[ 7.3119e-02, 1.3807e-02, -2.0866e-02, ..., -5.1862e-02,
5.5240e-02, 4.7610e-03],
[-6.3946e-02, -1.7960e-02, -3.9687e-02, ..., 6.9325e-02,
-9.6542e-02, -9.4992e-02],
[ 3.1438e-02, 6.8282e-02, -6.3409e-03, ..., -9.6854e-05,
3.9739e-02, -1.2795e-02],
...,
[ 4.7704e-02, -1.6753e-02, 3.7802e-02, ..., -2.9759e-02,
-3.5267e-02, -1.2076e-02],
[ 4.3862e-02, -7.2438e-03, 2.1455e-02, ..., -1.0147e-02,
1.3584e-02, 4.7367e-03],
[-4.3593e-03, -2.1744e-02, 3.1877e-02, ..., -6.5899e-02,
2.2239e-02, 1.8709e-02]])
Medición de la similitud facial con embeddings¶
El objetivo de obtener una representación numérica de las caras (embeddings) es cuantificar qué tan similares son entre sí. Dos formas comunes de calcular esta similitud son utilizando la distancia euclidiana o la distancia coseno entre los embeddings. Cuanto menor sea la distancia, mayor será la similitud entre las caras.
$$ \text{similarity} = 1 - \text{distance} $$A continuación se muestra un ejemplo donde se compara una imagen con otras dos: la primera pertenece a la misma persona, Phil Dunphy, y la segunda a Cameron Tucker.
# Extracción de caras individuales para comparación
# ==============================================================================
phil_1 = face_detector.extract_faces(image=image_1)[0][0]
phil_2 = face_detector.extract_faces(image=image_2)[0][1]
cameron = face_detector.extract_faces(image=image_2)[0][2]
# Mostrado de las caras individuales
# ==============================================================================
fig, axs = plt.subplots(nrows=1, ncols=3, figsize=(8, 5))
face = convert_to_matplotlib_rgb(phil_1)
axs[0].imshow(face)
axs[0].set_title('Phil 1')
axs[0].axis('off')
face = convert_to_matplotlib_rgb(phil_2)
axs[1].imshow(face)
axs[1].set_title('Phil 2')
axs[1].axis('off')
face = convert_to_matplotlib_rgb(cameron)
axs[2].imshow(face)
axs[2].set_title('Cameron')
axs[2].axis('off');

Una vez que se extraen las 3 caras de las imágenes, se crean sus embeddings y se calculan las similitudes entre ellas utilizando la distancia euclidiana.
# Embeddings
# ==============================================================================
embedding_phil_1 = face_detector.calculate_embeddings(face_images=phil_1.reshape((1, 3, 160, 160))).flatten()
embedding_phil_2 = face_detector.calculate_embeddings(face_images=phil_2.reshape((1, 3, 160, 160))).flatten()
embedding_cameron = face_detector.calculate_embeddings(face_images=cameron.reshape((1, 3, 160, 160))).flatten()
# Similitud entre las caras
# ==============================================================================
print(f"Similitud entre la misma imagen de Phil: {1 - euclidean(embedding_phil_1, embedding_phil_1)}")
print(f"Similitud entre dos imágenes distintas de Phil: {1 - euclidean(embedding_phil_1, embedding_phil_2)}")
print(f"Similitud entre Phil y Cameron: {1 - euclidean(embedding_phil_1, embedding_cameron)}")
Similitud entre la misma imagen de Phil: 1.0 Similitud entre dos imágenes distintas de Phil: 0.40968143939971924 Similitud entre Phil y Cameron: -0.3885413408279419
Se observa que la similitud entre las dos imágenes de Phil es significativamente mayor que la similitud entre Phil y Cameron, lo que indica que los embeddings capturan efectivamente las características faciales que diferencian a las personas.
Base de datos de embeddings de referencia¶
Para identificar a quién pertenece una cara, es necesario compararla con una base de datos que contenga un embedding de referencia para cada identidad.
La cara recién detectada se compara con todos los embeddings de referencia en la base de datos. Si la similitud entre el nuevo embedding y alguno de los embeddings de referencia está por encima de un cierto umbral, se asigna la identidad asociada a ese embedding de referencia a la cara detectada. Si ninguna similitud supera el umbral, la cara se clasifica como "desconocida".
OpenFaceKit proporciona la clase ReferenceEmbeddings para facilitar la gestión de una colección de embeddings de referencia. Dada una ruta a una carpeta con imágenes de personas conocidas, esta clase puede crear y almacenar automáticamente los embeddings de referencia para cada identidad.
La imagen o imágenes de cada persona se asumen que están ubicadas en una subcarpeta nombrada con la identidad de esa persona. Para este ejemplo, se utiliza una estructura de carpetas como la siguiente:
./images/reference_images
├── AlexDunphy
│ ├── 5e8f3e2373d0c84a052dc5e2.jpg
│ ├── AlexDunphy.png
│ └── alex-black-floral-ruffle-blouse.jpg
├── CameronTucker
│ ├── CameronTucker.png
│ └── descarga.jpg
├── ClaireDunphy
│ ├── ClaireDunphy.png
│ ├── descarga (1).jpg
│ └── frantic-claire-modern-family-s11e17.jpg
├── GloriaPritchett
│ ├── 46623-1532336916.jpg
│ ├── GloriaPritchett.png
│ └── descarga.jpg
├── HaleyDunphy
│ ├── HaleyDunphy.png
│ ├── descarga (1).jpg
│ ├── descarga.jpg
│ └── sarah-hyland-modern-family-1557405158.jpg
├── JayPritchett
│ ├── JayPritchett.png
│ └── descarga (2).jpg
├── JoePritchett
│ ├── JoePritchett.png
│ ├── Joe_Pritchett.jpg
│ ├── descarga.jpg
│ ├── images (1).jpg
│ └── images.jpg
├── LilyTucker-Pritchett
│ ├── LilyTucker-Pritchett.png
│ ├── descarga (1).jpg
│ ├── descarga (2).jpg
│ └── descarga.jpg
├── LukeDunphy
│ ├── LukeDunphy.png
│ ├── descarga (1).jpg
│ ├── descarga (3).jpg
│ └── descarga.jpg
├── MannyDelgado
│ ├── 58.jpg
│ ├── Manny-S11.jpg
│ ├── MannyDelgado.png
│ ├── descarga (2).jpg
│ ├── fca262d92ce831635d991deeb61fed1b.png
│ └── modern_family_manny_delgado_1_201215_glv63ple3v.jpeg
├── MitchellPritchett
│ ├── Jesse_Tyler_Fergeuson_Muppets_Most_Wanted_Premiere_(cropped).jpg
│ ├── MitchellPritchett.png
│ └── descarga.jpg
└── PhilDunphy
├── 1503333585_649717_1503333744_noticia_normal.jpg
├── 186708-4.jpg
├── Phil-S11.jpg
└── PhilDunphy.png# Descarga de imágenes de referencia para la base de datos de embeddings
# ==============================================================================
url = (
"https://github.com/JoaquinAmatRodrigo/Estadistica-machine-learning-python/"
"raw/master/images/imagenes_referencia_reconocimiento_facial.zip"
)
extract_dir = "./images/reference_images"
os.makedirs(extract_dir, exist_ok=True)
zip_path, _ = urllib.request.urlretrieve(url)
with zipfile.ZipFile(zip_path, "r") as f:
f.extractall(extract_dir)
print("Imágenes descargadas y extraídas con éxito en:", extract_dir)
Imágenes descargadas y extraídas con éxito en: ./images/reference_images
# Crear embeddings de referencia a partir de una carpeta de imágenes
# ==============================================================================
reference_embeddings = ReferenceEmbeddings(
folder_path='./images/reference_images'
)
reference_embeddings.calculate_reference_embeddings()
reference_embeddings
Processing identity: JayPritchett Reading image: ./images/reference_images/JayPritchett/descarga (2).jpg Reading image: ./images/reference_images/JayPritchett/JayPritchett.png Processing identity: AlexDunphy Reading image: ./images/reference_images/AlexDunphy/5e8f3e2373d0c84a052dc5e2.jpg Reading image: ./images/reference_images/AlexDunphy/alex-black-floral-ruffle-blouse.jpg Reading image: ./images/reference_images/AlexDunphy/AlexDunphy.png Processing identity: CameronTucker Reading image: ./images/reference_images/CameronTucker/descarga.jpg Reading image: ./images/reference_images/CameronTucker/CameronTucker.png Processing identity: JoePritchett Reading image: ./images/reference_images/JoePritchett/images (1).jpg Reading image: ./images/reference_images/JoePritchett/images.jpg Reading image: ./images/reference_images/JoePritchett/Joe_Pritchett.jpg Reading image: ./images/reference_images/JoePritchett/descarga.jpg Reading image: ./images/reference_images/JoePritchett/JoePritchett.png Processing identity: MitchellPritchett Reading image: ./images/reference_images/MitchellPritchett/Jesse_Tyler_Fergeuson_Muppets_Most_Wanted_Premiere_(cropped).jpg Reading image: ./images/reference_images/MitchellPritchett/descarga.jpg Reading image: ./images/reference_images/MitchellPritchett/MitchellPritchett.png Processing identity: HaleyDunphy Reading image: ./images/reference_images/HaleyDunphy/sarah-hyland-modern-family-1557405158.jpg More than 2 faces detected in image, The face with the highest confidence will be used: ./images/reference_images/HaleyDunphy/sarah-hyland-modern-family-1557405158.jpg Reading image: ./images/reference_images/HaleyDunphy/descarga (1).jpg Reading image: ./images/reference_images/HaleyDunphy/descarga.jpg Reading image: ./images/reference_images/HaleyDunphy/HaleyDunphy.png Processing identity: PhilDunphy Reading image: ./images/reference_images/PhilDunphy/186708-4.jpg Reading image: ./images/reference_images/PhilDunphy/Phil-S11.jpg Reading image: ./images/reference_images/PhilDunphy/1503333585_649717_1503333744_noticia_normal.jpg Reading image: ./images/reference_images/PhilDunphy/PhilDunphy.png Processing identity: JoaquinAmat Reading image: ./images/reference_images/JoaquinAmat/joaquin_amat.jpg Processing identity: MannyDelgado Reading image: ./images/reference_images/MannyDelgado/Manny-S11.jpg Reading image: ./images/reference_images/MannyDelgado/descarga (2).jpg Reading image: ./images/reference_images/MannyDelgado/58.jpg Reading image: ./images/reference_images/MannyDelgado/modern_family_manny_delgado_1_201215_glv63ple3v.jpeg Reading image: ./images/reference_images/MannyDelgado/fca262d92ce831635d991deeb61fed1b.png Reading image: ./images/reference_images/MannyDelgado/MannyDelgado.png Processing identity: LilyTucker-Pritchett Reading image: ./images/reference_images/LilyTucker-Pritchett/descarga (1).jpg More than 2 faces detected in image, The face with the highest confidence will be used: ./images/reference_images/LilyTucker-Pritchett/descarga (1).jpg Reading image: ./images/reference_images/LilyTucker-Pritchett/descarga (2).jpg Reading image: ./images/reference_images/LilyTucker-Pritchett/descarga.jpg Reading image: ./images/reference_images/LilyTucker-Pritchett/LilyTucker-Pritchett.png Processing identity: ClaireDunphy Reading image: ./images/reference_images/ClaireDunphy/descarga (1).jpg Reading image: ./images/reference_images/ClaireDunphy/frantic-claire-modern-family-s11e17.jpg More than 2 faces detected in image, The face with the highest confidence will be used: ./images/reference_images/ClaireDunphy/frantic-claire-modern-family-s11e17.jpg Reading image: ./images/reference_images/ClaireDunphy/ClaireDunphy.png Processing identity: GloriaPritchett Reading image: ./images/reference_images/GloriaPritchett/46623-1532336916.jpg Reading image: ./images/reference_images/GloriaPritchett/descarga.jpg Reading image: ./images/reference_images/GloriaPritchett/GloriaPritchett.png Processing identity: LukeDunphy Reading image: ./images/reference_images/LukeDunphy/descarga (1).jpg Reading image: ./images/reference_images/LukeDunphy/descarga (3).jpg Reading image: ./images/reference_images/LukeDunphy/descarga.jpg Reading image: ./images/reference_images/LukeDunphy/LukeDunphy.png
-------------------
ReferenceEmbeddings
-------------------
Number of identities: 13
Number of images per identity: {'JayPritchett': 2, 'AlexDunphy': 3, 'CameronTucker': 2, 'JoePritchett': 5, 'MitchellPritchett': 3, 'HaleyDunphy': 4, 'PhilDunphy': 4, 'JoaquinAmat': 1, 'MannyDelgado': 6, 'LilyTucker-Pritchett': 4, 'ClaireDunphy': 3, 'GloriaPritchett': 3, 'LukeDunphy': 4}
Source folder: ./images/reference_images
Save path: None
Device: None
Minimum face size: 20
Detection thresholds: [0.6, 0.7, 0.7]
Minimum confidence for detection: 0.5
Verbose: True
Una vez creados los embeddings de referencia, estos se pueden cargar en la clase FaceDetector para realizar el reconocimiento facial en nuevas imágenes utilizando el método load_reference_embeddings. Luego, se puede utilizar el método identify_faces para detectar y reconocer caras en nuevas imágenes.
# Cargar los embeddings de referencia en el detector de caras
# ==============================================================================
face_detector.load_reference_embeddings(reference_embeddings)
# Detectar y reconocer caras en una imagen
# ==============================================================================
identities, similarities = face_detector.identify_faces(embeddings=embeddings)
print(f"Identidades: {identities}")
print(f"Similitudes: {similarities}")
---------------- Identified faces ---------------- Face 0: Identity: JayPritchett, Similarity: 0.69 Face 1: Identity: PhilDunphy, Similarity: 0.92 Face 2: Identity: CameronTucker, Similarity: 0.80 Face 3: Identity: MannyDelgado, Similarity: 0.87 Face 4: Identity: HaleyDunphy, Similarity: 0.75 Face 5: Identity: ClaireDunphy, Similarity: 0.78 Face 6: Identity: MitchellPritchett, Similarity: 0.61 Face 7: Identity: AlexDunphy, Similarity: 0.62 Face 8: Identity: GloriaPritchett, Similarity: 0.68 Face 9: Identity: LukeDunphy, Similarity: 0.79 Face 10: Identity: LilyTucker-Pritchett, Similarity: 0.80 Face 11: Identity: JoePritchett, Similarity: 0.77 Identidades: ['JayPritchett', 'PhilDunphy', 'CameronTucker', 'MannyDelgado', 'HaleyDunphy', 'ClaireDunphy', 'MitchellPritchett', 'AlexDunphy', 'GloriaPritchett', 'LukeDunphy', 'LilyTucker-Pritchett', 'JoePritchett'] Similitudes: [0.6871325969696045, 0.9191560745239258, 0.7987002730369568, 0.874779462814331, 0.746529757976532, 0.7806506752967834, 0.6057980060577393, 0.6189405918121338, 0.6765539646148682, 0.7890835404396057, 0.7986713647842407, 0.7654215693473816]
Tambien es posible detectar, identificar y trazar las cajas delimitadoras de las caras reconocidas en un solo paso utilizando el método detect_and_identify_faces.
face_detector.detect_and_identify_faces(image=image_2)
---------------- Scanned image ---------------- Detected faces: 12 Detected faces with minimum confidence: 12 Bounding box correction applied: True Bounding box coordinates: [[293, 64, 402, 194], [505, 89, 605, 224], [108, 95, 210, 227], [427, 207, 529, 333], [47, 235, 145, 361], [1069, 134, 1165, 262], [682, 126, 778, 248], [659, 291, 750, 402], [886, 128, 968, 250], [239, 245, 326, 355], [931, 496, 1012, 613], [816, 663, 889, 751]] Bounding box confidence: [0.9999438524246216, 0.9982789754867554, 0.999267041683197, 0.9998809099197388, 0.9999357461929321, 0.9999068975448608, 0.9999818801879883, 0.9996474981307983, 0.9995021820068359, 0.9993504881858826, 0.9991905093193054, 0.9989155530929565] ---------------- Identified faces ---------------- Face 0: Identity: JayPritchett, Similarity: 0.68 Face 1: Identity: PhilDunphy, Similarity: 0.92 Face 2: Identity: CameronTucker, Similarity: 0.80 Face 3: Identity: MannyDelgado, Similarity: 0.88 Face 4: Identity: HaleyDunphy, Similarity: 0.74 Face 5: Identity: ClaireDunphy, Similarity: 0.77 Face 6: Identity: MitchellPritchett, Similarity: 0.61 Face 7: Identity: AlexDunphy, Similarity: 0.63 Face 8: Identity: GloriaPritchett, Similarity: 0.67 Face 9: Identity: LukeDunphy, Similarity: 0.79 Face 10: Identity: LilyTucker-Pritchett, Similarity: 0.80 Face 11: Identity: JoePritchett, Similarity: 0.76

Pipeline para la detección y el reconocimiento facial¶
Todos los pasos descritos anteriormente se pueden combinar en un solo pipeline para el reconocimiento facial en imágenes, vídeos o flujos de vídeo en tiempo real.
Pipeline para reconocimiento en imágenes¶
# Crear embeddings de referencia a partir de una carpeta de imágenes
# ==============================================================================
reference_embeddings = ReferenceEmbeddings(
folder_path ='./images/reference_images',
verbose = False
)
reference_embeddings.calculate_reference_embeddings()
reference_embeddings
-------------------
ReferenceEmbeddings
-------------------
Number of identities: 13
Number of images per identity: {'JayPritchett': 2, 'AlexDunphy': 3, 'CameronTucker': 2, 'JoePritchett': 5, 'MitchellPritchett': 3, 'HaleyDunphy': 4, 'PhilDunphy': 4, 'JoaquinAmat': 1, 'MannyDelgado': 6, 'LilyTucker-Pritchett': 4, 'ClaireDunphy': 3, 'GloriaPritchett': 3, 'LukeDunphy': 4}
Source folder: ./images/reference_images
Save path: None
Device: None
Minimum face size: 20
Detection thresholds: [0.6, 0.7, 0.7]
Minimum confidence for detection: 0.5
Verbose: False
# Carga de los embeddings de referencia en el detector de caras
# ==============================================================================
face_detector.load_reference_embeddings(reference_embeddings)
# Detección y reconocimiento de caras en una imagen
# ==============================================================================
face_detector.detect_and_identify_faces(image=image_2)
---------------- Scanned image ---------------- Detected faces: 12 Detected faces with minimum confidence: 12 Bounding box correction applied: True Bounding box coordinates: [[293, 64, 402, 194], [505, 89, 605, 224], [108, 95, 210, 227], [427, 207, 529, 333], [47, 235, 145, 361], [1069, 134, 1165, 262], [682, 126, 778, 248], [659, 291, 750, 402], [886, 128, 968, 250], [239, 245, 326, 355], [931, 496, 1012, 613], [816, 663, 889, 751]] Bounding box confidence: [0.9999438524246216, 0.9982789754867554, 0.999267041683197, 0.9998809099197388, 0.9999357461929321, 0.9999068975448608, 0.9999818801879883, 0.9996474981307983, 0.9995021820068359, 0.9993504881858826, 0.9991905093193054, 0.9989155530929565] ---------------- Identified faces ---------------- Face 0: Identity: JayPritchett, Similarity: 0.68 Face 1: Identity: PhilDunphy, Similarity: 0.92 Face 2: Identity: CameronTucker, Similarity: 0.80 Face 3: Identity: MannyDelgado, Similarity: 0.88 Face 4: Identity: HaleyDunphy, Similarity: 0.74 Face 5: Identity: ClaireDunphy, Similarity: 0.77 Face 6: Identity: MitchellPritchett, Similarity: 0.61 Face 7: Identity: AlexDunphy, Similarity: 0.63 Face 8: Identity: GloriaPritchett, Similarity: 0.67 Face 9: Identity: LukeDunphy, Similarity: 0.79 Face 10: Identity: LilyTucker-Pritchett, Similarity: 0.80 Face 11: Identity: JoePritchett, Similarity: 0.76
Pipeline para reconocimiento en videos¶
Procesar vídeos requiere manejar cada uno de sus fotogramas, lo que lo hace computacionalmente intensivo. Se recomienda utilizar GPUs. El vídeo utilizado para este ejemplo se puede descargar desde el siguiente enlace.
# Detección y reconocimiento de caras en un video
# ==============================================================================
face_detector.detect_and_identify_faces_video(
video_path = './videos/video_modern_family.mp4',
output_path = './videos/output_test.mp4'
)

Pipeline para reconocimiento en webcam (streaming en tiempo real)¶
El argumento capture_index especifica qué cámara utilizar (0 para la cámara predeterminada, 1 para una cámara externa, etc.). El argumento skip_frames permite omitir un cierto número de fotogramas entre cada paso de procesamiento para mejorar el rendimiento. El argumento show indica si se debe mostrar el vídeo con las caras detectadas e identificadas en tiempo real.
# Detección y reconocimiento de caras en webcam (streaming en tiempo real)
# ==============================================================================
face_detector.detect_and_identify_faces_webcam(
capture_index = 0, # cambiar a 1 o 2 si tienes una cámara externa
skip_frames = 2,
show = True
)
Informacion de sesión¶
import session_info
session_info.show(html=False)
----- PIL 12.0.0 cv2 4.12.0 matplotlib 3.10.7 numpy 2.2.6 openfacekit 0.2.0 scipy 1.16.3 session_info v1.0.1 torch 2.7.1+cu126 ----- IPython 9.6.0 jupyter_client 8.6.3 jupyter_core 5.9.1 ----- Python 3.12.12 | packaged by conda-forge | (main, Oct 22 2025, 23:25:55) [GCC 14.3.0] Linux-6.14.0-34-generic-x86_64-with-glibc2.39 ----- Session information updated at 2025-11-04 17:09
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Detección y reconocimiento facial con Python y Deep Learning por Joaquín Amat Rodrigo, disponible con licencia CC BY-NC-SA 4.0 en https://www.cienciadedatos.net/documentos/py34-reconocimiento-facial-deeplearning-python.html
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊



Este documento creado por Joaquín Amat Rodrigo tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.